
有価証券報告書から女性管理職比率を抽出した

2023年3月期の有価証券報告書から、上場企業は、女性管理職比率を開示することが義務付けられました。
そこで、本邦初となる試み、2023年3月期の有価証券報告書の女性管理職比率をPythonで抽出しました‼️
最初にお断りしておきます。
企業によっては、データを正しく取得できなかった可能性があります。
なぜなら、女性管理職比率は、構造化されたデータではないからです。
構造化されたデータであれば、取得する位置が決まっています。この場合、正しくデータを取得できます。
女性管理職比率は、構造化されていないので、テキストデータから、法則性を見つけ出し、正規表現などを駆使して、抽出しています。
提出会社か、筆頭の連結子会社のいずれかの比率になります。
念のため、複数の企業で、データの確からしさを目視でも確認しました。
そして、Pythonのプログラミングだけでは、うまくデータを捉えられなかったケースについて、手で数字を直しています。
この記事では、前半で、集計結果をご紹介するとともに、後半で、どのように女性管理職比率を取得したか?、その方法をご紹介します。
集計対象企業
2023年3月期有価証券報告書を提出した企業2551社のうち、データを取得できた企業1,981社が集計対象企業になります。
この差額(570社)には、そもそも企業規模の関係で女性管理職比率の公表義務が無い企業が含まれています。
2,551社の有価証券報告書は、金融庁の有報閲覧サイトEDINETより、APIを使って一括取得しています。そこから、各社のテキストデータを抜き出し、CSVファイルに落とし込む作業を行なっています。
1 . 集計結果
女性管理職比率の平均値・中央値・最大値

厚生労働省が昨年10月に行なった調査によれば、従業員数10人以上の全国3,000社の企業における女性管理職比率の平均値は12.7%でした。
上場企業等の方が低いですが、大きく違いはありませんでした。
この手の統計によくある話ですが、中央値はやはり相当低いですね。
女性管理職比率100%は、燦キャピタルマネージメント株式会社という会社1社だけでした。
女性管理職比率ごとの企業数の分布

右に裾野の広い分布です。
上場企業といえども、多くの企業は、まだまだ低い水準です。
比率が高い上位10業種
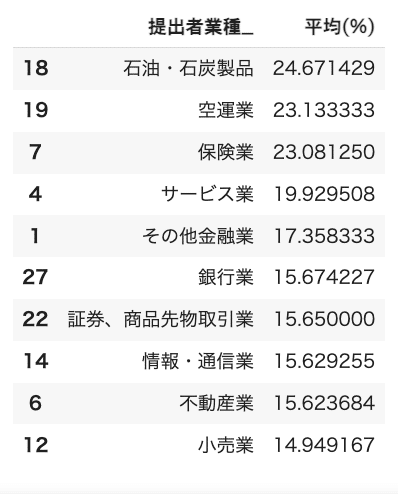
石油・石炭製品の比率が高いのは意外でした。
保険や銀行、証券などの金融関係が上位にいるのは頷けますね。
比率が低い下位10業種
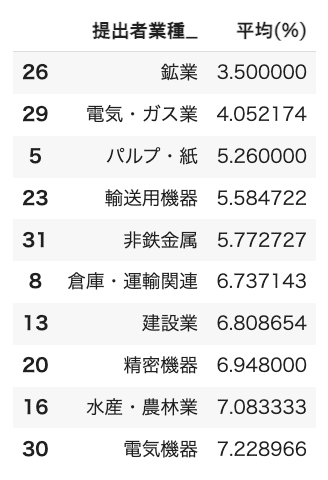
伝統的な産業や装置産業の比率が低いですね。
2. 女性管理職比率の取得方法
ここからは、どのようにして比率を取得したかをご紹介します。
有価証券報告書のどこに記載があるか?
女性管理職比率は、有価証券報告書の項目の一つである従業員の状況に記載があります。
実際の有価証券報告書はこのように表形式になっていて、整理されているように見えます。
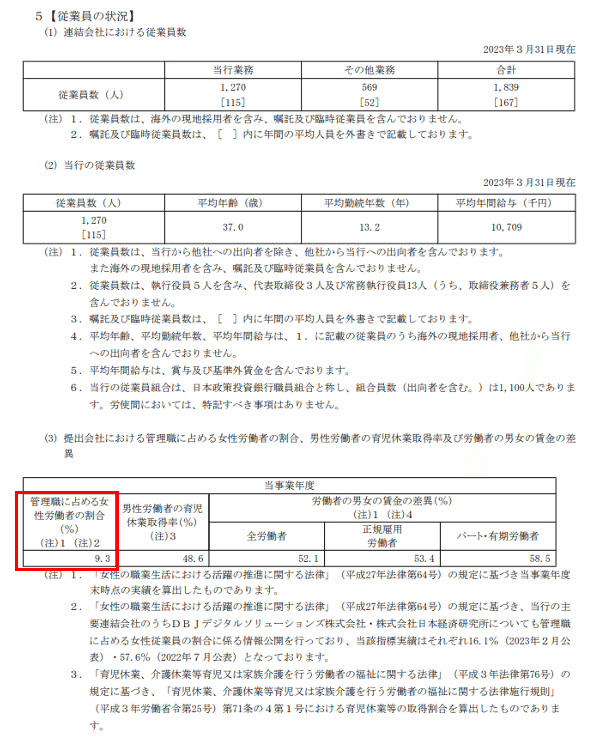
赤囲み部分が、女性管理職比率になります。
現状、女性管理職比率のデータは構造化されておらず、テキストデータに落とし込んで、そこから抽出するしかありませんでした。
テキストデータはこんな感じです。上記と違って、目視は大変です。

