
Kaolin 入門 (2) - 2D画像から3Dモデルへの変換

以下の記事を参考にして書いてます。
・How to turn 2D photos into a 3D model using Nvidia Kaolin and PyTorch
前回
1. はじめに
「GANverse3D」に関する私の記事を読んだことがあれば、おそらく、「DIB-R」の論文について聞いたことがあるでしょう。これは、2019年からの3D深層学習の重要な論文でした。
「DIB-R」の論文は、深層学習で現在最もファッショナブルな問題の1つを解決するツールとして、改良された微分可能レンダラーを紹介しています。これは、2D画像から3Dモデルを生成します。
2019年に「DIB-R」の論文が発表された時、ソースコードも含まれていました。しかし残念ながら、そのコードを実行するために必要な、機械学習モデルが含まれていませんでした。これは非常に残念でした。
幸いなことに、「Nvidia」は、「DIB-R」の論文で使用されたものと同じ微分可能レンダラーを含む「Kaolinライブラリ」をリリースしたため、「DIB-R」を直接試せるようになりました。このライブラリには、「DIB-Rチュートリアル」も含まれています。
私は、チュートリアルを最初に見た時、それをあまり理解していなかったことを告白しなければなりません。そもそも、なぜ微分可能レンダラーが必要なのかさえわかりませんでした。また、微分可能レンダラーを、2D画像から3Dモデルを生成できる「DIB-R」の論文で説明されているものと混同しました。
それらは実際には、別々のものです。
そこで、この記事では、「DIB-Rチュートリアル」を試す方法を、段階的に説明します。また、「DIB-R」と3D深層学習の分野について学んだことを共有します。
2. Kaolin
「Kaolin」には、2つの主要コンポーネントがあります。
◎ Omniverse Kaolin App
Nvidiaによって作成されたアプリで、3Dデータセットの視覚化ツール、合成データセットを生成する手段を提供します。3D深層学習の研究を支援し、学習中にモデルによって生成された3D出力を視覚化する機能も備えています。
◎ Kaolin Library
点群、メッシュ、ボクセルグリッドなど、さまざまな3D表現と、ある表現から別の表現への変換を可能にする関数(kaolin.ops)を提供します。このライブラリには、「DIB-R」、「微分可能レンダラー」(kaolin.render)、Shapenetなどの3Dデータセットからデータをロードする関数、objやusdなどの3Dモデルをロードする関数(kaolin.io)、3Dチェックポイント(kaolin.visualize)を作成する関数も含まれています。
3. 実行環境の準備
「DIB-Rチュートリアル」の実行環境の準備を行います。
実行に必要なマシンおよびソフトウェアは、次のとおりです。
・Nvidia GPU
・Windows or Linux
・Python 3.7
・Pytorch 1.7.0
・CUDA 11.2以降
・Kaolin Library
・Omniverse Launcher
実行環境の準備の手順は、次のとおりです。
(1) AnacondaでPythonの仮想環境を作成。
