
Pythonでスクレイピング その➂ ~実践編 次の頁もいただいちゃいます

前回の記事では、Webページから株価情報等を取得して、CSVファイルに書き込んでいき、更に表やグラフ形式で視覚的に確認するという方法について記載しました。(前回記事)
ご自分でも、好きなサイトから実際にデータを取得するということを色々試していただくとどんどん理解が深まると思います。
今回は、ニュースサイトから記事タイトルとURLを取得する、更に別ページにある過去記事も併せて取得して全記事を取得する、ということをやっていきます。(僕はRSSサイト+この方法でニュースや気になる記事を読んでます)
なお、連続でレスポンス情報を取得しに行くので、コード例にもある通りtimeモジュールを使って、サイトに負荷をかけないよう、くれぐれもご留意くださいm(_ _)m
1.lifehackerから全記事を取得する
早速やっていきたいと思います。まずは、対象のサイトの大体の構成を把握します。
(1) サイトの構成
➀にPickUp記事が、➁に新着記事が、➂にランキング上位記事が載っています。そして、➃のもっと見るボタンがあります。
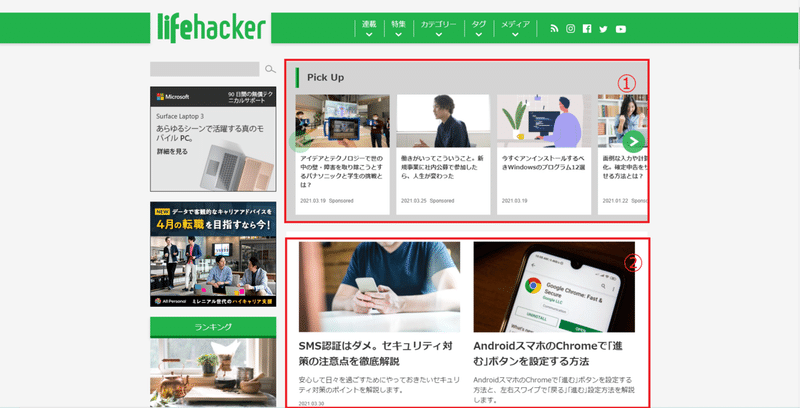
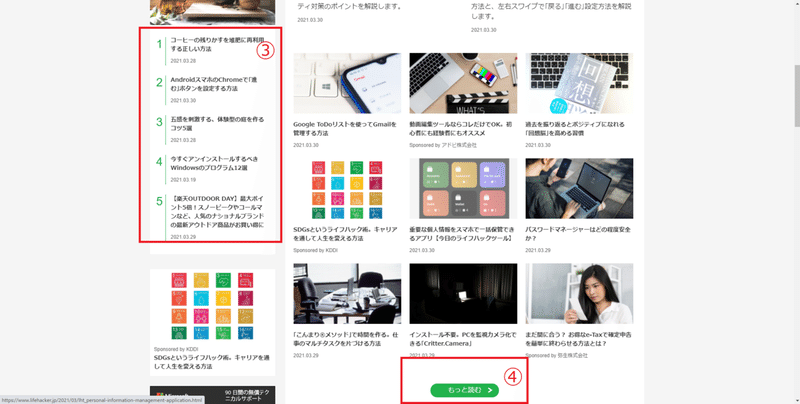
➃を押してみると、、、新着記事が一覧表示され、➄の>ボタンを押下すると1頁ずつ遡れるようになっています。
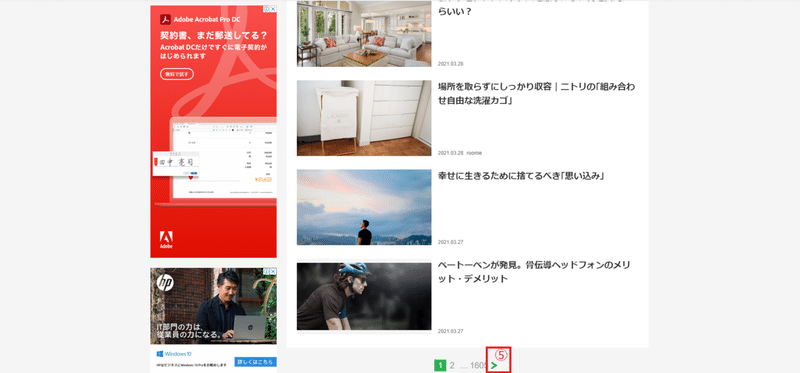
(2) 全記事の取得の仕方を考える
記事の構成が分かったところで、全記事を取得する方法を考えます。
【対応案】
ⅰ. トップページの➃「もっと読む」ボタンで新着記事ページに飛ぶ
(あるいはハナから、新着記事ページからスタートする)
↓
ⅱ.ページ内の記事を取得する
↓
ⅲ.>ボタンの先に富んで、再びページ内の記事を取得する
↓
ⅳ.ⅱ~ⅲを>ボタンが出なくなるまで繰り返す
今回は、別ページにも動的にアクセスして、Webスクレイピングすることがテーマなので、ⅰもトップページ経由でやりたいと思います。
2.BeautifulSoupでの抽出方法
次に、どうやったらお目当ての記事タイトル・URLを取得できるかをHTML情報を見ながら検討していきます。
(1) ➃「もっと読む」ボタン
aタグの class属性"lh-button"で抽出できそうです。

(2) 新着記事の抽出
aタグのstringとhref属性が欲しいですが、それ以外に特定する情報がないので一つ上のh3タグ class属性"lh-summary-title"から攻めればいけそうです。
一点、記事のhref属性が/2021/03/232126・・・・(以下略)となっていますが、このアドレスだと記事にアクセスできません。URLは絶対パスと相対パスという書き方があり、https://www.lifehacker.jp/2021/03/232126・・・のような書き方が絶対パス、途中から記載されているのは相対パスとなります。
