
Pythonでスクレイピング その➁ ~実践編-CSV読み書き・表・グラフ描画まで

みなさまいかがお過ごしでしょうか。
私は顎関節症気味です。色々な原因はあるようですが、脳を休めないとあかんようです。←
今日は実践で応用して使っていただけそうな、プログラムを紹介・解説していきます。加えて、プログラミングで押さえるべきポイントでも紹介した条件式・ループ処理にも触れます。
1.日経平均株価・TOPIX・ダウ平均を抽出する
「Yahoo!ファイナンスの以下の部分から、日経平均株価・TOPIX・ダウ平均を抽出して取得日をくっつけて、CSVに保存する」そんな、プログラムを一緒に書いていきたいと思います。
必要なパッケージやモジュールのインポート等は、前回の記事(PythonでWebスクレイピング(その➀)~まずはWebから抽出してみる)を参照ください。
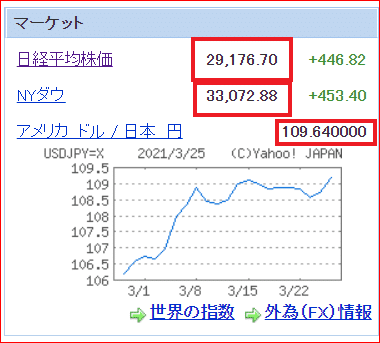
Yahoo!ファイナンスより(赤字部分を抽出する)
(日経平均株価の著作権は、日本経済新聞社に帰属してます。)
2.必要データを抽出する(Let’s Webスクレイピング)
➀reqeustsとBeautifulSoupをインポートします。なお、datetimeモジュールをインポートしているのは、取得日を保存したいためです。
➁Yahoo!ファイナンス(https://finance.yahoo.co.jp/)を変数url(変数名は何でも可)にセットします。
#必要なモジュール・パッケージのインポート➀
import requests
from bs4 import BeautifulSoup
import datetime
#URLにYahoo!ファイナンスのURLを設定➁
url = 'https://finance.yahoo.co.jp/'➂ 前回同様requestsモジュールのgetメソッドを使って、レスポンス情報を取得し、レスポンス情報のテキスト情報をBeautifulSoupに渡してHTML解析をしていきましょう。
#レスポンス情報をrequestsモジュールのgetメソッドで取得
res = requests.get(url)
#BeautifulSoupに引数として、レスポンス情報のテキストを渡す
#第2引数には解析のためのhtml.parserをセット
soup = BeautifulSoup(res.text,'html.parser')ここまで大丈夫でしょうか。分からない場合は、前回の記事を見返すか、はたまたググってみてください(え)。
プログラムを書く時は、小さく書いて実行するのがコツです。全部書いて実行してエラーが出ても「えーっ・・・めんどい」となるので、インポートできるよね?レスポンス情報とれてるよね?(.status_codeで確認)など、細かく切って実行していくといいと思います。
➃ 日経平均株価・TOPIX・ダウ平均を抽出する
では、本題です。どうやって抽出しましょう。思い出してみてください。
・・・はい、正解です!!
まずは、コレですね。chromeの検証で、欲しい情報がどんなHTMLタグの中にあるのか確認します。