$ conda create --name kaolin python=3.7
$ conda activate kaolin「Anaconda」を利用すると、複数のPythonのバージョンを簡単にインストールできます。さらに、ライブラリの互換性の問題を大幅に減らすことができます。
(2) Kaolinのクローン。
$ git clone --recursive https://github.com/NVIDIAGameWorks/kaolin
$ cd kaolinKaolinの最新リリース(v0.9.0)にはまだ「DIB-Rチュートリアル」が含まれていません。そこで、masterブランチからセットアップします。
(3) Pytorch 1.7.1のインストール。
$ conda install pytorch==1.7.1 torchvision==0.8.2 torchaudio==0.7.2 -c pytorch4. Kaolinアプリの準備
「DIB-Rチュートリアル」を実行する前に、厳密には必須ではありませんが、「Kaolinアプリ」をインストールすることをお勧めします。
「Kaolinアプリ」は、「DIB-R」が学習する3Dモデル(今回は時計)を視覚化するのに役立ちます。また、後でこのツールを使用して、キッチンデータセットから選択する別の3Dアセットの学習データを生成します。
Kaolinアプリのインストール手順は、次のとおりです。
(1) Omniverse Laucherのインストール。
詳細な手順は、以下の動画で紹介されています。
(2) Omniverse Launcherを起動し、「EXCHANGE」タブを選択。
(3) 「APPS」を選択し、「Kaolin」を検索し、Kaolinアプリをダウンロードしてインストール。
5. GanVerse3DとDIB-Rの関係
全てのコンポーネントがインストールできたので、「DIB-Rチュートリアル」を試す準備ができました。しかしその前に、「GanVerse3D」と「DIB-R」の論文がどのように関連しているかについて、簡単に説明します。
DIB-Rの論文の最初で、Nvidiaは「DIB-R」と呼ばれる改良された微分可能レンダラーの設計について説明しています。
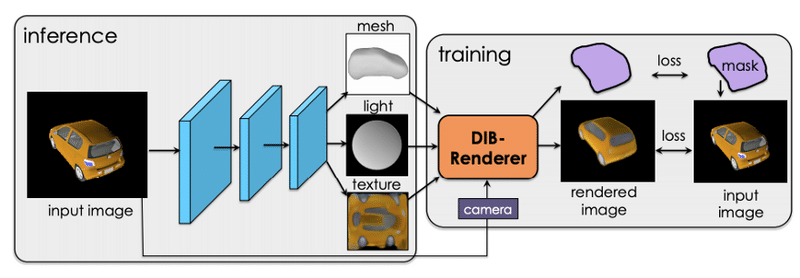
「DIB-R」の論文の第2部では、微分可能レンダラーである「DIB-R」を使用して、3D深層学習の難しい問題を解決する方法について説明しています。2D画像から3Dモデルの形状、テクスチャ、照明を予測できるモデルを学習します。モデルは「ShapeNet」および「CUB Bird」のデータセットで学習しています。

続く「GANVerse3D」の論文では、Nvidiaはさらに一歩進んでいます。「ShapeNet」の「CUB bird」のデータセットを使う代わりに、「StyleGAN-R」と「DatasetGAN」を使って生成したデータセットを使っています。
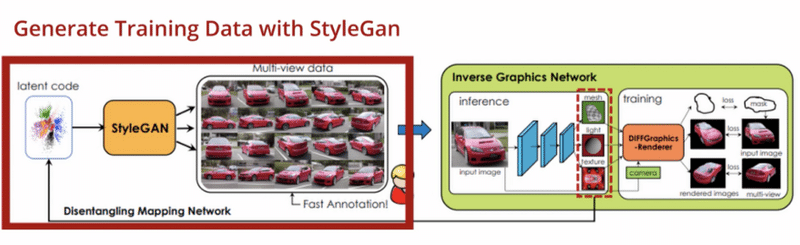
「StyleGAN-R」(StyleGANレンダラー)は、通常のStyleGANと基本的に同じですが、最初の4レイヤーがフリーズされおり、既知のカメラ位置の異なる視点で、同じオブジェクトの画像が生成される点が異なります。