具体的な抽出方法
いくつかの有価証券報告書のテキストデータを見て、法則を発見。その法則に基づき、Pythonコードで抽出しました。
【法則1】
女性管理職比率は、「管理職に占める女性」という言葉に続いて、最初に現れる数字だということです。
この部分の記載、正確には、「管理職に占める女性労働者の割合」と書くべきみたいですが、「管理職に占める女性従業員の割合」や、「管理職に占める女性の割合」と書いている企業もありました。そこで、「管理職に占める女性」という言葉を検索ワードにしました。
【法則2】
女性管理職比率は、必ず小数点第1位まで表されるということです。
30%や50%のような、厳密には小数点を持たない数字でも、ちゃんと、30.0、50.0と表記されます。
これらの法則に基づき、テキストデータから、女性管理職比率を抽出するPythonコードをChatGPTに考えてもらいました。
以下は、最終的にChatGPTに提案を受けた、テキスト文から、女性管理職比率を抽出する関数です。
def extract_number(text):
# 1. 「管理職に占める女性」に続く数字で、小数点を持つ数字を探す
pattern = r'管理職に占める女性.*?(\d*\.\d)'
match = re.search(pattern, text)
if not match:
return None
decimal_part = match.group(1)
integer_part = decimal_part.split(".")[0]
# 2. 小数点第1位の数字を取得
number = decimal_part
# 3. 整数1位の数字を確認して、これが半角数字であれば取得
if len(integer_part) >= 1 and integer_part[-1].isascii():
number = integer_part[-1] + "." + decimal_part.split(".")[1]
else:
return number
# 4. 整数10位の数字を確認して、これが半角数字であれば取得
if len(integer_part) >= 2 and integer_part[-2].isascii():
number = integer_part[-2:] + "." + decimal_part.split(".")[1]
else:
return number
# 5. 整数100位の数字を確認して、これが半角数字で1であれば取得
if len(integer_part) == 3 and integer_part[-3] == '1':
number = integer_part + "." + decimal_part.split(".")[1]
else:
return number
return number
各社でテキスト文の仕様が異なるため、ある企業では抽出したい数字を抽出できるが、別の企業では抽出できない…..そんな試行錯誤の繰り返しでした。
この関数にたどりつくまでに、2週間ぐらいかかりました。
ちなみに、この関数でも一部、抽出できない数字が存在し、それは手で修正しています。
さいごに
ここまでお読みいただきありがとうございます。
繰り返しですが、2023年8月時点では、このような分析をしてる人(会社)はいないのではないかと思います。
今後、おそらく、どこかのコンサル会社が正確な数値をまとめてくると思いますが、そこで答え合わせしたいと思います。
よろしければサポートお願いします! いただいたサポートはクリエイターとしての活動費に使わせていただきます!