
toio と Unity ML-Agents ではじめるロボットの強化学習 (1) - 事始め

「toio」と「Unity ML-Agents」 を使って、シミュレータ内で強化学習したAIの実環境のロボットへの適用に挑戦してみます。
【最新版の情報は以下で紹介】
・Unity 2019.4.5f1
・UniTask 2.0
・toio SDK for Unity v1.0.2
・Xcode 12.1
・Unity ML-Agents Release 9
1. toioとUnity ML-Agents
「toio」はSonyのトイロボットです。絶対位置をリアルタイムで正確に検出できるのが特徴になります。シミュレーション機能も備えた、Unityベースの開発ツール「toio SDK for Unity」も提供されています。
「Unity ML-Agents」はUnityが提供する強化学習フレームワークです。強化学習に加えて、模倣学習、カリキュラム学習、セルフプレイなど、様々なAIの学習法を提供しています。
これらを使って、シミュレータ内で強化学習したAIの実環境のロボットへの適用に挑戦してみます。
2. 学習環境の概要
「プレイヤー」(赤キューブ)が「ターゲット」(青キューブ)まで移動することを学習する学習環境を作成します。

強化環境の要素は、次のとおりです。
・観察
・Raycast Observation x 1
・行動
・Discrete (サイズ4)
0: 前進
1: 左回転
2: 右回転
3: なし
・報酬 :
・プレイヤーがターゲットの位置に到着 : +1.0 (エピソード完了)
・プレイヤートが落下 : +0.0 (エピソード完了)
・決定
・5フレーム毎「Raycast Observation」では、プレイヤーの周囲にレイ(光線)を飛ばした時のターゲットとの交差判定と距離を「観察」として利用します。
3. 学習環境の作成
(1) Unityのプロジェクトを作成し、「toio SDK for Unity」と「Unity ML-Agents」をインストール。
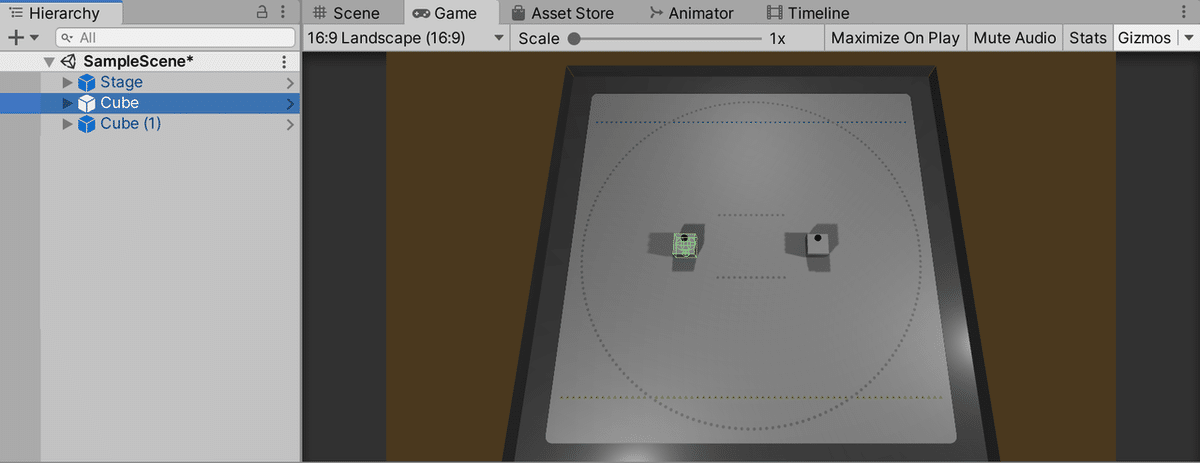
(2) 「toio SDK for Unity」で「Stage」1つと「Cube」2つを配置。
「Cube」の位置は、(-0.1, 0.0, 0.0)と(0.1, 0.0, 0.0)にしました。
4. 強化学習用のキューブの追加
先程配置した「Cube」はシミュレータで使うキューブになります。強化学習用に、「プレイヤーキューブ」と「ターゲットキューブ」を準備します。

◎ プレイヤーキューブ
(1) Hierarchyウィンドウで「+ → Empty Object」で空のゲームオブジェクトを追加し、「PlayerCube」と名前を指定。