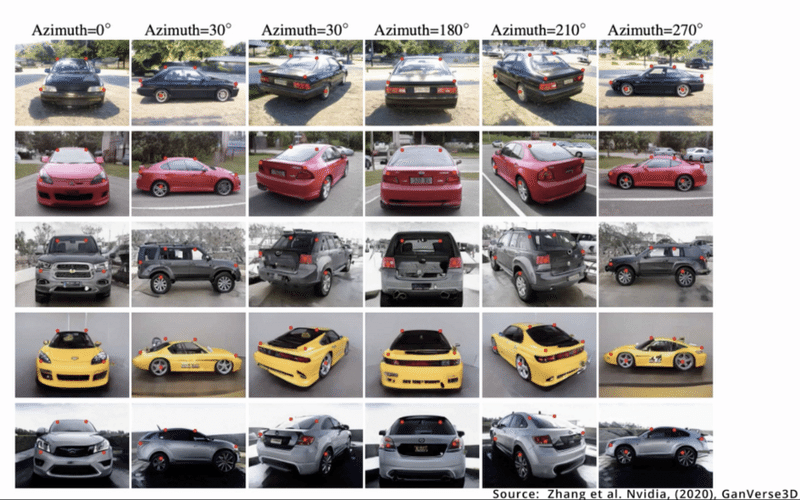
次に、「DatasetGAN」を使用して、生成された各画像にピクセルレベルまで自動的に注釈(セマンティックセグメンテーション)を付加します。
これにより、Nvidiaは、2D画像から変換された車などの3Dオブジェクトをアニメーションさせることができるのです。


6. DIB-Rチュートリアルの概要
「DIB-Rチュートリアル」は、DIB-R微分可能レンダラーがどのように機能するか、純粋な最適化問題として複数の2D画像から3Dモデルの構造とテクスチャを復元するために、どのように使用できるかを示しています。
しかし、重要なのはそこではありません。「DIB-R」の論文の第2部で説明されていた、ニューラルネットワークを使用して、単一の2D画像から3Dモデルを生成するチュートリアルではありません。後でコードを実行すると、ニューラルネットワークを使用していないことがわかります。
7. インバースグラフィックス
「DIB-Rチュートリアル」を理解するために、「DIB-R」の論文について少し詳しく説明する必要があります。
2D画像を元の3Dシーンに変換する問題は、従来のコンピュータグラフィックスの逆問題であるため、「インバースグラフィックス」と呼ばれています。
「OpenGL」や「DirectX」などの従来のレンダリングパイプラインは、レンダリングされる3Dシーンを復元できるように設計されていないため、言うのは簡単ですが、非常に困難です。これらのパイプラインは効率的に開発されており、多くの最適化が含まれているため、3Dシーン情報の一部が失われます。
8. 微分可能レンダラーはなぜ必要か
「微分可能レンダラー」とは何か、なぜそれが必要なのかについて話す価値があると思います。
このコンピュータービジョンの問題を自分たちで解決しよう想像してみてください。ただし、必ずしも機械学習では解決できません。
2D画像は3Dシーンの投影です。 3Dシーンは、カメラまたは視点から見た3Dメッシュ、頂点、面、テクスチャマップ、光源のコレクションです。簡単にするために、3Dシーンを単一の3Dオブジェクトに制限します。
2D画像を生成した元の3Dシーンを復元できた場合、2D画像の生成に使用したのと同じ視点を使用して、指定された3Dモデルを2Dに投影することで検証できるはずです。
◎ ブルートフォース(総当り)のアプローチ
3Dモデルを再構築するために、力ずくのアプローチは、頂点、面、光源、およびテクスチャのすべての可能な組み合わせを計算することです。これは、2Dに投影されたときに、入力として指定されたものと同等の画像を2Dで生成する必要があります。カメラの位置が同じである限り。これは本質的に検索の問題です。
しかし、ブルートフォースの問題は、作成できる頂点、面、テクスチャマップ、照明の膨大な数の組み合わせがあることです。
したがって、この問題から抜け出すために力ずくで対処することはできません。
◎ 勾配ベースのアプローチ
復元しようとしている3Dモデル(例えば時計)と位相的に似ている球体などの初期メッシュから始めて、この球体を時計に似せて成形するように変更してみるのはどうでしょうか。
さまざまなレベルで変更を加えることができます。
・頂点を移動して入力メッシュジオメトリを変更