こんな感じです。<dd class="ymuiEditLink mar0"><strong></strong></dd>に囲まれております。
Anaconda環境の方、もしくはAnaconda環境以外でもJupyterNotebookだとプログラムを小間切れに書けるので、こんな時便利です。
では、まずはstrongタグで抽出してみましょう。
find_allメソッドで、対象のタグ情報を全量リスト形式で抽出します。
リスト形式とは[](スクエアブラケット)内に,(カンマ区切り)で複数データを格納できる便利なコンテナです。
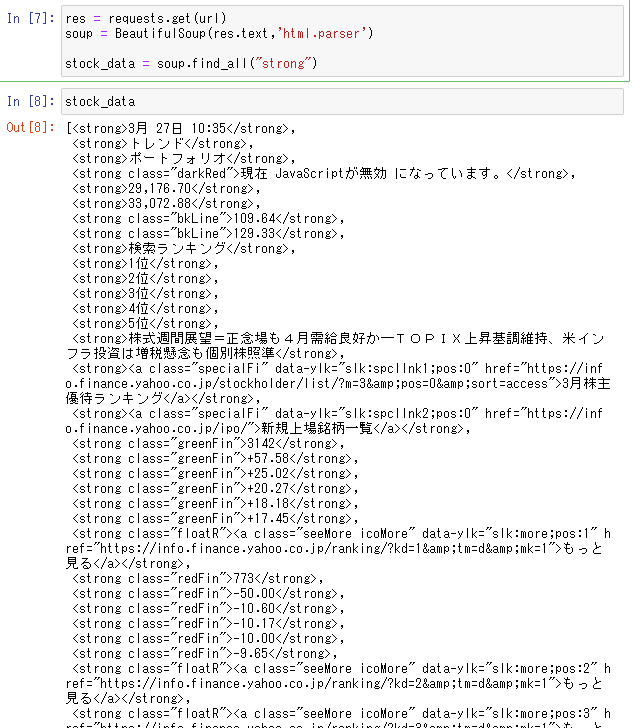
5つ目に日経平均株価が抽出されています。これはこれでOKです。
リストは以下のような形で、値を取り出すことが可能です。
(0からカウントされるため、4が5番目となります)

ここから.stringで更に文字列を取り出すと、、、

取り出せました。TOPIXとダウ平均も取り出す場合は、以下のように5~7番目として指定して取り出せます。

では、ここに.stringで・・・

エラーとなりました。リスト型に対して.string関数は使えません。type関数を使って、データ型を調べてみましょう。

上の、日経平均株価単体を抽出したものは、bs4.elementa.Tag型なのに対し、下はリスト型です。あくまで、string関数は、BeaurifulSoupのTagオブジェクトに対してのみ使えるのです。
では、TOPIXとダウ平均はどうやって抽出すればいいのでしょうか?
3.リスト型とループ処理
[5]、[6]をつけて1個ずつ抽出するのも、もちろん正解です。
ここでリスト型に対するループ処理が活躍します。ループ処理というのは簡単に言うと自動で繰り返しをしてくれる処理です。同じようなコードを3本かかずとも、完結な記載で後はプログラムがよろしくやってくれる訳です。
では、どう書けばいいか。以下を参照ください。
for data in stock_data[4:7]:
print(data.string)これだけでOKなのです。わお。もっと言うと、これでもできます。
なお、2行目をスペース空けて記載しているのは、インデント(字下げ)といってPythonではこれがコードの塊を表します。
インデントがないとエラーとなります。
(条件式やこの後で出てくるファイル書き込み字も同様。これがループ処理を行う塊ですよーって感じです)
[print(data.string) for data in stock_data[4:7]]どっちも実行してみましょう。

できました。2番目の方法はリスト内包表記といって、Python特有の記法です。なお、ループ処理とリスト型といのは、他の言語にも大体共通して存在してます。(書き方は異なりますが)
プログラムを書く上で、それだけ良く使うということで、存在を覚えておけばOKです。記法は分からなくなったらググればいいだけなので。笑
for 変数 in リスト型:
処理という感じの書き方です。リスト型から、値を一つずつ取り出して変数に格納し、その変数ごとに処理を行っているのです。
4.その他の抽出方法
先ほどは<strong>タグで抽出をしましたが、それ以外にも抽出方法はあります。例えば<strong>タグの外側にある、<dd>タグや属性情報やCSSセレクターでも抽出が可能です。
それぞれ試してみましょう。
➀ddタグで抽出

