Google Colab で idefics2 を試す

「Google Colab」で「idefics2」を試したので、まとめました。
1. idefics2
「Idefics2」は、テキストと画像を入力し、テキストを出力するマルチモーダルモデルです。画像の質問応答、視覚的コンテンツの説明、複数画像をもとに物語作成、文書からの情報抽出などを実行できます。
2. Colabでの実行
Colabでの実行手順は、次のとおりです。
(1) パッケージのインストール。
# パッケージのインストール
!pip install -U git+https://github.com/huggingface/transformers accelerate bitsandbytes(2) 画像の準備。
from transformers.image_utils import load_image
# 画像の準備 (プロセッサーに画像URLを渡すことも可)
image1 = load_image("https://assets.st-note.com/img/1712816517518-usYIzxfnhP.png")
(3) プロセッサとモデルの準備。
4bit量子化しています。
from transformers import AutoProcessor, AutoModelForVision2Seq, BitsAndBytesConfig
import torch
# プロセッサとモデルの準備
processor = AutoProcessor.from_pretrained(
"HuggingFaceM4/idefics2-8b",
do_image_splitting=False
)
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForVision2Seq.from_pretrained(
"HuggingFaceM4/idefics2-8b",
torch_dtype=torch.float16,
quantization_config=bnb_config,
device_map="auto",
)(5) プロンプトの準備。
# プロンプトの準備
messages = [
{
"role": "user",
"content": [
{"type": "image"},
{"type": "text", "text": "What image is this?"},
]
},
]
prompt = processor.apply_chat_template(messages, add_generation_prompt=True)
print(prompt)User:<image>What image is this?<end_of_utterance>
Assistant:
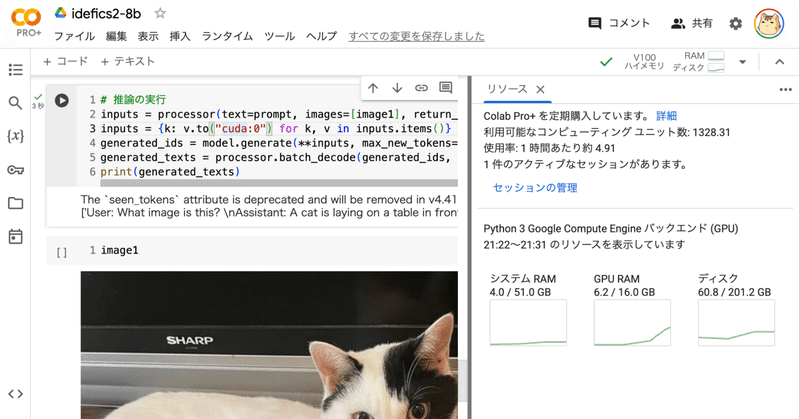
(6) 推論の実行。
# 推論の実行
inputs = processor(text=prompt, images=[image1], return_tensors="pt")
inputs = {k: v.to("cuda:0") for k, v in inputs.items()}
generated_ids = model.generate(**inputs, max_new_tokens=500)
generated_texts = processor.batch_decode(generated_ids, skip_special_tokens=True)
print(generated_texts)['User:What image is this?
Assistant: A cat is laying on a table in front of a Sharp flat screen TV.']

この記事が気に入ったらサポートをしてみませんか?