・テクスチャの色を変更
・入力照明を変更
考えてみれば、それは3Dモデラーが行うことと似ています。彼らは常に、再構築しようとしている3Dモデルに類似したベースジオメトリを選択します。
重要な点は、球のジオメトリに変更を加えると、ジオメトリがターゲットジオメトリから収束または発散することを期待し、テクスチャと光源についても同じであるということです。
収束していることを確認するために、つまり、目標とする形状(この場合は時計)に近づいていることを確認するために、各ステップにおいて、入力された2D画像と同じような視点を使って、成形された球体を2Dに投影し、近づいていることを確認する必要があります。
◎ ラスタライズ問題
しかし、これには問題があります。3Dシーンから2Dに変換するには、グラフィックスレンダリングパイプラインを使用する必要があります。
従来のコンピューターグラフィックスパイプラインでは、ラスタライズ技術を使用して3Dシーンを2Dにレンダリングします。
3D画像を2D平面に投影し、三角形をラスター化し、ピクセルをシェーディングするプロセス中に、グラフィックパイプラインで使用されるアルゴリズムが原因で、情報が失われます。これらの損失の問題は、画像に不連続性が生じることです。
つまり、ジオメトリをわずかに変更しただけでは、まったくイメージが変わらないことがよくあるのです。さらに悪いことに、イメージが突然変わり、目標とする2D画像から遠く離れてしまうこともあります。
この2つの問題があるため、どの方向に向かって検索すれば良いのかわからないのです。そのため、2D画像から3Dシーンを復元することは、非常に困難なのです。
◎ 微分可能レンダラーのアプローチ
したがって、独自のレンダリングパイプライン「微分可能レンダラー」を設計する必要があります。
この新しいレンダリングパイプラインは、入力の3Dモデルの変更ごとに、投影された2D画像のピクセルの変更が保証され、この変更はすべてのピクセルで段階的に変更されることを保証します。
さらに、生成された各ピクセルには、各ピクセルの最終値に寄与する元の入力を決定するために使用できる導関数があります。
幸いなことに、車輪の再発明をする必要はありません。 DIB-Rは、私たちが利用できる「微分可能レンダラー」です。
9. DIB-R
「DIB-R」は、微分可能なラスタライズアルゴリズムを使用してピクセル値をモデル化する「微分可能レンダラー」です。 ピクセル値を割り当てる方法は2つあります。 1つは前景ピクセル用で、もう1つは背景ピクセル用です。
◎ 前景ピクセル
「前景ピクセル」の場合、論文は次のように述べています。
Here, in contrast to standard rendering, where a pixel’s value is assigned from the closest face that covers it, we treat foreground rasterization as an interpolation of vertex attributes[4]. For every foreground pixel we perform a z-buffering test [6], and assign it to the closest covering face. Each pixel is influenced exclusively by this face.