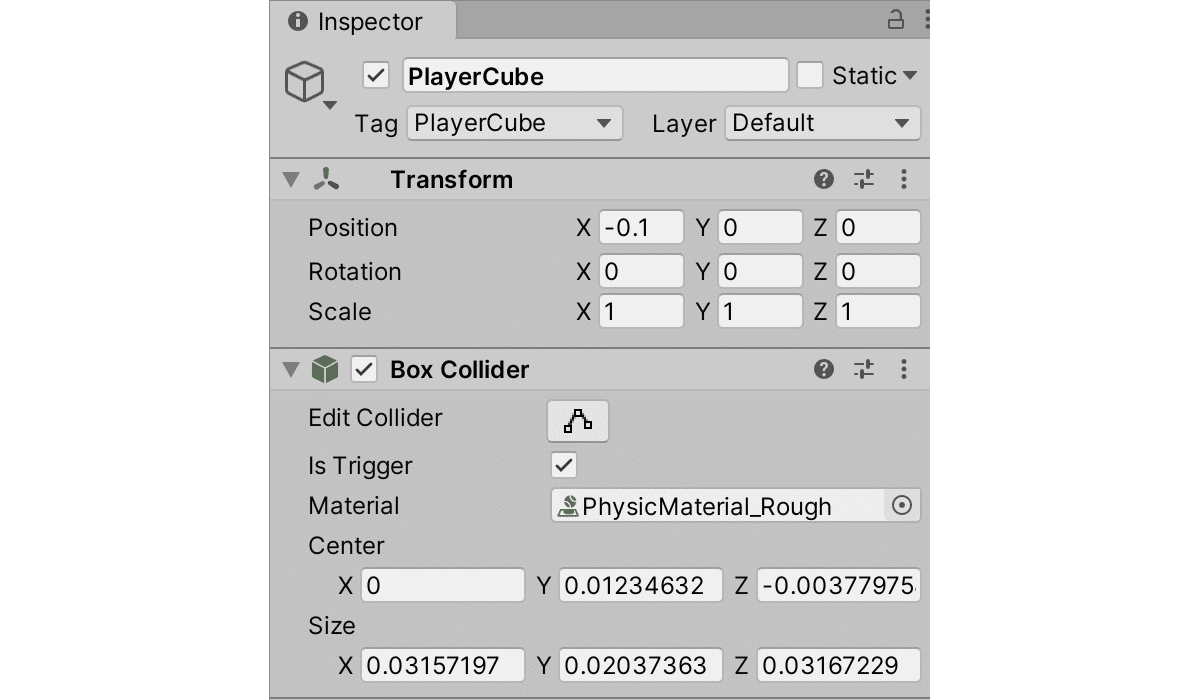
(2) Hierarchyウィンドウで「PlayerCube」を選択し、Inspectorで以下のように設定。
Tagに新規タグ「PlayerCube」を指定し、「Cube」((1)でない方)からTransformとBoxColliderをコピーして、「Is Trigger」をチェックします。
◎ ターゲットキューブ
(1) Hierarchyウィンドウで「+ → Empty Object」で空のゲームオブジェクトを追加し、「TargetCube」と名前を指定。
(2) Hierarchyウィンドウで「TargetCube」を選択し、Inspectorで以下のように設定。
Tagに新規タグ「TargetCube」を指定し、Layerに新規レイヤー「Target」を指定し、「Cube (1)」からTransformとBoxColliderをコピーして、「Is Trigger」をチェックします。

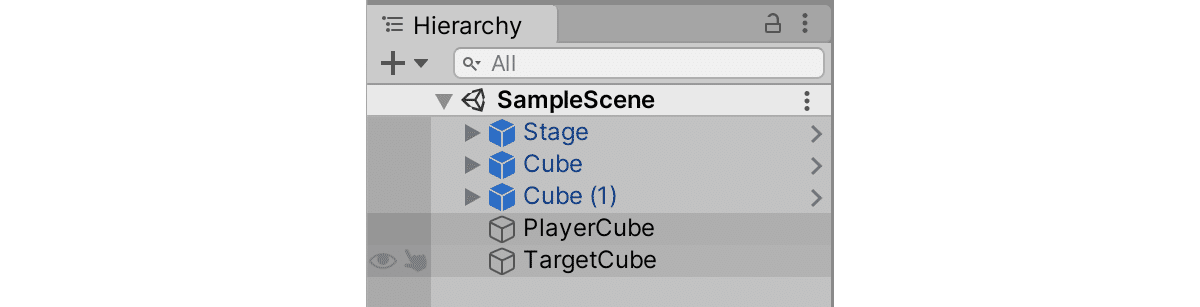
Hierarchyウィンドウは、次のようになります。
5. Unity ML-Agentsのコンポーネントの追加
「PlayerCube」に「Unity ML-Agentsのコンポーネント」を追加します。
・Behavior Parameters
・PlayerCube (Agentクラスを継承したスクリプト)
・Decision Requester
・RayPerceptionSensor3D
◎ BehaviorParametersの追加
(1) Hierarchyウィンドウで「PlayerCube」を選択し、「Add Component」で「BehaviorParameters」を追加。
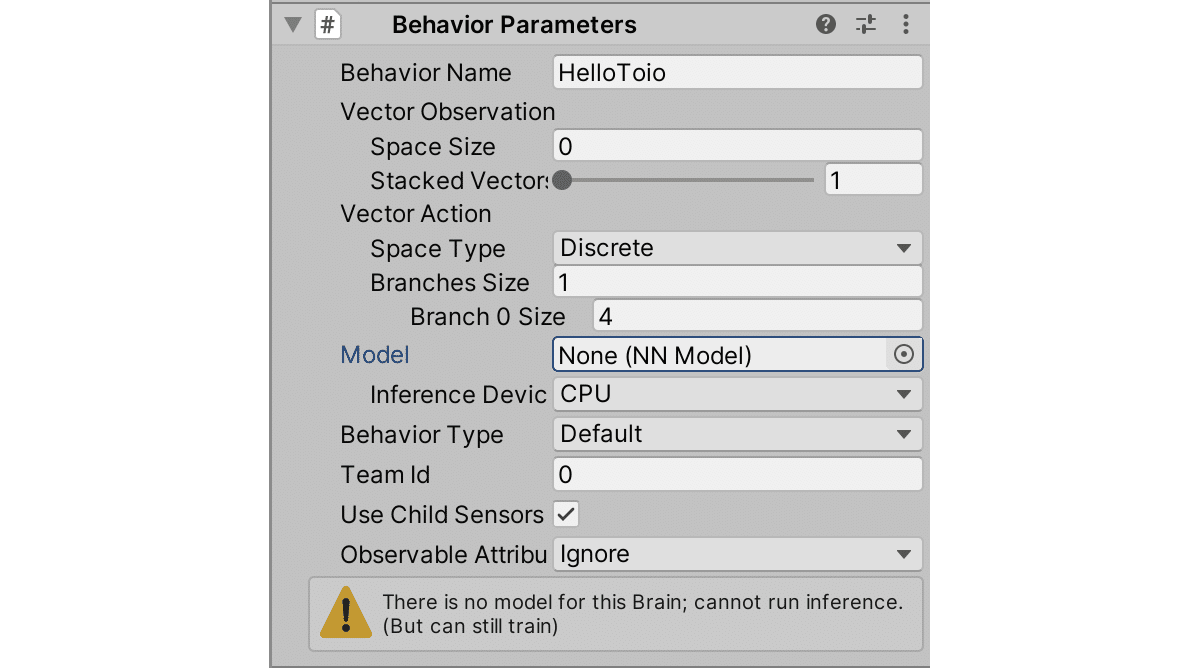
(2) 「BehaviorParameters」を以下のように設定。
・Behavior Name : HelloToio
・Vector Observation - Space Size : 0
・Vector Action - Space Type : Discrete
・Vector Action - Branches Size : 1
・Vector Action Branch 0 Size : 4
◎ PlayerCubeの追加
(1) Hierarchyウィンドウで「PlayerCube」を選択し、「Add Component」で新規スクリプト「PlayerCube」を追加し、以下のように編集。
using System.Collections.Generic;
using UnityEngine;