エライ沢山出てきました。見切れてますが、下の方に出てきますので正解は正解です。笑
➁属性情報(dd + class属性)
属性情報というのは、タグ情報ではないがclassやid、aタグに記載されるURLが記載されるhref属性、IMGタグに記載されるsrc属性やalt属性を指します。
classやidはCSS(カスケーディング・スタイル・シート)と言って、Webページのデザインをコントロールするための言語です。
タグ内だけでなく、複数の範囲にスタイル(色や形、レイアウト等)を適用させる時に、idやclassで範囲を指定してCSSを記述します。
つまり、欲しい情報の塊とかぶる可能性が高いわけです。
では、dd タグとclass情報で抽出してみましょう。記載方法ですが、以下のように書きます。
data = soup.find_all("dd", class_="ymuiEditLink mar0")実は()というのも、リストのような型の一つでタプル型といいます。タプルも複数の値が格納可能です。出力するための関数printや、BeaurifulSoupのfind_allメソッド等、先ほどから関数にくっつけて()を記載しているのは、関数にタプル型で引数(インプットとなる値)を渡しているのです。
複数引数を渡せる場合は、,(カンマ)で区切って渡すことが可能です。
printであれば、この値を出力してね。find_allメソッドであればこのタグ情報、あるいはこういう属性情報を持ってるデータを抽出してね。ということになります。
※但し、とれる引数の数は関数によってあらかじめ定義されているものがあるため、引数不要、1個しか引数を設定できない、2個まで、何個でも・・・のような違いがあり、定義と異なる場合エラーとなります。
では、上記のタグ+クラス情報で抽出をしてみましょう。
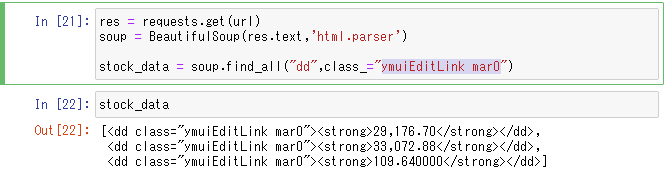
ずばりと取れました。
それ以外にもCSSセレクターで抽出する方法もあるので、知りたい方はググってみてください(あ、投げた)
5.CSVファイルへの保存
ここまでだと、データを抽出して終わりです。でも、そんなの普通にWebページ開けばいい話ですよね 笑
それではつまらないし、実用的ではないので、CSVにデータをタンキングしていく方法を記載します。
PythonにはCSVという標準ライブラリが存在していて、インポートするだけでリスト形式のまま、CSVファイルに行単位に書き込んだりすることができます。勿論、読み込んだりすることもできます。更にJupyterNotebookを使うと、CSVファイルを表形式で読み込めるのでそのまま集計やグラフ作成ができたり便利です。
まずは、先ほど抽出できた日経平均・TOPIX・ダウ平均をCSVファイルに保存してみましょう。単品で書き込む場合は、以下の通りです。
with open(ファイルパス, '書き込み・追記') as 変数:
変数.write(書き込み対象)実際にやってみましょう。testというフォルダを用意しました。(空フォルダ)

先ほどddタグとクラス属性で抽出したリストの先頭にある、日経平均株価情報を保存してみます。

data変数(変数名は何でもOK)に日経平均株価(stringでエレメントタグからテキスト情報を取り出す)を格納します。
ファイルパス(testフォルダ内のtest.csvというファイル)を記載、「w」で書き込みを指定しています。
実行後、フォルダを開いてみると。

test.csvファイルが作成されています。中身を確認すると、、、

データが格納されています。ちなみに、「w」を「a」に変えると追記となり、データ追記が可能となります。(「w」だと常に上書きされます)
「w」でもう一度実行すると・・・

データは一つしかありませんが、aに変えると・・・

追記されました。なお、リスト形式で書き込むにはCSVライブラリを使います。
with open(ファイルパス, '書き込み・追記') as 変数:
writer = csv.writer(変数, quoting=csv.QUOTE_MINIMAL)
writer.writerow(書き込み対象リスト)変数writerにcsv.writerメソッドに引数で、変数とクォート指定(文字を囲む)を渡します。変数writerに対して引数として書き込み対象のリストをwriterowメソッドに渡します。
多分、説明が下手くそなのでCSVファイルの書き込み方はこのサイトを見てみてください。(あ、投げた)
では、取得日と日経平均株価、TOPIX、ダウ平均をヘッダーをつけてCSVファイルに書き込んでみましょう。