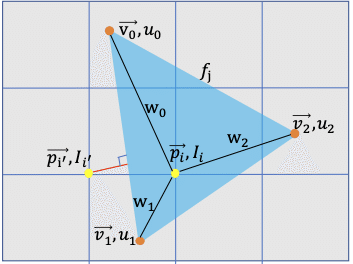
要約すると、「前景ピクセル」は、各頂点の重みを使用して、最も近い3つの隣接する頂点の補間として計算されます。ここで、「Ii」はピクセル強度です。
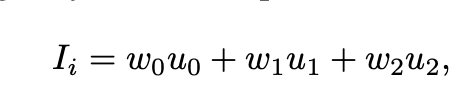
◎ 背景ピクセル
「背景ピクセル」、つまり3Dモデルのどの面でも覆われていないピクセルの場合、ピクセル値はピクセルから最も近い面までの距離に基づいて計算されます。
◎ その他の微分可能レンダラー
ここで重要なのは、「DIB-R」が最初で唯一の「微分可能レンダラー」ではないということです。「DIB-R」は、2014年に発表された「OpenDR」や、DIB-Rと同様の差分レンダラーを提案した「SoftRas-Mesh」のアイデアをベースに改良された「微分可能レンダラー」になります。

10. 2D画像から3Dモデルとテクスチャを生成するには
これまで、私たちが見ることができるものだけに言及しました。見えないものはどうでしょうか。時計の前の2D画像しかない場合、時計の後ろに何があるのかをどうやって把握すれば良いでしょうか。
現時点で物事を想像できる機械学習の唯一のものは、「GAN」です。
したがって、「GAN」を使用して3Dモデルとテクスチャを生成することができるのは当然のことです。
詳細は省きますが、「DIB-R」の論文の第2部で、エンコーダー・デコーダー・アーキテクチャーを持つ「GAN」と微分可能レンダラーと2Dスーパーバイズを用いて、1枚の2D画像から3Dモデルの頂点位置、ジオメトリ、カラー/テクスチャを予測することを説明しています。
11. DIB-Rチュートリアルの実行
「DIB-Rチュートリアル」では、「GAN」もニューラルネットワークも使用していません。「DIB-R」の「微分可能レンダラー」をPyTorchと組み合わせて使用して、同じオブジェクトの複数の視点から3Dジオメトリとテクスチャを繰り返し復元することに関する最適化問題を解決する方法の、簡単なデモンストレーションになります。
チュートリアルを実行する時が来ました。
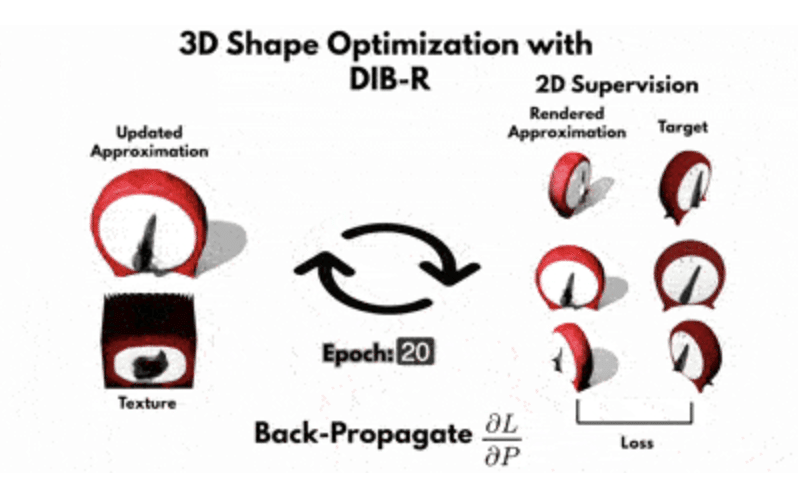
「DIB-Rチュートリアル」の目的は、キッチンデータセットの3Dオブジェクトを使って、微分可能レンダラー「DIB-R」を使用する方法を示すことです。キッチンデータセットにある時計は、トポロジカルな穴のない比較的単純なオブジェクトであるため、選択されました。
◎ 学習データの生成
「Kaolinアプリ」を使って、さまざまな視点(この場合は合計100の異なる視点)から時計の2D画像のデータセットを生成します。
視点ごとに、RGB画像、セグメンテーションマスク、焦点、絞り、焦点距離などのカメラパラメータを含む追加のメタデータJSONファイルを生成します。
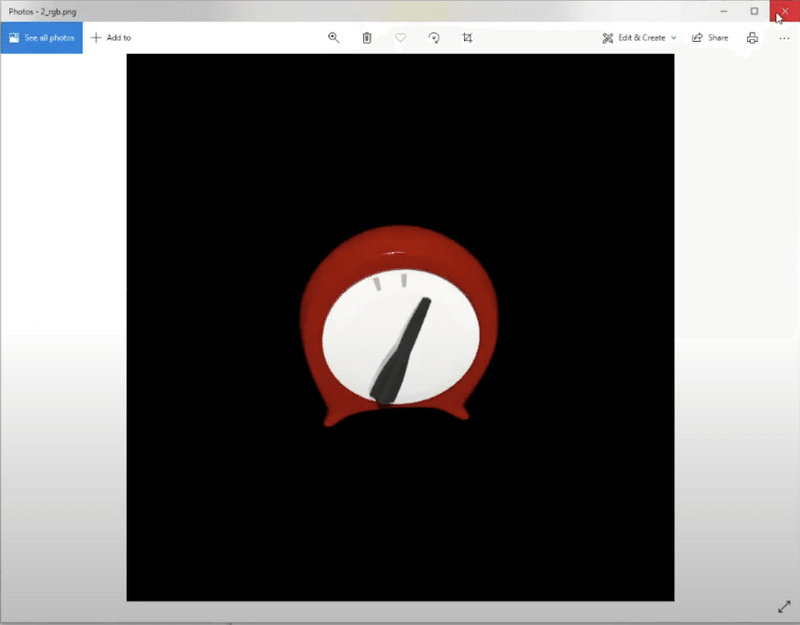

◎ 学習データの読み込み