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using toio;
using toio.Simulator;
public class PlayerCube : Agent
{
CubeManager cubeManager; // キューブマネージャ
CubeHandle playerHandle; // プレイヤーハンドル
CubeHandle targetHandle; // ターゲットハンドル
GameObject playerCube; // プレイヤーキューブ
GameObject targetCube; // ターゲットキューブ
bool initFlag = false; // 初期化フラグ
// 初期化時に呼ばれる
public async override void Initialize()
{
// キューブの複数台接続
cubeManager = new CubeManager();
await cubeManager.MultiConnect(2);
// 参照の取得
this.playerHandle = cubeManager.handles[0];
this.targetHandle = cubeManager.handles[1];
this.playerCube = GameObject.FindGameObjectWithTag("PlayerCube");
this.targetCube = GameObject.FindGameObjectWithTag("TargetCube");
// LED色の指定
this.playerHandle.cube.TurnLedOn(255, 0, 0, 0);
this.targetHandle.cube.TurnLedOn(0, 0, 255, 0);
// 初期化フラグ
this.initFlag = true;
}
// フレーム毎に呼ばれる
public void FixedUpdate()
{
// 初期化前
if (!this.initFlag) return;
// プレイヤーキューブの同期
this.playerCube.transform.localPosition = new Vector3(
(float)(this.playerHandle.cube.x-250f)/(191f/0.26f), 0f,
-(float)(this.playerHandle.cube.y-250f)/(191f/0.26f));
this.playerCube.transform.localRotation = Quaternion.Euler(
0f, (float)this.playerHandle.deg+90f, 0f);
// ターゲットキューブの同期