➀今日の日付を取得
インポートしているdatetimeモジュールを使って、今日の日付を取得しています。datetimeモジュールの詳しい説明はコチラ。(ぶん投げた)
➁リスト内表表記で日経平均株価・TOPIX・ダウ平均をリスト変数に格納
stock_data(タグエレメントを格納したリスト)リストをループ処理で、テキスト情報にして、stock_datasというリスト変数に格納しています。
以下のような書き方でもできます。
stock_datas = []
for data in stock_data:
stock_datas.append(data.string)空のリストを用意して、appendメソッドでリストに1個ずつ値を追加してます。
➂リストの先頭に今日の日付を追加
➀で取得した今日の日付を、insertメソッドでリストの頭(インデックス0)に挿入しています。
➃ヘッダー情報をリスト形式で用意
リストはこのように定義することも可能です。
➄ファイルの存在有無をチェックするため、osモジュールをインポート
ファイルが既に有る場合は、データを追記するだけでいいですが、無い場合はヘッダー情報をまず書き込みたいので、ファイル存在有無をチェックできるosモジュールをインポートしています。存在有無を確認するコードは以下の通りです。
os.path.exists(ファイルパス)➅ファイルが存在しない場合は、ヘッダーと株価情報を書き込み、ファイルが存在する場合は、株価情報のみ書き込み
ここで登場するのが条件式です。
条件式は簡単に言うと、分岐です。例えば、なんでもいいけど、何か現実世界のものをプログラムにしてみましょう。
では、例えば車をプログラムにしてみましょう。車の機能は、いまや色々ありますが、めちゃくちゃシンプルにすると、「アクセルを踏めば進む」、「ブレーキで止まる」です。
条件式はif文で記載します。if文は以下のように書きます。
if 条件式➀(アクセルを踏む):
処理1(速度を上げる)
elif 条件式➁(ブレーキを踏む):
処理2(速度を減速する)
else:
処理3(変化なし)ifとelseだけでもいいです。複数条件がある場合、elifはいくつでも書けます。これを使って、ファイルがあったら、なかったらと書き分けています。
先ほどまでのプログラムを頭から全て記載すると、以下の通りです。
実行してみましょう。
import requests
from bs4 import BeautifulSoup
import datetime
import csv
url = 'https://finance.yahoo.co.jp/'
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
stock_data = soup.find_all("dd",class_="ymuiEditLink mar0")
#今日の日付を取得➀
get_date = datetime.date.today()
#リスト内包表記で、日経平均株価・TOPIX・ダウ平均をリストに格納➁
stock_datas = [data.string for data in stock_data]
#リストの先頭に今日の日付を追加➂
stock_datas.insert(0, get_date)
#ヘッダー情報をリスト形式で用意➃
header = ['取得日','日経平均株価','TOPIX','ダウ平均']
#ファイルの存在有無をチェックするため、osモジュールをインポート➄
import os
#ファイルが存在しない場合は、ヘッダーと株価情報を書き込み
#ファイルが存在する場合は、株価情報のみ書き込み
if not os.path.exists('test/test.csv'):
with open('test/test.csv','w',newline='') as f:
writer = csv.writer(f, quoting=csv.QUOTE_MINIMAL)
writer.writerow(header)
writer.writerow(stock_datas)
else:
with open('test/test.csv','a',newline='') as f:
writer = csv.writer(f, quoting=csv.QUOTE_MINIMAL)
writer.writerow(stock_datas)フォルダにできたCSVファイルを開いてみましょう。

はい、できております。
条件式が正しく動くか、再度プログラムを実行してみてください。(5回ほどw)

ちゃんと動いてますね。(実行しすぎました)
ではこの後、ちょっとこれを使って表をつくったり、グラフ化したりしたいので、少し中身をいじります。

※これは全くもって架空の値なので、くれぐれもご留意ください(当たり前か)
では、今度はこれを読み込んでいきます。
6.Pandasを使ってCSVファイルを読み込み
Pandasというのはデータフレーム(表形式)を扱える、便利なPythonのライブラリです。Anaconda環境の方は一緒にインストールできているので、そのままインポートできます。そうでない方もpip installで無料でインストール可能です。
import pandas as pd
df = pd.read_csv(ファイルパス)と記載します。as pdという書き方は、pandasというライブラリをpdと短縮して使えるようあだ名をつけていると思ってくれればOKです。
そして、適当な変数(df)にread_csvメソッドにファイルパスを引数で渡して、表データを格納します。やってみましょう。