学習データを読み込むには、PyTorchのクラスであるtorch.utils.DataLoaderを使用してデータセットをメモリにロードし、GPUですぐに使用できるようにします。pin_memoryをTrueに設定すると、データセットが固定されたメモリに自動的に読み込まれ、学習が開始されると、GPUメモリへの転送が高速になります。
また、kal.io.render.import_synthetic_view()を使用して、学習データセット内の各画像を読み込みます。さらに、各画像のセマンティックマスクファイルと、カメラパラメータを含むメタデータJSONを読み込みます。
num_views = len(glob.glob(os.path.join(rendered_path,'*_rgb.png')))
train_data = []
for i in range(num_views):
data = kal.io.render.import_synthetic_view(
rendered_path, i, rgb=True, semantic=True)
train_data.append(data)
dataloader = torch.utils.data.DataLoader(train_data, batch_size=batch_size,shuffle=True, pin_memory=True)◎ 球体テンプレートの読み込み
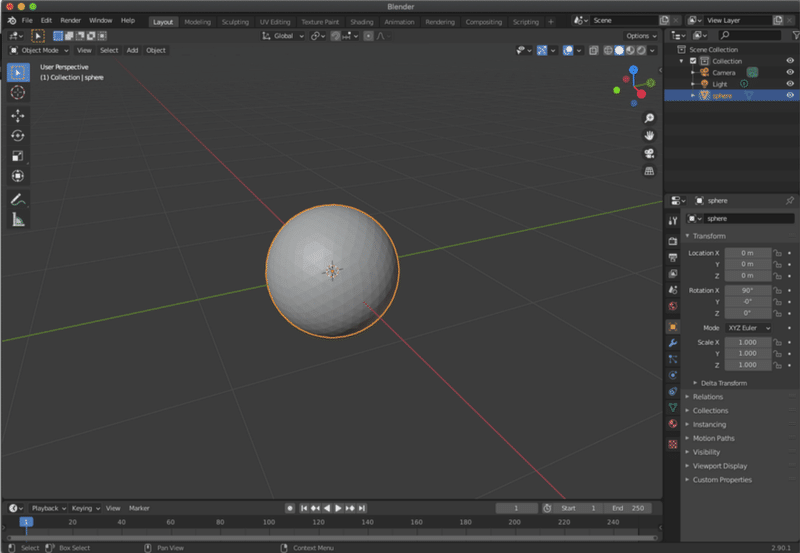
obj形式の球体を読み込みます。この球体は、学習中に時計に似た形に成形されます。
◎ 損失関数と正則化器の準備
Jupyter Notebookのこのセクションでは、損失関数の設定を行います。この損失関数には2つの目的があります。
・正解からどれだけ離れているかを知るための手段として使用します。正解とは、異なる場所に設置されたカメラから撮影された時計の異なる画像のことです。予測画像と正解画像の絶対的な差である「image L1 loss」を使用します。また、「mask loss」を計算します。これは、予測されたソフトマスクが、正解の時計のセグメンテーションマスクとどれだけ交差しているか(IoU)を測定するものです。
・正則化器として使用し、自己交差する面を持つジオメトリにペナルティを課し、滑らかさを促進する。ここでは、「laplacian loss」と「flat loss」を使用します。これらは一般的に使用される平滑度正則化です。
loss = (
image_loss * image_weight +
mask_loss * mask_weight +
laplacian_loss * laplacian_weight +
flat_loss * flat_weight
)

◎ オプティマイザの準備
チュートリアルでは、学習中に使用されるオプティマイザとして「Adam」を選択します。
optim = torch.optim.Adam(params=[vertices, texture_map, vertice_shift],lr=lr)
scheduler = torch.optim.lr_scheduler.StepLR(optim, step_size=scheduler_step_size,=scheduler_gamma)「Adam」は、学習時に「vertices」「texture_map」「vertice_shift」を学習可能なパラメータとしています。