this.targetCube.transform.localPosition = new Vector3(
(float)(this.targetHandle.cube.x-250f)/(191f/0.26f), 0f,
-(float)(this.targetHandle.cube.y-250f)/(191f/0.26f));
this.targetCube.transform.localRotation = Quaternion.Euler(
0f, (float)this.targetHandle.deg+90f, 0f);
}
// エピソード開始時に呼ばれる
public override void OnEpisodeBegin()
{
// 初期化前
if (!this.initFlag) return;
#if (UNITY_EDITOR || UNITY_STANDALONE)
// キューブの位置のリセット (学習時のみ)
GameObject[] cubes = GameObject.FindGameObjectsWithTag("Cube");
while (true)
{
foreach (GameObject cube in cubes)
{
cube.transform.localPosition = new Vector3(
Random.Range(-0.2f, 0.2f), 0.0f, Random.Range(-0.2f, 0.2f));
cube.transform.localRotation = Quaternion.Euler(
0f, Random.Range(0f, 360f), 0f);
}
if (Vector3.Distance(cubes[0].transform.localPosition,
cubes[1].transform.localPosition) > 0.1f)
{
break;
}
}
#endif
}
// 行動実行時に呼ばれる
public override void OnActionReceived(float[] vectorAction)
{
// 初期化前 or 操作不可
if (!this.initFlag ||
!this.cubeManager.IsControllable(this.playerHandle)) return;
// プレイヤーの移動
int action = (int)vectorAction[0];
this.playerHandle.Update();
if (action == 0)
{
this.playerHandle.Move(100, 0, 100, border:false);
}
else if (action == 1)
{
