
Llama.cpp で Llama 2 を試す

「Llama.cpp」で「Llama 2」を試したので、まとめました。
・macOS 13.4.1
・Windows 11
前回
1. Llama.cpp
「Llama.cpp」はC言語で記述されたLLMのランタイムです。「Llama.cpp」の主な目標は、MacBookで4bit量子化を使用してLLAMAモデルを実行することです。
特徴は、次のとおりです。
・依存関係のないプレーンなC/C++実装
・Appleシリコンファースト (ARM NEON、Accelerate、Metalを介して最適化)
・x86アーキテクチャのAVX、AVX2、AVX512のサポート
・Mixed F16/F32精度
・4bit、5bit、8bit量子化サポート
・BLASでOpenBLAS/Apple BLAS/ARM Performance Lib/ATLAS/BLIS/Intel MKL/NVHPC/ACML/SCSL/SGIMATHなどをサポート
・cuBLASとCLBlastのサポート
サポートされているプラットフォームは、つぎおとおりです。
・Mac OS
・Linux
・Windows (CMake経由)
・Docker
2. LLama 2 のモデル一覧
「Llama.cpp」を利用するには、「Llama 2」モデルをGGML形式に変換する必要があります。HuggingFaceには、変換済みのモデルが公開されています。
・TheBloke/Llama-2-70B-GGML
・TheBloke/Llama-2-70B-Chat-GGML
・TheBloke/Llama-2-13B-GGML
・TheBloke/Llama-2-13B-chat-GGML
・TheBloke/Llama-2-7B-GGML
・TheBloke/Llama-2-7B-Chat-GGML
今回は、「TheBloke/Llama-2-7B-Chat-GGML」の「Files and versions」タブを選択し、4bit量子化版「llama-2-7b-chat.ggmlv3.q4_K_M.bin」をダウンロードします。
【注意】
最新の「Llama.cpp」では、ファイルフォーマットが「GGML」 (*.bin)から「GGUF」 (*.gguf) に変更になりました。
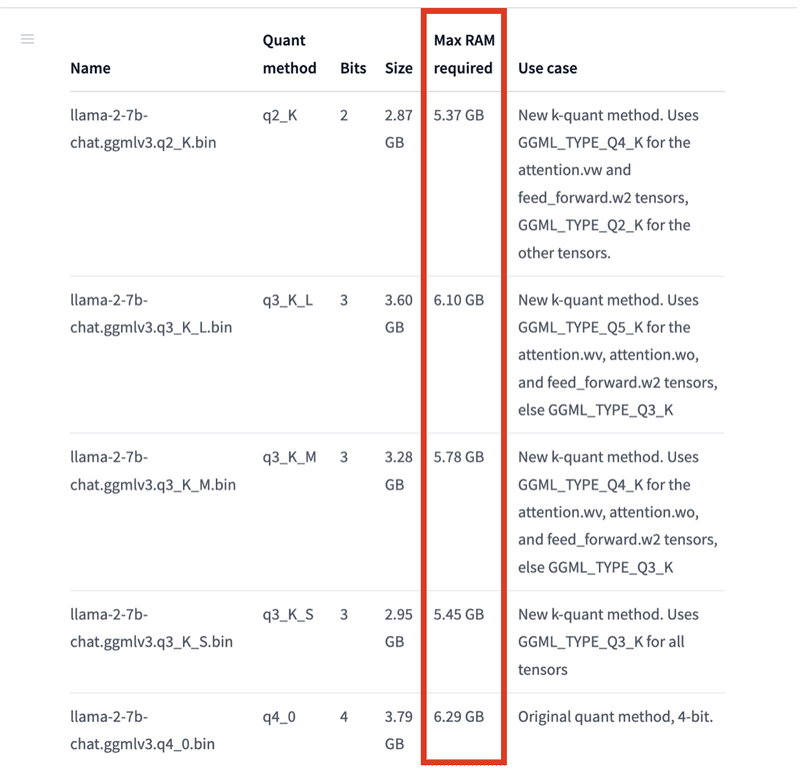
推奨は、「Q4_K_M」「Q5_K_M」「Q5_K_S」です。
・必要な最大RAM
必要な最大RAMは、各モデルカードの表で確認できます。
3. ビルドツールの準備
「Llama.cpp」は、インストール時に環境にあわせてソースからビルドして利用するため、ビルドツールが必要です。
3-1. macOS
(1) 「Xcode」がインストールされていることを確認。
$ xcode-select -p/Applications/Xcode-beta.app/Contents/Developer(2) Xcodeが見つからない場合はインストール。
$ xcode-select --install3-2. Windows
(1) 「w64devkit」(w64devkit-1.19.0.zip)をダウンロードして解凍。
Windows 用のポータブル C / C++ 開発キットになります。
(2) 「w64devkit」直下の「bin」のパスをWindowsの環境変数のPATHに追加。
4. Llama.cppの実行
「Llama.cpp」の実行手順は、次のとおりです。
(1) リポジトリのクローン。
$ git clone https://github.com/ggerganov/llama.cpp
$ cd llama.cpp(2) ビルド。
$ make(3) ダウンロードしたモデルを「llama.cpp/models」に配置。
(4) 推論の実行。
$ ./main -m ./models/llama-2-7b-chat.ggmlv3.q4_K_M.bin --temp 0.1 -p "### Instruction: What is the height of Mount Fuji?
