
Google Colab で Gemma を試す

「Google Colab」で「Gemma」を試したので、まとめました。
【注意】Google Colab Pro/Pro+ のA100で動作確認しています。
1. Gemma
「Gemma」は、「Gemini」と同じ技術を基に構築された、軽量で最先端のオープンモデルです。
2. Gemma のモデル
「Gemma」は、4つのモデルが提供されています。
・google/gemma-7b : ベースモデル
・google/gemma-7b-it : 指示モデル
・google/gemma-2b : ベースモデル
・google/gemma-2b-it : 指示モデル
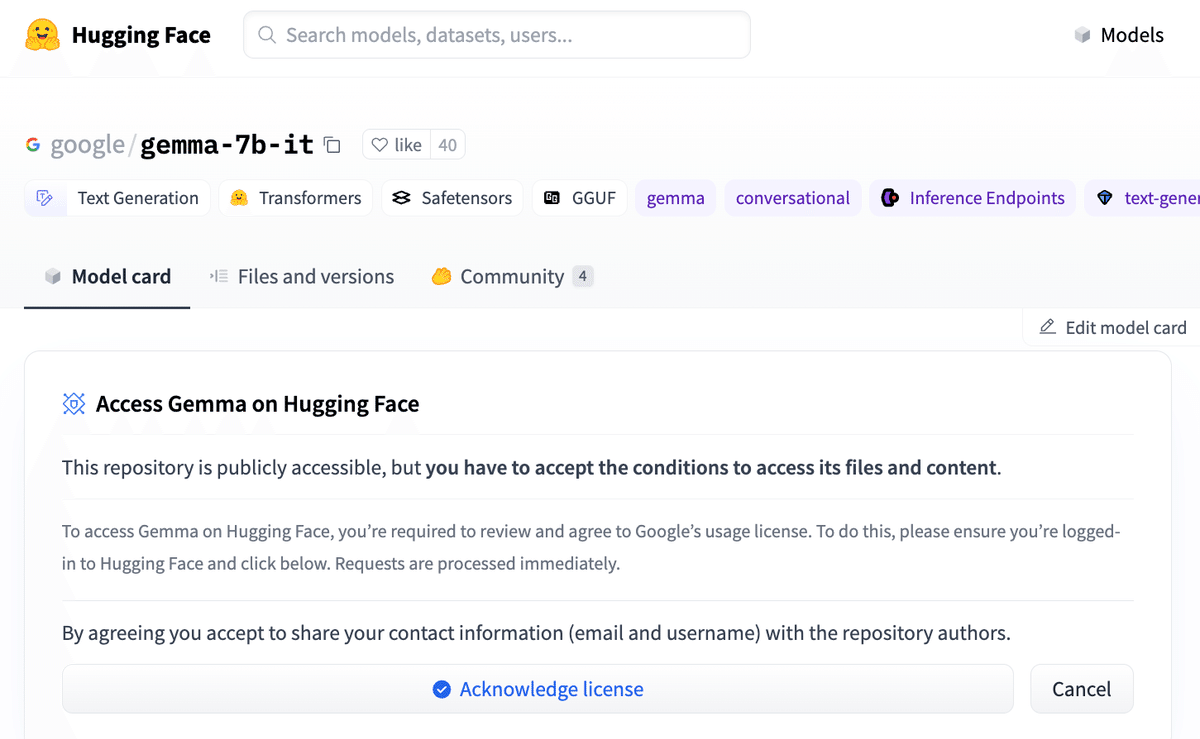
モデルカードのページを開き、HuggingFaceにログインし、「Acknowledge license」ボタンを押して、ライセンスを認証します。
3. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) Colabのノートブックを開き、メニュー「編集 → ノートブックの設定」で「GPU」の「A100」を選択。
(2) パッケージのインストール。
transformers v4.38.1 以降が必要です。(transformers v4.38.0 もNG)
# パッケージのインストール
!pip install -U transformers
!pip install accelerate(3) 環境変数の準備。
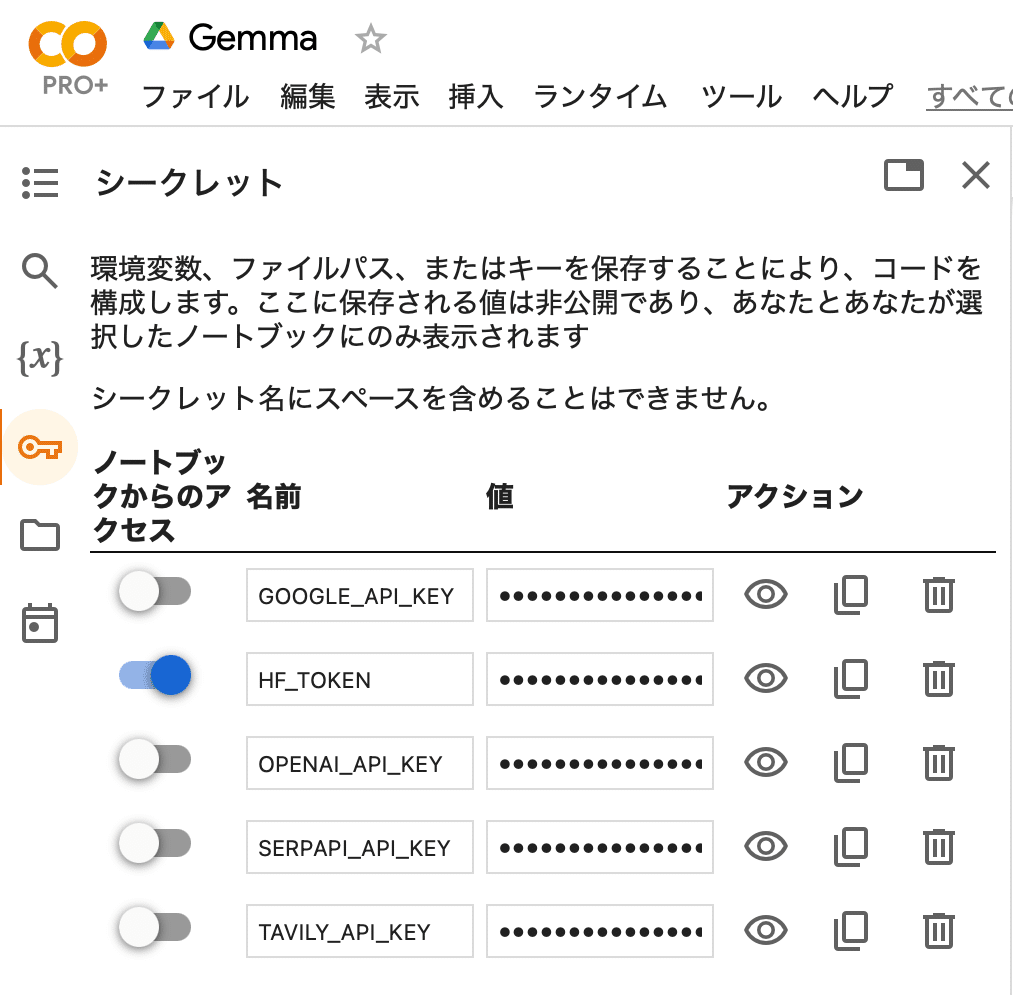
左端の鍵アイコンで「HF_TOKEN」(HuggingFaceのトークン)を設定し、有効化してからセルを実行してください。
(4) トークナイザーとモデルの準備。
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
"google/gemma-7b-it"
)
model = AutoModelForCausalLM.from_pretrained(
"google/gemma-7b-it",
device_map="auto",
torch_dtype=torch.float16
)(5) 推論の実行。
# プロンプトの準備
chat = [
{ "role": "user", "content": "まどか☆マギカでは誰が一番かわいい?" },
]
prompt = tokenizer.apply_chat_template(chat, tokenize=False, add_generation_prompt=True)
# 推論の実行
input_ids = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(
**input_ids,
max_new_tokens=128,
do_sample=True,
top_p=0.95,
temperature=0.7,
repetition_penalty=1.1,
)
print(tokenizer.decode(outputs[0]))<bos><start_of_turn>user まどか☆マギカでは誰が一番かわいい?<end_of_turn> <start_of_turn>model これは、あくまでも個人の好みによって決まるため、「誰が一番かわいいのか」と答えることは不可能です。<eos>
関連
Fine-tuned @Google's Gemma model using MLX on a MacBook Pro M3 Max 🔥
— Morning Coder (@morningcoder) February 28, 2024
Model: Gemma-7b-it
Dataset: @Teknium1 's awesome teknium/trismegistus-project dataset
Here's the code for the fine-tuning and uploading to Huggingface:https://t.co/y7SC5XrzJS
この記事が気に入ったらサポートをしてみませんか?