
PythonでWebスクレイピング(その➀)~まずはWebから抽出してみる

正直、基礎をひたすらやってもつまらないです。笑
一番いいのは、何かを作ってみて、「ここどうなってるんだろ?」というところを自分なりに調べて理解し、メモっておく。
そして、また何かに取り組む。
この繰り返しです。
1.Pythonでスクレイピングをしてみよう
今日は、比較的簡単だと思うスクレイピングをやりながら、簡単に何をやっているかを説明。そして、後日基本となる部分を掘り下げる記事を追加していこうと思います。
まずは、手を動かすのが一番です。
2.スクレイピングって何?
一言で言うと、Webページから欲しい情報を抽出する行為です。
例えば、日経平均株価や為替の情報を引っ張ってきたり、色々なニュースサイトから新着記事のタイトルとURLを抽出したりすることができます。
簡単に原理に触れると、WebサイトはHTML言語で記載されています。(HTMLを詳しく知りたい人はコチラ)
HTMLはマークアップ言語といって、タグで囲まれた様々な要素の集まりで、Webサイトは構成されています。(<body></body>、<a href="XXX"></a>など、見たことある方もいると思います。)
(1) GoogleChromeでHTMLを見てみよう
例えば、Yahoo!JAPANのトップページをちょっと見てましょう。
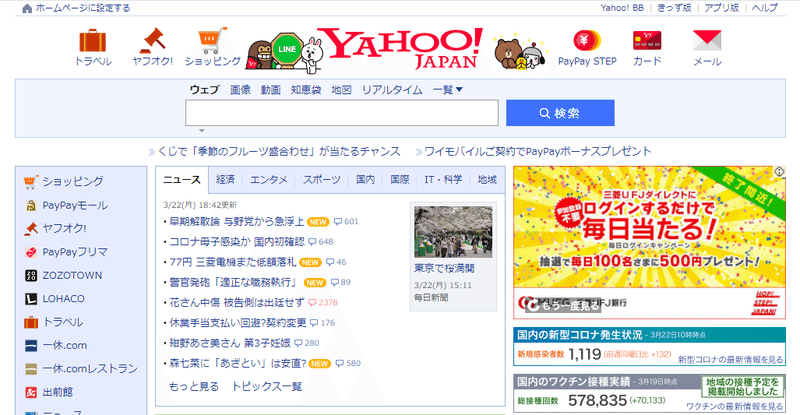
Yahoo!JAPANのタイトルを確認してみましょう。GoogleChromeでサイトを開き、該当箇所を右クリックして、「検証」というボタンをクリックしてみてください。
すると、、、こんな感じで、HTMLコードが表示されつつ、該当箇所は水色で表示されています。
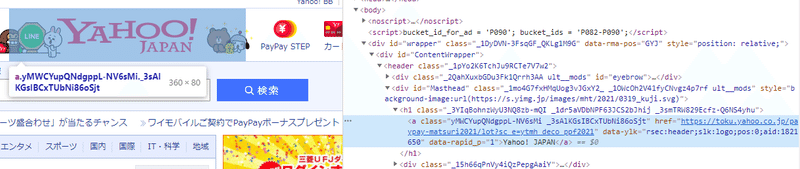
↓

このような形で、Webサイトに表示されている情報は、すべてHTMLタグで囲まれています。なお、タイトルは<h1>タグの下にある<a>タグで囲まれていることが分かります。
h1タグは、文字を大きく表示する見出し項目を囲うタグ。aタグは、他ページや他サイトにページ遷移させるURL要素を保持するタグです。
この、HTMLタグ等で、サイトのどこに記載されているかを特定し、該当情報を抜き出すのがスクレイピングの基本です。
3.どんなコードでスクレイピングができるの?
では、上のYahoo!Japanのタイトル情報から、URL情報と、タイトルの文字を抽出してみましょう。コードは以下の通りです。
#必要なライブラリをインポート➀
import requests
from bs4 import BeautifulSoup
#スクレイピング対象とするサイトのURLを変数に格納➁
url = "https://www.yahoo.co.jp/"
#インポートしたrequestsを使い、Getメソッドでレスポンスを取得➂
res = requests.get(url)
#インポートしたBeautifulSoupを使い、レスポンスのテキスト情報を変数に格納➃
soup = BeautifulSoup(res.text,'html.parser')
#BeautifulSoupのfindメソッドでh1タグを抽出し、変数に格納➄
title = soup.find('h1')
#h1タグで囲まれているテキスト部分をprint関数で出力➅
print(title.string)
#findメソッドでh1タグを抽出し、さらにその配下のaタグのhref属性を抽出し、変数に格納➆
link = soup.find('h1').find('a')['href']
print(link)実行結果は以下となります。
![]()
なお、覚えておいていただきたいのが、Pythonは#を頭につけると、コメント行となり、コードと見なされません。
よって、実質9行のコードで実現可能です。簡単ですね。
jupyter notebookでも、コマンドプロンプトでもコードを真似して打って実行してみてください。
Anacondaで実施されている方は、requestsとBeaurifulSoupはインストール済なのでそのまま利用可能ですが、インストール未済の方はコマンドプロンプトでPythonを起動する前に、以下のコードでインストール可能です。
・requestsをpip installする
pip install requests・beautifulsoup4をpip installする
pip install beautifulsoup44.コマンドプロンプトで1行ずつ実行しながら解説。
(1)必要なライブラリをインポートする
コマンドプロンプトで一行ずつ書きながら、解説していきます。
まず、Pythonは様々な処理をするためのライブラリが用意されており、上記のようにインストール等無料でできます。(素晴らしい)
まず、処理に合わせたライブラリをインポート(import)することが、大体プログラムの初めとなります。今回は、インターネットにリクエスト送信を行って、レスポンスを受領するための「requests」というライブラリと、取得したHTMLデータから、HTMLタグやCSSのセレクターで欲しい情報を削り取るための「BeautifulSoup」というライブラリを使います。
まずは、pythonを起動します。僕の場合は、Anaconda環境なので、conda activateで仮想環境を有効化してから、pythonと入力して起動してます。