this.playerHandle.Move(0, -50, 100, border:false);
}
else if (action == 2)
{
this.playerHandle.Move(0, 50, 100, border:false);
}
else
{
this.playerHandle.Move(0, 0, 100, border:false);
}
// プレイヤーがターゲットの位置に到着した時
float distanceToTarget = Vector2.Distance(playerHandle.cube.pos, targetHandle.cube.pos);
if (distanceToTarget < 30f)
{
AddReward(1.0f);
EndEpisode();
}
// プレイヤーがプレイマットから落下した時
if (this.playerHandle.cube.x <= 50 || 450 < this.playerHandle.cube.x ||
this.playerHandle.cube.y <= 50 || 450 < this.playerHandle.cube.y)
{
EndEpisode();
}
}
// ヒューリスティックモードの行動決定時に呼ばれる
public override void Heuristic(float[] actionsOut)
{
double h = Input.GetAxis("Horizontal");
double v = Input.GetAxis("Vertical");
int action = 3;
if (v > 0)
{
action = 0;
}
else if (h < 0)
{
action = 1;
}
else if (h > 0)
{
action = 2;
}
actionsOut[0] = action;
}
}・プレイヤーキューブとターゲットキューブの同期
FixedUpdate()では、実環境(またはシミュレータ)のキューブのXY座標と角度をプレイヤーキューブとターゲットキューブに同期しています。
・キューブの位置のリセット
OnEpisodeBegin()では、キューブの位置のリセットを行っています。これはシミュレータでのみの機能になります。実環境では、手作業で移動させてください。
◎ Decision Requesterの追加
(1) Hierarchyウィンドウで「PlayerCube」を選択し、「Add Component」で「DecisionRequester」を追加。
(2) 「DecisionRequester」を以下のように設定。
・Decision Period : 5
・Take Action Between Decisions : チェックなし

