
Unity ML-Agents 0.11.0のAcademyとAgent

1. Academy
「Academy」(アカデミー)は、「Unity ML-Agents」の強化学習環境の全体に対する設定を行うオブジェクトです。強化学習環境には必ず1つ存在します。エピソードの最大ステップ数や、レンダリング品質、リセットパラメータなどを行います。
2. Academyクラスのメソッド
「Academy」を使用するには、「Academyクラス」のサブクラスを作成し、メソッドをオーバーライドして実装します。
using UnityEngine;
using MLAgents;
// Academy
public class MyAcademy : Academy {
// 初期化時に呼ばれる
public override void InitializeAcademy() {
}
// 環境リセット時に呼ばれる
public override void AcademyReset() {
}
// ステップ毎に呼ばれる
public override void AcademyStep() {
}
}◎ 初期化時に呼ばれる
Academyオブジェクトの初期化時の処理は、InitializeAcademy()に記述します。オブジェクト生成時に1回だけ呼ばれます。Awake()とFixedUpdate()は、基底クラスの「Academy」が利用しているので、オーバーライドしないでください。
◎ 環境リセット時に呼ばれる
環境のリセット時の処理は、AcademyReset()に記述します。「Python UnityEnvironment」でreset()が呼び出されると、環境リセットされます。
◎ ステップ毎に呼ばれる
ステップ毎に行う処理は、AcademyStep()に記述します。エージェントが更新される前に呼ばれます。
3. Academyクラスのプロパティ
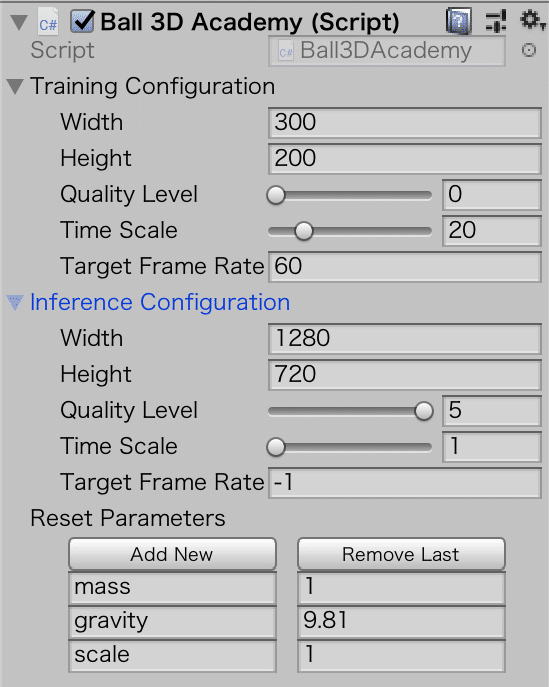
・Configuration: 学習用と推論用のレンダリング品質と実行速度の設定
・Width: 画面幅(ピクセル)
・Height: 画面高さ(ピクセル)
・Quality Level: レンダリング品質(低0〜5高)
・Time Scale: 実行速度(遅1〜100速)
・Target Frame Rate: FPS
・Reset Parameters: リセットパラメータ4. Agent
「Agent」(エージェント)は、「Unity ML-Agents」の強化学習環境のエージェントに対する設定を行うオブジェクトです。強化学習環境には1つ以上の「Agent」が存在します。エージェントは、「観察の取得 → 行動の決定 → 行動の実行 → 報酬の取得」という強化学習サイクルの一連の処理を行います。
5. Agentクラス
「Agent」を使用するには、「Agentクラス」のサブクラスを作成し、メソッドをオーバーライドして実装します。
using UnityEngine;
using MLAgents;
// Agent
public class MyAgent : Agent {
// 初期化時に呼ばれる
public override void InitializeAgent() {
}
// エージェントのリセット時に呼ばれる
public override void AgentReset() {
}
// 観察の取得時に呼ばれる
public override void CollectObservations() {
}
// 行動の実行時に呼ばれる
public override void AgentAction(float[] vectorAction, string textAction) {
}
// ルールベースによる行動決定時に呼ばれる
public override float[] Heuristic() {
var action = new float[2];
return action;
}
}◎ 初期化時に呼ばれる
Agentオブジェクトの初期化時の処理は、InitializeAgent()に記述します。
オブジェクト生成時に1回だけ呼ばれます。