次に必要なライブラリをインポートします。
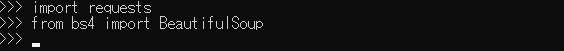
特にエラーも出てないので、成功です。
なお、なぜrequestsはimportの後に直接記載し、BeaurifulSoupはfrom bs4と頭に記載しているのでしょうか。同じディレクトリ(フォルダ)の関数はimportで利用できます。しかし、複数のPythonファイルが一つのディレクトリにまとまってパッケージ化されているような場合、このように呼び出す必要があります。
イメージとして、bs4というPythonモジュールをまとめたパッケージから、BeautifulSoupという機能をちょっくら呼び出しますと覚えておいてください。(忘れても、死ぬことはありませんが)
なお、importする時に以下のような呼び出し方も可能です。
![]()
呼び出した後にモジュールに「あだ名」をつけることでフルネームで呼ばなくても機能してくれます。この後、試してみましょう。
(2) 変数の活用
では、Yahoo!JAPANのアドレスを「変数」に格納しましょう。
なお、「変数」は前の記事(プログラミングで押さえるべきポイント)でも書いたプログラミングをするうえで、理解すべき重要なポイントです。
今回は、アドレス(URL)を格納するのですが、実は変数に格納しなくてもコードは実行できます。requestメソッドで、response情報を取得する際、取得が成功すると、通信ステータスが200番台となります。これをresponse.status_codeで取り出せるので、変数を使うバージョンと使わないバージョンどちらも試してみましょう。
まずは、使わないバージョン。

resという変数に、requestsモジュールのget関数でYahoo!JapanのURLから取得したレスポンス情報を格納し、status_code関数で通信結果を表示しています。「え、でもres変数使ってんじゃんよ。。。」って思ったそこのあなた。では、resという変数も使うのをやめてみましょう。
![]()
これで完全に変数を使ってません。
次に、レスポンス情報はどの文字コード※なのかをencoding関数で確認可能です。これも確認してみましょう。

はい。できました。ただ・・・、いちいち沢山文字打たないといけないですよね。(コマンドプロンプトは、キーボードの↑で過去の入力呼び出せますが・・・)
次に変数を利用してましょう。

どうでしょうか?記載する文字数が少ないですよね。
また、urlも直接コード内に埋め込んでしまうと、例えば違うサイトからレスポンス情報取得しようとした場合に、直接コード内の修正が必要となります。でも、こうやって変数に格納しておいて、例えばurl_2みたいな別の変数に違うサイトのURLを格納して使用すれば、urlとurl_2を使い分けるだけで済みます。
一回書いたコードも、後で必要な機能を足したり、逆に無駄をそぎ落としたり更新することが多々あります。その時に、修正箇所を押さえるのも変数を使うメリットの一つです。
またサラッと流してしまいましたが、変数urlに変数を格納する時に、”(ダブルコーテーション)で囲んでいるのは、文字列を扱う時のルールです。なお、'(シングルコーテーション)でも可です。
数値は、そのまま変数にセットできます。
(3) html情報の解析と必要情報の抽出
requestsモジュールのtext関数で、Webから取得したHTML情報をBeaurifulSoupに渡します。
![]()
BeautifulSoup関数に引数として、レスポンスのHTML情報と、HTML解析ツール(html.parser)を渡して、HTMLデータを解析した結果を変数soupに格納してます。
変数に格納しなくてもいいですが、格納する理由は先ほど説明した通りです。なお、変数名は自由に決めて大丈夫です。ただ、なんとなくBeautifulSoupはいつも変数名soupを使ってます。(変える理由があまりない)
では、HTML解析済のデータ格納されたsoup変数から、Yahoo!Japanというタイトルが記載されているh1タグのみを抽出し、テキスト情報を取得します。
![]()
find関数は引数として、タグ名を文字列で渡すことで該当タグの範囲のみを抽出可能です。さらにstring関数で、該当タグに囲まれたテキスト情報を抽出可能です。
次に、h1タグの配下のaタグにURL情報があるため、h1タグを抽出した後、さらにaタグで絞り込みをかけて、属性情報であるhref情報を取り出します。
![]()
aタグの中に、href属性がありリンク先となるURLが格納されています。
BeautifulSoupでは、[](スクウェアブラケットといいます)内に文字列で属性名を記載することで、属性を取得することが可能です。
今日は簡単なスクレイピングを解説しながら、主に変数について記載してみました。次回はもうちょっと突っ込んだスクレイピングについて、解説します。
この記事が気に入ったらサポートをしてみませんか?