ページ内で遷移する場合は、相対パスでもOKですが、例えばGoogleのトップページ等からURLを指定してアクセスする場合は、絶対パスで行う必要があります。(つまり、頭の部分を補って絶対パスにしてあげる必要があります。)
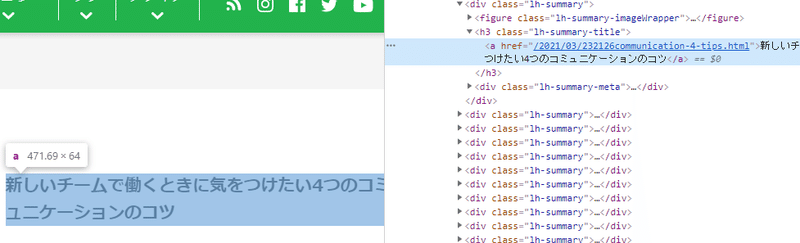
(3)➄ 「>」ボタン
href属性のhttps://www.lifehacker.jp/articles/2というのが、次ページのURLなので、aタグのclass属性"lh-pager-numbers lh-page-numbers--next"で取得できると分かります。
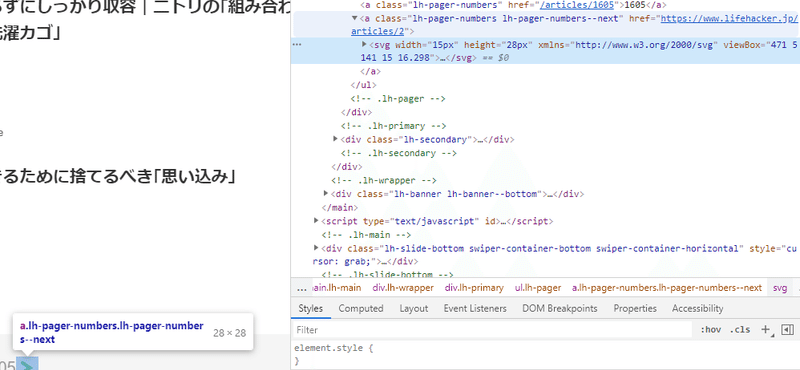
あとは、全記事を取得して「>」で次ページのレスポンス情報を取得、BeutifulSoupで解析して、再び全記事を取得して「>」・・・と繰り返すだけだと分かります。
3.コーディング例
以上を踏まえたコーディング例は以下のとおり。
#必要なライブラリのインポート
import requests
from bs4 import BeautifulSoup
import time
#サイトのトップページ
url = "https://www.lifehacker.jp/"
#URLを絶対パス化するために、頭につけてあげるURL
base_url = "https://www.lifehacker.jp"
#lifehackerのトップページから、レスポンス情報を取得しBeutifulSoupでHTMLデータ解析
res = requests.get(url)
soup = BeautifulSoup(res.text, 'html.parser')
#もっと読むボタンのURL情報を取得し、変数startbに格納(変数名は適当)
startb = base_url + soup.find(class_ = 'lh-block-button').a['href']
#もっと読むボタンのURLから、レスポンス情報を改めて取得し、BeutifulSoupでHTMLデータ解析
res = requests.get(startb)
soup = BeautifulSoup(res.text, 'html.parser')
#記事情報を取得するため、h3タグでclass属性がlh-summary-titleのものをfind_allで全取得
#リスト型の変数articlesに格納
articles = soup.find_all('h3',class_ = "lh-summary-title")
#記事を全量取得 #Whileループ処理を使って、「>」が表示されなくなるまで継続処理