はい、エラー出ました。UnicodeDecodeErrorと記載されてます。
1行目のファイルを読み込んだ時点でエラーが発生してます。
エラー表示の下の方を見ると・・・
![]()
と記載されています。エラーが出た時は、エラーが出た箇所と、最下部のエラーメッセージを確認しましょう。「utf-8は、デコードできません」と書いてあります。デコードは復元、エンコードは符号化です。
簡単に言うと、utf-8という文字コードはPandasの表形式で扱えないですわ。ということを言っています。
コンピューターの世界は、0,1の2進数で動いています。これを人間が読めるように符号化したのが文字コードであり、urf-8はその文字コードの一種です。Shift-JIS形式であれば扱えるため、読み込み時にShift-JISにエンコードする必要があります。(もしくは、そもそもShift-JIS形式で書き込む)
今回は、Shift-JISでエンコードして開くよう引数を追加します。

このように、pandasをつかうことで、簡単に表形式で取り込めます。
では、日経平均株価を取り出して、日ごとの変動額を算出したうえで、グラフにしてみましょう。
以下の通りです。

pandasのデータフレームは、列や行単位でリスト型として取り出し、扱うことができます。
まずは、変動額を求めるべく、ループ処理で文字列で格納されている日経平均株価をfloat型(浮動小数点)に変更する際に邪魔になるカンマをreplaceメソッドでスペースに変換。
リストに格納した変換後の値を更に、ループ処理でリストに格納していくといったことをしています。また、最後グラフ化する際にも、文字列だとグラウフにプロットできないので、日経平均株価列については変換後の値に更新(上書き)を行っています。

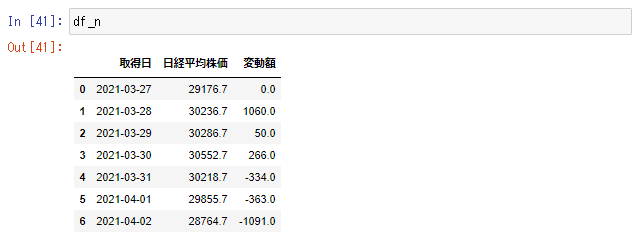
そして、取得日・日経平均株価に絞った新しいデータフレーム(df_n)を作成。先ほど求めた差額リストを変動額というタイトルをつけて、df_nに列追加しています。
df_nを見てみると、以下のようになってます。
最後に、グラフ化してみましょう。日経平均株価の折れ線グラフと、変動額の折れ線グラフをそれぞれ描画してみます。(x軸を日付、それぞれの値をy軸に設定)
まずは変動額でグラフを描画します。
![]()
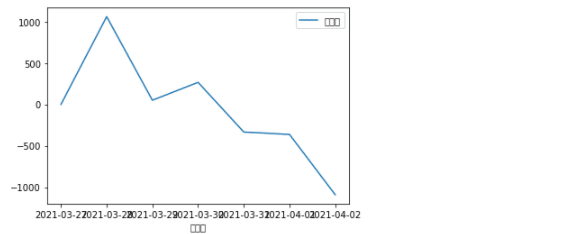
次に、日経平均株価でグラフを描画します。

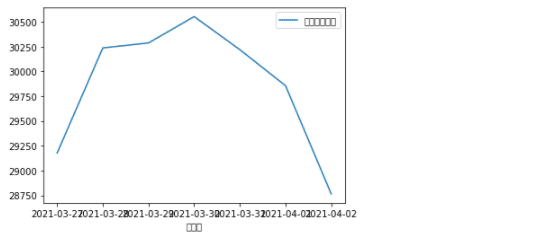
本日は以上となります。読んでいただきありがとうございます。
この記事が気に入ったらサポートをしてみませんか?