### Response:"### Instruction: What is the height of Mount Fuji?
### Response: The height of Mount Fuji is 3,776 meters (12,421 feet) above sea level.
[end of text]
llama_print_timings: load time = 556.13 ms
llama_print_timings: sample time = 95.63 ms / 30 runs ( 3.19 ms per token, 313.70 tokens per second)
llama_print_timings: prompt eval time = 291.74 ms / 19 tokens ( 15.35 ms per token, 65.13 tokens per second)
llama_print_timings: eval time = 2158.23 ms / 29 runs ( 74.42 ms per token, 13.44 tokens per second)
llama_print_timings: total time = 2573.64 ms
ggml_metal_free: deallocating
Log end【翻訳】
### Instruction: 富士山の高さはどれくらいですか?
### Response: 富士山の高さは海抜 3,776 メートル (12,424 フィート) です。
[end of text]
時間の説明は次のとおりです。
・load time : モデルのロード時間
・sample time : プロンプトのトークン化 (サンプリング) 時間
・prompt eval time : トークン化されたプロンプトの処理時間
・eval time : 応答トークンの生成時間 (トークン出力を開始してからの時間のみを測定)
・total time : 合計時間
5. llama-cpp-pythonの実行
「llama-cpp-python」は、「Llama.cpp」のPythonバインディングです。特徴は、次のとおりです。
・C API への低レベルのアクセス。
・テキスト補完用の高レベルPython API
・OpenAI準拠のAPIの提供
・LangChainとの互換性
「llama-cpp-python」の実行手順は、次のとおりです。
(1) Pythonの仮想環境の準備。
(2) パッケージのインストール。
$ pip install llama-cpp-python再インストールする時は、以下のリビルドオプションが必要になります。
$ pip install --upgrade --force-reinstall llama-cpp-python --no-cache-dir(3) コードの作成。
・hello_ggml.py
from llama_cpp import Llama
# LLMの準備
llm = Llama(model_path="./llama-2-7b-chat.ggmlv3.q4_K_M.bin")
# プロンプトの準備
prompt = """### Instruction: What is the height of Mount Fuji?
### Response:"""
# 推論の実行
output = llm(
prompt,
temperature=0.1,
stop=["Instruction:", "Input:", "Response:", "\n"],
echo=True,
)
print(output["choices"][0]["text"])(4) コードの実行。
$ python hello_ggml.py### Instruction: What is the height of Mount Fuji?
