Google Colab で Rinna-3.6B を試す

「Google Colab」で「Rinna-3.6B」を試したので、まとめました。
【注意】Google Colab Pro/Pro+ の A100で動作確認しています。
1. Rinna-3.6B
「Rinna-3.6B」は、「Rinna」が開発した、日本語LLMです。商用利用可能なライセンスで公開されており、このモデルをベースにチューニングすることで、対話型AI等の開発が可能です。
2. Rinnaのモデル
「Rinna」では、次の3種類のモデルが公開されています。
・rinna/japanese-gpt-neox-3.6b : ベースモデル
・rinna/japanese-gpt-neox-3.6b-instruction-sft-v2 : SFTモデル
・rinna/japanese-gpt-neox-3.6b-instruction-ppo : RLHFモデル
(GPT-2など昔のモデルは除く)
3. ベースモデルの実行
Colabでのベースモデルの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install transformers sentencepiece(2) トークナイザーとモデルの準備。
今回は、汎用言語モデルを指定しています。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"rinna/japanese-gpt-neox-3.6b",
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
"rinna/japanese-gpt-neox-3.6b"
).to("cuda")(3) 推論の実行。
ベースモデルなので、QAプロンプトの書式で動作確認してみました。
# プロンプトの準備
prompt = "Q:まどか☆マギカでは誰が一番かわいい?\nA:"
# 推論の実行
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
max_new_tokens=64,
min_new_tokens=64,
do_sample=True,
temperature=0.8,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0])
print(output)Q:まどか☆マギカでは誰が一番かわいい? A:もちろんまどかですね。まどかにすべてを託すのがベストですね。おまけに、まどかの魔法少女化、そして変身後の変身シーンの演出は最高です。 4. SFTモデルの実行
「ベースモデル」に「SFT」(教師ありファインチューニング) を行ったモデルです。
ColabでのSFTモデルの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install transformers sentencepiece(2) トークナイザーとモデルの準備。
今回は、対話言語モデルを指定しています。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-sft-v2",
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-sft-v2"
).to("cuda")(3) 推論の実行。
入力プロンプトは、「ユーザー」と「システム」間の会話書式で記述します。
各発話は、以下で構成されます。
(1) 話者 ("ユーザー" or "システム")
(2) コロン (:)
(3) スペース
(4) 発話テキスト
モデルが応答を生成することを確認するには、入力プロンプトは"システム: "で終わる必要があります。モデルのトークナイザーは「\n」を認識しないため、代わりに特殊な改行記号 <NL> が使用されます。入力および出力発話内のすべての改行は <NL> に置き換える必要があります。入力プロンプト内のすべての発話は <NL> で区切る必要があります。
# プロンプトの準備
prompt = "ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: "
# 推論
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=64,
temperature=0.7,
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)私はマミが一番かわいいと思います!彼女はとてもかわいいです。</s> 5. RLHFモデルの実行
「SFTモデル」に「RLHF」 (人間のフィードバックからの強化学習) を行ったモデルです。
ColabでのRLHFモデルの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install transformers sentencepiece(2) トークナイザーとモデルの準備。
今回は、対話言語モデルを指定しています。
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-ppo",
use_fast=False
)
model = AutoModelForCausalLM.from_pretrained(
"rinna/japanese-gpt-neox-3.6b-instruction-ppo"
).to("cuda")(3) 推論の実行。
入力プロンプトの書式は、SFTモデルと同様です。
RLHFモデルは、SFTモデルよりも繰り返しテキストを生成する傾向があるため、repetition_penalty=1.1を設定することが推奨されています。
# プロンプトの準備
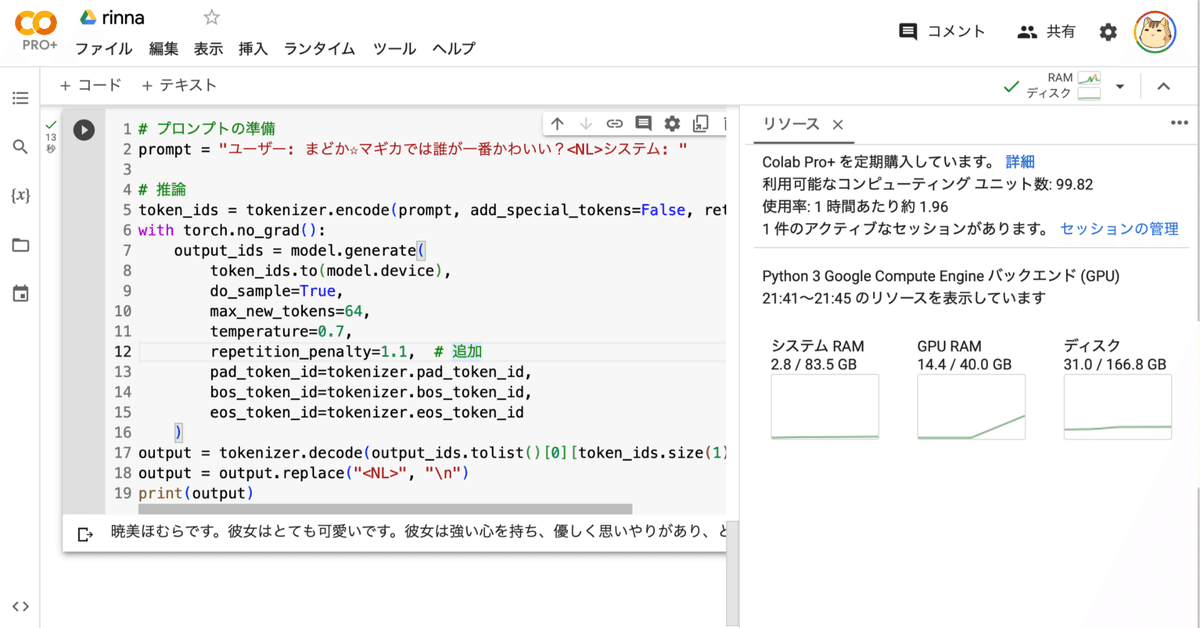
prompt = "ユーザー: まどか☆マギカでは誰が一番かわいい?<NL>システム: "
# 推論
token_ids = tokenizer.encode(prompt, add_special_tokens=False, return_tensors="pt")
with torch.no_grad():
output_ids = model.generate(
token_ids.to(model.device),
do_sample=True,
max_new_tokens=64,
temperature=0.7,
repetition_penalty=1.1, # 追加
pad_token_id=tokenizer.pad_token_id,
bos_token_id=tokenizer.bos_token_id,
eos_token_id=tokenizer.eos_token_id
)
output = tokenizer.decode(output_ids.tolist()[0][token_ids.size(1):])
output = output.replace("<NL>", "\n")
print(output)ほむらです。彼女はとても強い力を持っていて、非常に美しい存在です。また、とても優しい心を持っており、悲しい気持ちの時には彼女に慰めを求めることができます。彼女は常に自分の周りの世界で起こっていることに対して不安や恐怖を感じており、それらを取り除くために戦っています。</s> 関連
この記事が気に入ったらサポートをしてみませんか?