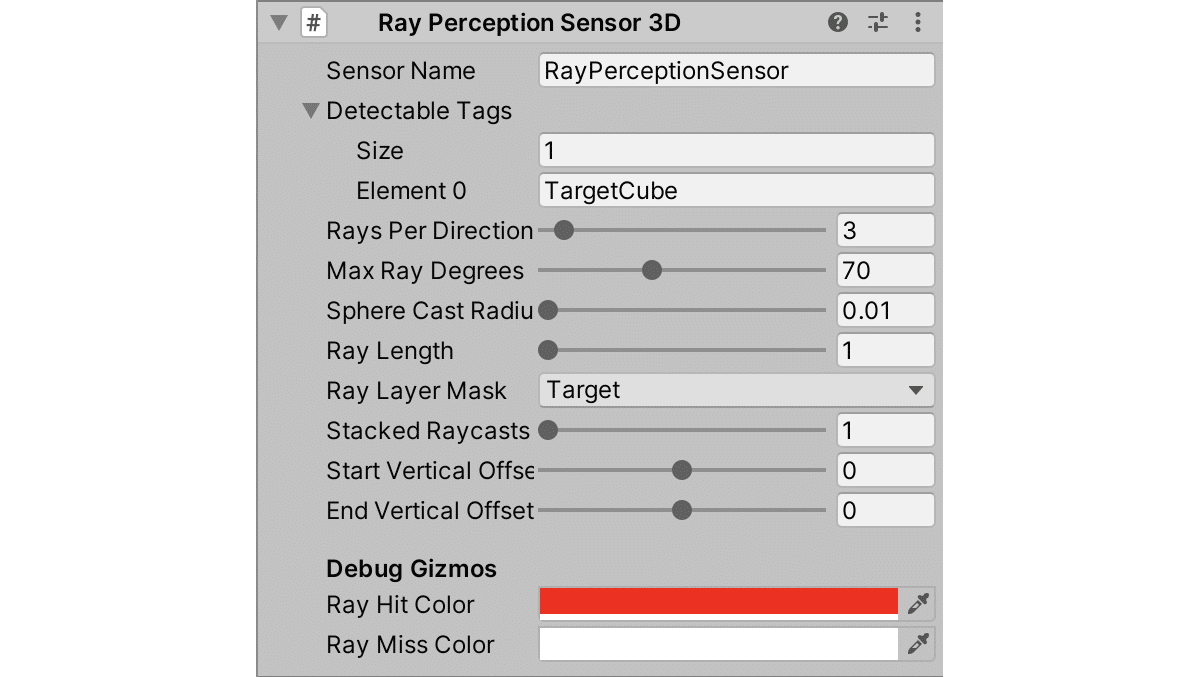
◎ RayPerceptionSensor3D
(1) Hierarchyウィンドウで「PlayerCube」を選択し、「Add Component」で「RayPerceptionSensor3D」を追加。
(2) 「RayPerceptionSensor3D」を以下のように設定。
・DetectableTags - Size : 1
・DetectableTags - Element 0 TargetCube
・Sphere Cast Radius : 0.01
・Ray Length : 1
・Ray Layer Mask : Target
6. 訓練設定ファイル
訓練設定ファイルは、次のとおりです。「<ml-agentsのルート>/config/sample/HelloToio.yaml」に配置します。
behaviors:
HelloToio:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0003
beta: 0.005
epsilon: 0.2
lambd: 0.95
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: true
hidden_units: 128
num_layers: 2
vis_encode_type: simple
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
keep_checkpoints: 5
checkpoint_interval: 500000
max_steps: 500000
time_horizon: 64
summary_freq: 1000
threaded: true7. 学習
Unityエディタ上で学習します。高速に学習を回すとキューブへ送る命令が間に合わないので「--time-scale=1」を指定しています。
ターミナル(コマンドプロンプト)で以下のコマンドを実行後、UnityエディタでPlayボタンを押します。
$ mlagents-learn config/sample/HelloToio.yaml --run-id=HelloToio-ppo-1 --time-scale=132000ステップ程度で平均報酬1.0になりました。
HelloToio. Step: 24000. Time Elapsed: 747.720 s. Mean Reward: 0.571. Std of Reward: 0.495. Training.
HelloToio. Step: 25000. Time Elapsed: 778.414 s. Mean Reward: 0.556. Std of Reward: 0.497. Training.