### Response: The height of Mount Fuji is 3,776 meters (12,424 feet) above sea level.【翻訳】
### Instruction: 富士山の高さはどれくらいですか?
### Response: 富士山の高さは海抜 3,776 メートル (12,424 フィート) です。
【おまけ】 Llama.cpp のパラメータ
-h, --help : ヘルプ
-i, --interactive : interactiveモードで実行
--interactive-first : interactiveモードで実行し、入力待ち
-ins, --instruct : interactiveモードで実行 (Alpacaモデルを使用)
--multiline-input : 各行を「\」で終わらせず、複数行を書いたり貼り付けたりできる
-r PROMPT, --reverse-prompt PROMPT : PROMPTで生成を停止 (複数プロンプトに複数回指定可能)
--color : 色でプロンプトとユーザー入力を識別
-s SEED, --seed SEED : シード (default: -1, ランダム < 0)
-t N, --threads N : スレッド数 (default: 8)
-p PROMPT, --prompt PROMPT : プロンプト (default: empty)
-e : プロンプトのエスケープシーケンスを処理 (\n, \r, \t, \', \", \\)
--prompt-cache FNAME : ファイルでプロンプト状態をキャッシュし、起動を高速化 (default: none)
--prompt-cache-all : ユーザー入力と生成テキストをキャッシュに保存。interactiveモードなどの対話型オプションでは未サポート
--prompt-cache-ro : プロンプトのキャッシュを使用。更新はしない
--random-prompt : ランダムなプロンプトで開始
--in-prefix STRING : プレフィックス (default: empty)
--in-suffix STRING : サフィックス (default: empty)
-f FNAME, --file FNAME : プロンプトファイル
-n N, --n-predict N : 予測するトークン数 (default: -1, -1 = infinity)
-c N, --ctx-size N : プロンプトコンテキストのサイズ (default: 512)
-b N, --batch-size N : 高速処理のためのバッチサイズ (default: 512)
-gqa N, --gqa N : グループ化クエリーアテンションファクター (LLaMAv2 70Bでは8) (default: 1)
--top-k N : top-k サンプリング (default: 40, 0 = disabled)
--top-p N : top-p サンプリング (default: 0.9, 1.0 = disabled)
--tfs N : tail free サンプリングのパラメータ z (default: 1.0, 1.0 = disabled)
--typical N : locally typical サンプリングのパラメータ p (default: 1.0, 1.0 = disabled)
--repeat-last-n N : ペナルティを考慮する最後のn個のトークン (default: 64, 0 = disabled, -1 = ctx_size)
--repeat-penalty N : repeatペナルティ (default: 1.1, 1.0 = disabled)
--presence-penalty N : presenceペナルティ (default: 0.0, 0.0 = disabled)
--frequency-penalty N : frequencyペナルティ (default: 0.0, 0.0 = disabled)
--mirostat N : Mirostatサンプリング。Top K、Nucleus、Tail Free、Locally Typicalサンプラーを使用しても無視される(default: 0, 0 = disabled, 1 = Mirostat, 2 = Mirostat 2.0)
--mirostat-lr N : Mirostat学習率のパラメータ eta (default: 0.1)
--mirostat-ent N : Mirostatターゲットエントロピーのパラメータ tau (default: 5.0)
-l TOKEN_ID(+/-)BIAS, --logit-bias TOKEN_ID(+/-)BIAS : トークンがコンプリーションに登場する可能性の変更
i.e. `--logit-bias 15043+1` to increase likelihood of token ' Hello',
or `--logit-bias 15043-1` to decrease likelihood of token ' Hello'
--grammar GRAMMAR : テキスト生成を成約する BNF-like grammar (grammars/ dir のサンプルを参照)
--grammar-file FNAME : ファイルから grammar を読み込む
--cfg-negative-prompt PROMPT : ネガティブプロンプトをガイダンスに使用 (default: empty)
--cfg-scale N : ガイダンスの強さ (default: 1.000000, 1.0 = disable)
--rope-freq-base N : RoPEの基本周波数 (default: 10000.0)
--rope-freq-scale N : RoPE周波数スケーリング係数 (default: 1)
--ignore-eos : EOSを無視して生成を続行 (implies --logit-bias 2-inf)
--no-penalize-nl : 改行トークンにペナルティを与えない
--memory-f32 : メモリのキーと値には f16 の代わりに f32 を使用 (非推奨) (default: disabled)
--temp N : 温度。生成テキストのランダムさ (default: 0.8)
--perplexity : プロンプトの各ctx windowに対するperplexityの計算
--perplexity-lines : プロンプトの各行に対するperplexityの計算
--keep : 最初のプロンプトから保持するトークン数 (default: 0, -1 = all)
--chunks N : 処理するチャンクの最大数 (default: -1, -1 = all)