◎ エージェントリセット時に呼ばれる
エージェントリセット時の処理は、AgentReset()に記述します。
◎ 観察の取得時に呼ばれる
観察の取得時の処理は、CollectObservations()に記述します。AddVectorObs()で取得した観察を指定します。
◎ 行動の実行時に呼ばれる
行動の実行時の処理は、AgentAction()に記述します。「ニューラルネットワークモデル」または「ルールベース」で決定された「行動」を取得し、「行動の実行」と「報酬の取得」を実装します。
◎ ルールベースによる行動決定時に呼ばれる
ルールベースによる行動決定時の処理は、Heuristic()に記述します。
決定した行動を、戻り値で返します。
6. Decision(決定)
「観察の取得 → 行動の決定 → 行動の実行 → 報酬の取得」という強化学習サイクルの一連の処理を「Decision」(決定)と呼びます。
(1)観察の取得: CollectObservations()で観察を指定
(2)行動の決定: ニューラルネットワークまたはルールベースで行動を決定
(3)行動の実行: AgentAction()で行動を実行
(4)報酬の取得: AgentAction()で報酬を取得
◎ Decisionが実行されるタイミング
「Decision」が実行されるタイミングは2種類あります。
・任意のステップ数毎に「Decision」を実行
・任意のタイミング(Agent.RequestDecision()が呼ばれた時)に「Decision」を実行
「Agent」のプロパティの「On Demand Decisions」を「チェックあり」で任意のステップ毎、「チェックなし」で任意のタイミングに実行されます。任意のステップ毎のステップ数は、「Decision Interval」で指定します。
◎ ニューラルネットワークモデルとルールベースの選択
「行動の決定」は、「ニューラルネットワークモデル」と「ルールベース」のどちらかを選びます。
・ニューラルネットワークモデル
・ルールベース
「Behavior Parameters」の「Use Heuristic」を「チェックあり」で「ルールベース」、「チェックなし」で「ニューラルネットワーク」を使います。
「ルールベース」はAgent.Heuristic()で実行します。モデルは「Behavior Parameters」の「Model」で指定します。
7. Agentクラスのプロパティ
エージェントのパラメータを設定するコンポーネントは、「Agentクラス」以外にも存在します。
・Behavior Parameters: 行動の決定に必要なパラメータ
・CameraSensorComponent: カメラによる目視観察のパラメータ
・RenderTextureComponent: テクスチャによる目視観察のパラメータ
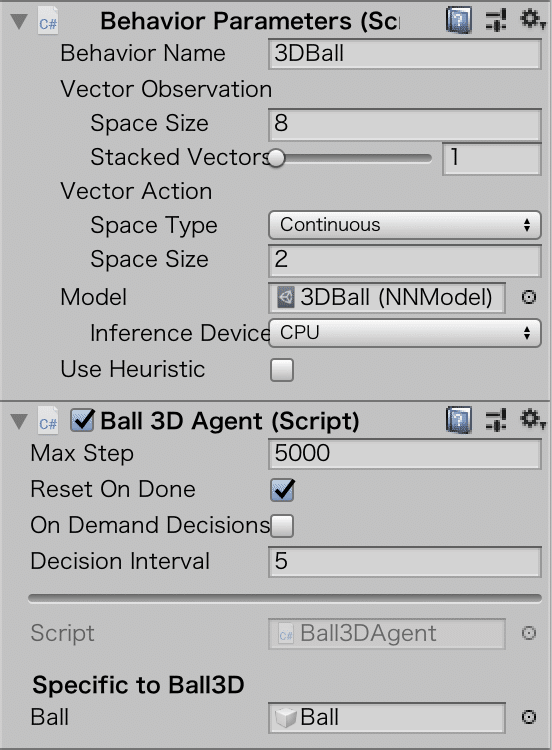
◎ Agentクラスのプロパティ
・Max Step: 最大ステップ数
・Reset On Done: エピソード完了時に自動的にエピソードリセットを行うか
・On Demand Decisions: Decisionの実行タイミング
・Decision Interval: 任意のステップ毎にDecisionを実行する際のステップ数◎ Behavior Parametersクラスのプロパティ
・Vector Observation: ベクトル観察
・Space Size: 観察のサイズ
・Stacked Vectors: 観察のスタック数
・Vector Action: ベクトル行動
・Space Type: 行動空間の型(Continuous or Discrete)
・Space Size: Continuousな行動のサイズ
・Branches Size: Discreteな行動のブランチサイズ
・Batch X Size: Discreteな行動のバッチサイズ
・Model: 行動の決定に利用するモデル
・Inference Device: 推論デバイス(CPU or GPU)
・Use Heuristic: ニューラルネットワークモデル or ルールベースこの記事が気に入ったらサポートをしてみませんか?