while soup.find(class_='lh-pager-numbers lh-pager-numbers--next') != None:
#articlesリストに対しforループ処理を実施
for article in articles:
#HTML要素からaタグのテキスト情報(記事タイトル)を出力
print(article.a.string)
#HTML要素からaタグのhref属性(記事URL)に絶対パス化のためのURLを補ったものを出力
print(base_url + article.a['href'])
#「<」のURL(次ページのURL)を取得
nextb = soup.find(class_ = 'lh-pager-numbers lh-pager-numbers--next')['href']
# 次ページのURLを出力(ページ数の記載があるので、処理状況が確認できる)
print(nextb)
# サイトに負荷をかけないよう、処理を3秒停止
time.sleep(3)
#次ページURLからレスポンス情報を取得し、BeutifulSoupでHTMLデータ解析
res = requests.get(nextb)
soup = BeautifulSoup(res.text, 'html.parser')
#articles変数に記事情報を格納(ループ処理の先頭部分に繋がる
articles = soup.find_all('h3',class_ = "lh-summary-title")
else:
#「<」がなくなりループ処理を抜けたら、処理完了と出力
print("処理完了")新しい話としては、Whileループ処理があります。forループは既にでてきましたが、同様にループ処理ではあります。
簡単にいうと、「~という条件が変わらなければ、処理をし続ける」というようにループ処理を定義したい場合に良く使います。
forループは、決められた回数やリストの要素数分の回数等、回数が明確な場合に使い、whileループはループ回数が動的に変動する場合に使うことが多いです。
書き方は
while 条件式:
処理
else:
完了時処理のような感じです。(elseはなくてもOK)
例えば、変数countが10を超えなければ、処理を継続。10を超えるようなことがあれば、処理を停止。のような場合。
count = 0
while count < 11:
count += 1のように書きます。定義された変数countを1増やす処理を繰り返す。
但し、10を超えたら、ループ処理を抜けるという記載になります。
次回は、更に実践的に複数サイトから、新着記事を抽出。気になるキーワードを含む記事だけを、CSVに格納するというのをコーディング&解説していきたいと思います。
読んでいただきありがとうございます。
この記事が気に入ったらサポートをしてみませんか?