--mlock : スワップや圧縮せずにRAMでモデルを保持
--no-mmap : メモリマップモデルを使用しない(ロードが遅くなるが、mlockを使用しない場合はページアウトが減る可能性がある)
--numa : 一部のNUMAシステムで役立つ最適化を試みる。
--mtest : 最大メモリ使用量の計算
--export : computation graph を'llama.ggml'にエクスポート
--verbose-prompt : 生成前のプリントプロンプト
--lora FNAME : LoRAアダプターの適用 (implies --no-mmap)
--lora-base FNAME : LoRAアダプタが変更するレイヤのベースとして使用するオプションモデル
-m FNAME, --model FNAME : モデルパス (default: models/7B/ggml-model.bin)
【おまけ】 llama-cpp-pythonの主なAPI
・__init__()
__init__(
model_path, # モデルパス
n_ctx=512, # 最大コンテキストサイズ
n_parts=-1, # モデル分割数(-1:自動)
n_gpu_layers=0, #
seed=1337, # シード(-1:ランダム)
f16_kv=True, # キー/値のキャッシュに半精度を使用
logits_all=False, # 最後のトークンだけでなく、全トークンのログ返す
vocab_only=False, # 語彙のみをロード (重みなし)
use_mmap=True, # 可能であれば、mmapを使用
use_mlock=False, # モデルのRAM保存を強制
embedding=False, # 埋め込みモードのみ
n_threads=None, # スレッド数(なし:自動)
n_batch=512, # llama_eval呼び出し時のバッチ数
last_n_tokens_size=64, # last_n_tokens dequeに保持するトークン最大数
lora_base=None, # ベースモデルのパス
lora_path=None, # LoRAファイルへのパス
low_vram=False, #
tensor_split=None, # モデルを複数のGPUに分割
rope_freq_base=10000.0, # ロープサンプリングの基本周波数
rope_freq_scale=1.0, # ロープサンプリングのスケールファクター
verbose=True # 詳細出力
)
説明: コンストラクタ
・__call__()
__call__(
prompt, # プロンプト
suffix=None, # 生成テキストに追加するサフィックス
max_tokens=128, # 生成テキストの最大トークン数 (0:無制限)
temperature=0.8, # サンプリングの温度
top_p=0.95, # サンプリングのtop-p
logprobs=None, # 返すログプロブ数
echo=False, # プロンプトをエコーするか
stop=[], # 停止文字列リスト
frequency_penalty=0.0, # frequencyペナルティ
presence_penalty=0.0, # presenceペナルティ
repeat_penalty=1.1, # リピートペナルティ
top_k=40, # サンプリングのtop-k
stream=False, # ストリーミング
tfs_z=1.0, #
mirostat_mode=0, #
mirostat_tau=5.0, #
mirostat_eta=0.1, #
model=None, #
stopping_criteria=None, #
logits_processor=None #
)
説明: プロンプトからテキストを生成
戻り値: CompletionまたはCompletionのストリーム
(Union[Completion, Iterator[CompletionChunk]])
・create_completion()
create_completion(
prompt, # プロンプト
suffix=None, # 生成テキストに追加するサフィックス
max_tokens=128, # 生成テキストの最大トークン数 (0:無制限)
temperature=0.8, # サンプリングの温度
top_p=0.95, # サンプリングのtop-p
logprobs=None, # 返すログプロブ数
echo=False, # プロンプトをエコーするか
stop=[], # 停止文字列リスト
frequency_penalty=0.0, # frequencyペナルティ
presence_penalty=0.0, # presenceペナルティ
repeat_penalty=1.1, # リピートペナルティ
top_k=40, # サンプリングのtop-k
stream=False, # ストリーミング
tfs_z=1.0, #
mirostat_mode=0, #
mirostat_tau=5.0, #
mirostat_eta=0.1, #
model=None, #
stopping_criteria=None, #
logits_processor=None #
)
説明: プロンプトからテキストを生成
戻り値: CompletionまたはCompletionのストリーム
(Union[Completion, Iterator[CompletionChunk]])
・create_chat_completion()
create_chat_completion(
messages, # メッセージリスト
temperature=0.2, # サンプリングの温度
top_p=0.95, # サンプリングのtop-p
top_k=40, # サンプリングのtop-k
stream=False, # ストリーミング
stop=[], # 停止文字列リスト
max_tokens=256, # 生成テキストの最大トークン数 (0:無制限)
presence_penalty=0.0, # presenceペナルティ
frequency_penalty=0.0, # frequencyペナルティ
repeat_penalty=1.1, # リピートペナルティ
tfs_z=1.0, #
mirostat_mode=0, #
mirostat_tau=5.0, #
mirostat_eta=0.1, #
model=None, #
logits_processor=None #
)
説明: メッセージリストからチャット応答を生成
戻り値: ChatCompletionまたはChatCompletionのストリーム
(Union[ChatCompletion, Iterator[ChatCompletionChunk]])
関連
次回
この記事が気に入ったらサポートをしてみませんか?