HelloToio. Step: 26000. Time Elapsed: 807.710 s. Mean Reward: 0.667. Std of Reward: 0.471. Training.
HelloToio. Step: 27000. Time Elapsed: 837.442 s. Mean Reward: 0.733. Std of Reward: 0.442. Training.
HelloToio. Step: 28000. Time Elapsed: 868.200 s. Mean Reward: 0.812. Std of Reward: 0.390. Training.
HelloToio. Step: 29000. Time Elapsed: 899.264 s. Mean Reward: 0.667. Std of Reward: 0.471. Training.
HelloToio. Step: 30000. Time Elapsed: 929.298 s. Mean Reward: 0.857. Std of Reward: 0.350. Training.
HelloToio. Step: 31000. Time Elapsed: 957.610 s. Mean Reward: 0.769. Std of Reward: 0.421. Training.
HelloToio. Step: 32000. Time Elapsed: 988.988 s. Mean Reward: 1.000. Std of Reward: 0.000. Training.TensorBoardを確認すると、平均報酬は次のようになっています。
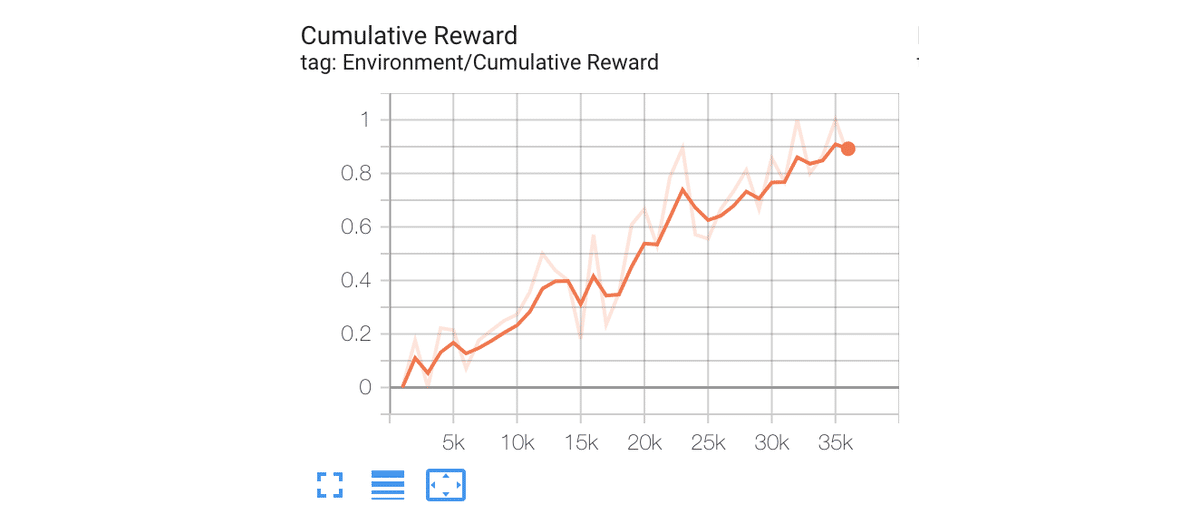
「<ml-agentsのルート>/results/HelloToio-ppo-1/HelloToio.nn」にモデルが出力されます。
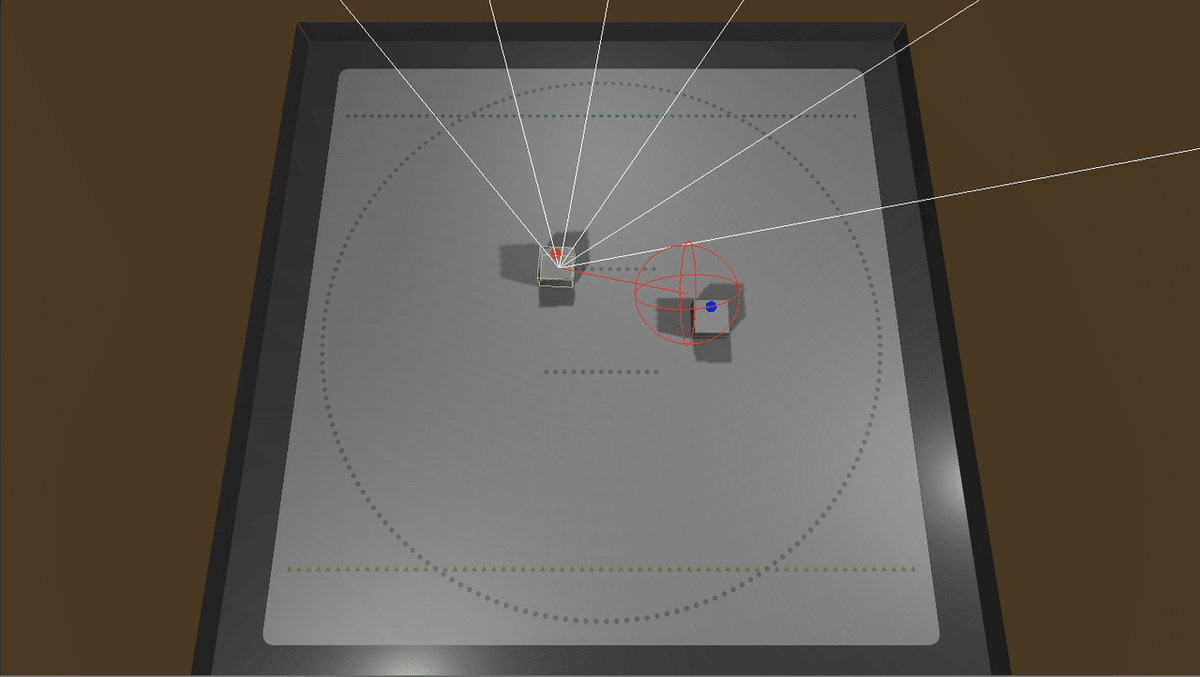
8. シミュレータでの実行
(1) 生成したモデル(HelloToio.nn)をプロジェクトのAssetsにドラッグ&ドロップ。
(2) BehaviorParametersのModelに生成したモデルをドラッグ&ドロップ。
(3) Playボタンで実行。
9. 実環境での実行
(1) 実環境のプレイマットと2つのキューブ(電源を入れる)を準備。
(2) iOSアプリとしてビルドして実行。

赤キューブが周りを見回しながら、青キューブまでたどり着きます。たどり着いたら、手動で位置を変えると再び移動しはじめます。
次回
この記事が気に入ったらサポートをしてみませんか?