「vertice_shift」は、学習時に球体のすべての頂点をシフトさせるためのパラメータのようです。推測ですが、球体の形を変えるたびに中心が移動するのではないかと思います。そのため、学習の各ステップで、「vertices」と「vertice_shift」を入力とするrecenter_vertices()を呼び出しています。
def recenter_vertices(vertices, vertice_shift):
"""Recenter vertices on vertice_shift for better optimization"""
vertices_min = vertices.min(dim=1, keepdim=True)[0]
vertices_max = vertices.max(dim=1, keepdim=True)[0]
vertices_mid = (vertices_min + vertices_max) / 2
vertices = vertices - vertices_mid + vertice_shift
return vertices◎ 学習
学習では、チュートリアルは合計40エポックで実行されます。各エポックには100ステップがあります。これは、時計に対して取得したビューの数です。
エポック0では、以前にノートブックにロードした球から始めます。球の頂点は頂点に格納され、球の初期テクスチャマップはtexture_mapに格納されます。
各ステップで、「DIB-R」を使用して、グラウンドトゥルースクロックに使用されるカメラと同じカメラ位置とパラメータを使用して、成形中の微分可能レンダラーをテクスチャが適用された2Dにレンダリングします。
各ステップの最後に、損失を計算します。
loss = (
image_loss * image_weight +
mask_loss * mask_weight +
laplacian_loss * laplacian_weight +
flat_loss * flat_weight
)最後にメッシュを更新します。
### Update the mesh ###
loss.backward()
optim.step()この2行のコードは不可欠です。
loss.backward()は勾配を計算します。つまり、最適化する各パラメータの値の変化を意味します。そして、optim.step()は、これらの勾配に従ってパラメータを更新します。
学習中、エポックごとに、球が時間の経過とともにどのように見えるかについてのスナップショットも取得していることに注意してください。 後で「Kaolinアプリ」を使用して視覚化します。
◎ 学習の可視化
最後のコードブロックは、時計の形に成形された後の球体の最終的な形状を示すためのものです。
実際に動かしてみると、同じような結果になるはずです。
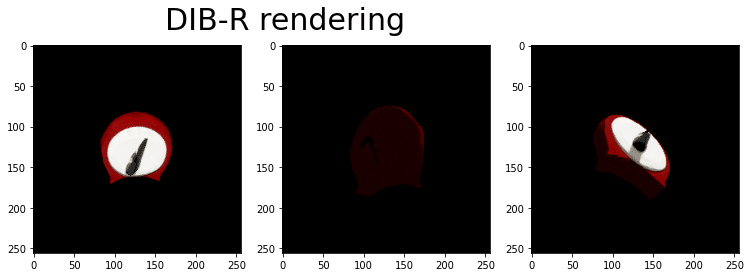

この段階では、「Kaolinアプリ」を使って学習のタイムラプスを見ることができるはずです。
この記事が役に立ち、なぜ微分可能レンダラーが必要なのか、なぜ3D深層学習にとって重要なのかを理解していただけたなら幸いです。
この記事が気に入ったらサポートをしてみませんか?