
【統計学】エクセルでの回帰分析の出力結果を読み解く

エクセルで回帰分析を行うと
以下のような表がアウトプットされますよね。

この記事では、
この出力結果をどう読み解けばよいのかについて
分かりやすく解説していきます。
P値についても触れていきます。
回帰分析の出力結果で確認すべきポイントは3つです。
・回帰式の内容
・当てはまりの良さ
・回帰係数の有意性(P値)
順番に見ていきましょう
回帰式の内容を確認する
ご存知、回帰式とは以下の式のことです。
ここでは変数が1つである単回帰式を例としてあげています。

yは目的変数、Xは説明変数といいます。いずれも変数ですね。
回帰分析で求められるのは、aとbの値で、
aのことを回帰係数、bのことを切片と呼びます。
回帰分析の出力結果では、一番下に表示されています。

この出力結果によると
回帰式は以下のようになるということですね。

当てはまりの良さを確認する
当てはまりの良さとは、回帰式の精度の高さのことをいいます。
回帰式が、どれだけ、XとYの関係を正しく説明できているか?ということになります。
これはR2という決定係数で知ることができます。
決定係数は"基本的に"0〜1の値をとり、1に近いほど当てはまりが良いということになります。
(この「基本的に」というのは大事なことです。あとで説明します)
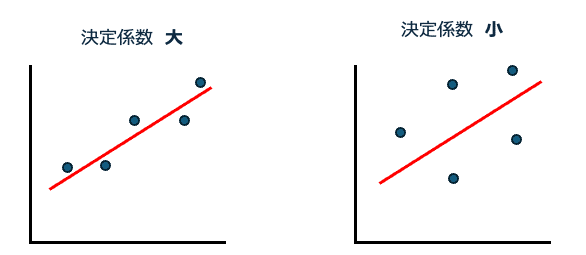
左の図では、
各データと回帰式の差(これを残差といいます)が小さく、
非常に当てはまりが良いと言えます。この時、決定係数は1に近くなります。
一方、右の図では、
残差が大きく当てはまりが良いとは言えません。決定係数は0に近くなります。
決定係数は、回帰分析の出力結果では、R2として出力されます。
R2はRの2乗という意味で、Rは相関係数を意味します。
つまり、決定係数は相関係数の2乗になるということです。
実は、決定係数は相関係数の2乗として求められるわけではありません。
決定係数には別の計算式(後述)があります。
たまたま一致するということです。
なお、決定係数が相関係数の2乗と一致するのは、回帰式を最小二乗法による線形回帰で求めた場合です。最小二乗法を使わない場合、決定係数はマイナスになる場合もあります。
だから、「決定係数は0〜1の値をとる」の前に、「基本的に」という言葉がつくのです。

この出力結果では、決定係数が0.2なので、あまり当てはまりは良くなさそうです。
なお、回帰分析の決定係数(R²)の計算式は以下のとおりです
R² = 1 - 残差平方和÷全変動和
上記の出力結果にあてはめると
R² = 1 - 0.1123 ÷ 0.1417 = 0.2074 となります。
以下がイメージです。
決定係数(R²)は回帰平方和÷全変動和と言い換えることもできます。

回帰係数の有意性を確認する
決定係数(R²)は、モデルの当てはまりの良さを示しますが、目的変数と説明変数の関係が統計的に有意であるかどうかを直接示すものではありません。
回帰係数の有意性検定により、目的変数と説明変数の間に有意な関係があるかどうかを確認する必要があります。
実際、説明変数が複数ある重回帰分析を行うと、中には、目的変数に影響を与えない説明変数がでてくる場合があります。
回帰式の精度をあげるには、こうした有意性の低い説明変数は式から落とす必要があります。
回帰係数の有意性とは
回帰分析において、各説明変数が目的変数に対して統計的に意味のある影響を与えているかどうかを示すものです。
意味のある影響があるとは、回帰係数が0ではないということです。
回帰係数が0でないと言うことができれば、その説明変数が目的変数に影響を与えていると言えますよね。
有意性の確認方法

回帰係数の有意性は、出力結果のP値で分かります。
P値が極端に小さければ、回帰係数は統計的に有意と判断されます。
ここで言う「極端に小さい」を具体的にどの水準とするか?の問題が残ります。この水準のことを有意水準と言い、一般的には5%とすることが多いです。
例えば、有意水準を5%とした時、
P値が0.05を下回っていれば、統計的に有意であると言います。
上記ではP値は0.013なので、回帰係数は統計的に有意となり、説明変数Xは目的変数に有意に影響を与えていると言うことができます。
P値の意味
最後に、そもそもP値とは何か?
もう少し具体的にその意味を見ていきたいと思います。
回帰分析におけるP値は、回帰係数が実際には0であるという帰無仮説のもとで、観測されたデータ(または、それ以上に極端なデータ)が得られる確率を示す統計量です。
イメージは以下です。(グレーの領域がP値になります)

新薬の効果を調べる例を使って説明しましょう。
状況:
ある会社が新しい頭痛薬を開発しました。100人の患者にこの薬を投与し、70人で症状が改善しました
P値の意味:
P値は、「この薬には効果がない(プラセボ効果と同じ)」と仮定したとき、100人中70人以上で症状が改善する確率を示します。
解釈:
P値が小さい 70人以上で改善するのは偶然では説明しづらい。薬に効果がある可能性が高い。
P値が大きい 70人程度で改善するのはプラセボでも起こりうる。薬の効果を主張するには証拠が不十分。
つまり、P値は「薬に効果がないとして、この結果(またはより極端な結果)が偶然起こる確率」を表します。
P値が小さいほど、薬に効果があると考える根拠が強くなります。
P値の求め方:
回帰モデルを構築します。
各係数の推定値と標準誤差を計算します。
t統計量を計算します:t = (係数の推定値) / (係数の標準誤差)
自由度(通常はサンプルサイズから予測変数の数を引いたもの)を考慮し、
t分布を用いてP値を算出します。
まとめ
エクセルの回帰分析の出力結果を読み解く重要なポイントについて解説してきました。
回帰式の内容、当てはまりの良さ、そして回帰係数の有意性という3つの要素を理解することで、データ分析の質を大きく向上させることができます。また、これらの概念を適切に理解し活用することで、より深い洞察を得ることができ、データに基づいた意思決定の質を高めることができるでしょう。
統計分析は時として複雑に感じられますが、一歩一歩理解を深めていくことで、強力な分析ツールとなります。
この記事が、皆さんのデータ分析スキル向上の一助となれば幸いです。
いいなと思ったら応援しよう!
