
政治家や活動家の発信を見逃さないために、誰でも使えるツールをつくる③

前回までで、GitHub に SATwi という定期的なツイート取得自動化ツールと、Google Colaboratory に特定ターゲットのデータをいっぺんにごそっと抜いてくる手動実行ツール(Jupyter Notebook)を準備した。本記事はこれらの問題点、およびその解決アプローチについて検討する。
問題点
前提として、このツールにはミクロ的な問題とマクロ的な問題が存在している。すなわち、このツール自体あるいはこのツールを扱う個人が抱える問題と、このツールを皆が使い始めたときの社会的影響の問題である。
ミクロな視点として
大きく分けて ①Twitter API の Tweet caps / Rate Limit という制限 ②ツールが未成熟であること の二つである。
①についてはどうすることもできない。API が無料で利用可能なのも Twitter 社によるノブリス・オブリージュでしかないため、ここの制限を大幅に緩和したいと考えるのであれば、適切な額を支払ってアクセス権を得る他ないだろう。
②について、これはあくまで現段階での問題でしかないが、今後どのように既存のツール・サービスと異なる価値をしていくか?というのはかなり難しいと考えている。例えば SocialDog とか Twilog なんかは 分析・検索・通知・代理操作まで提供している。そしてそれはすべてブラウザ上で完結するため、技術的・精神的な障壁がほとんど存在しない。
現状の SATwi では、残念ながら「証拠保全」としての役割しか持てていない(少なくとも表面上は)。もちろん私のようにプログラミングの技術がありデータをそれなりに扱える人々にとっては、このように簡単にたくさんデータを集められることは輝きを秘めた原石のように見ることも出来るのだが、その素養がない一般の人々にはほとんど無価値に感じられてしまうだろう。
もっとわかりやすい価値……検索ができること、統計情報がひと目で分かること、傾向を分析できること、"映える" 結果を画像として得られること……といった機能が必要とされている。
マクロな視点として
仮に、ミクロな問題が解決される/されないにかからわず、広く大衆に使われるようになったとしよう。このとき、新たな問題が表出することが想定できる。
まず確実に言えるのは、個々人が連携できないということだ。先述したように Twitter API を利用している以上取得できるツイート数には上限があり、個人の範疇において追跡できるアカウント数も限られてくる。そうなると自ずと他人との協力、すなわち追跡したいアカウントを分担するという手法を取ろうとかんがえるだろうが、現状これを達成する手段は提供できていない。結局、メールやDM等を通じて直接やり取りした上で協力してもらうという形になる。
少人数のチームとして SATwi を使う場合にはそれでよいだろうが、もっと大きな不特定多数のクラスタ内で SATwi を使いたいとなったときに、今のままではあまりにも不便だし、ほとんどの場合において不可能とも言えるだろう。
次に、どうにかして多人数で分担協力してデータを集めたとして、それをどうやって集約し分析するか?という問題がある。Twitter の規約上、得られたデータをそのまま個人間でやり取りすることは許されていないし、シリアル化(サーバに問い合わせてコンテンツを得られるような IDに変換)されていても一日あたり最大5万までという制約がある。もちろんその条件下で ツイート ID をやり取りすることも出来るだろうが、大幅に二度手間が生じて大変に不便極まりない。
分析するためにそんなに大量の ID は必要ないのでは?という疑問もあるかもしれない。たしかに対象を減らしたり取得ツイート数を少なく見積もったりできればこの問題は生じ得ない。しかし、Twitter 分析の先行事例として鳥海不二夫 先生の Yahoo 記事などを見るに、誠実に分析をやろうとすると 1 万 ~ 10 万 程度のアカウントを対象にする必要が出てくる。ここからさらにツイートを数百以上集めることを考えると、手間がかかるどころのハナシではないことが想像できるだろう。
(※他にもいくつか想定できるが、まだその前提となる機能が開発できていないためそちらへの言及は控える)
解決手段の検討
改めて問題を簡潔に整理すると、以下のようになる:
Twitter API の制限(個人単位では回避不可能)
ツール自体が開発途上なため、魅力が伝わらない
不特定多数で分担できない
不特定多数が協力できない
API については無料の範囲では解決しようがないので目をつぶるとして、残る三つについては、なんとかして技術で解決できないだろうか?
魅力が伝わらない →「見える」機能をつくる
得られたデータはすべて JSON として保存されているが、一般的にはそもそも JSON という形式のデータでさえよくわからんとなってしまっている可能性が高い(というか多分そう)。況や GitHub のリポジトリ内検索なんかもうまく使えないだろうから、ただデータを集めるだけでは本当に「なんの価値もない」と感じてしまうのも致し方ないのかもしれない。一方でそのままの生データを表に出してしまうと、Twitter の規約に触れてしまい BAN されるおそれがある(し、データを集めて活用とする側に瑕疵があっては弱点として狙われてしまうリスクも)。
考えうる方針としては、得られたデータを検索・分析・可視化するツールを別途作成して使うことだが、これは非プログラミング人材に無理を強いることになりかねない。もし使わせようとすれば大量の補足ドキュメントが必要になるだろうが、書くのも手間だし読むのも辛いだろう。やはりこれについても、極力人の手が入らないようにしたい。
となるとやはり、SocialDog とか Twilog といった先行事例を模倣するしかないということになりそうだ。すなわち、必要とされる機能は網羅的に実装しつつ、生データは表に出さないようにした上で、ブラウザ上で完結させる。一見無理難題なようにも思えるが、これまでよりさらに GitHub Actions を使い倒すことでどうにかならないだろうか?
データの分析は Python のライブラリ群でなんとかなるだろう。「生データを表に出さず」に「ブラウザ上で完結」すなわちインターネット上にウェブサイトとして公開するにはどうすればいいのか思案していると、GitHub Pages を使えばいいはずだということに気がついた。Free 版だと Private リポジトリには Pages が使えないので、そちらの回避策さえ提示できれば誰でも使えるようになりそうだ(そして実際にその算段もついた)。
長々と書いたが、つまりは ①検索・分析・可視化等の機能を Python で実装する ②得られた結果データを元にウェブページを作成する ← GitHub Actions + GitHub Pages でどうにかする ということだ。Free 版でも使えるようにするという制約に注意しつつ、どうにかなんとかなりそうな方針が立てられたようにおもう。
不特定多数のクラスタで分担・協力ができない→「集める」場所をつくる
ごく小規模であれば、1 on 1 やらグループを作って DM でやり取りできるが、お互いに何も知らず接点もない状態でも協力できるような仕組みが必要になるだろう。となると、皆が集まる場所あるいは「掲示板」的なものが必要となる。個々人に分散されている力を一時的に中央へ集めるイメージだろうか。
中央にサーバを建ててそこに集めるという大方針でいえば、考えうるアプローチはおおよそ二つだろう;
①(本人に代わって)生データを扱う権利を供与する
②個々人で処理済みの結果データを供与する
本人に代わって生データを処理する仕組み
これは利用者が GitHub のアカウントを持っているという前提のもとに、中央サーバが GitHub 連携を通して利用者の権限を取得し、本来は Private リポジトリにあるデータにも触れられるようにする方策である。言い換えれば、個人が得たデータをすべて中央サーバへ集めるアプローチだ。
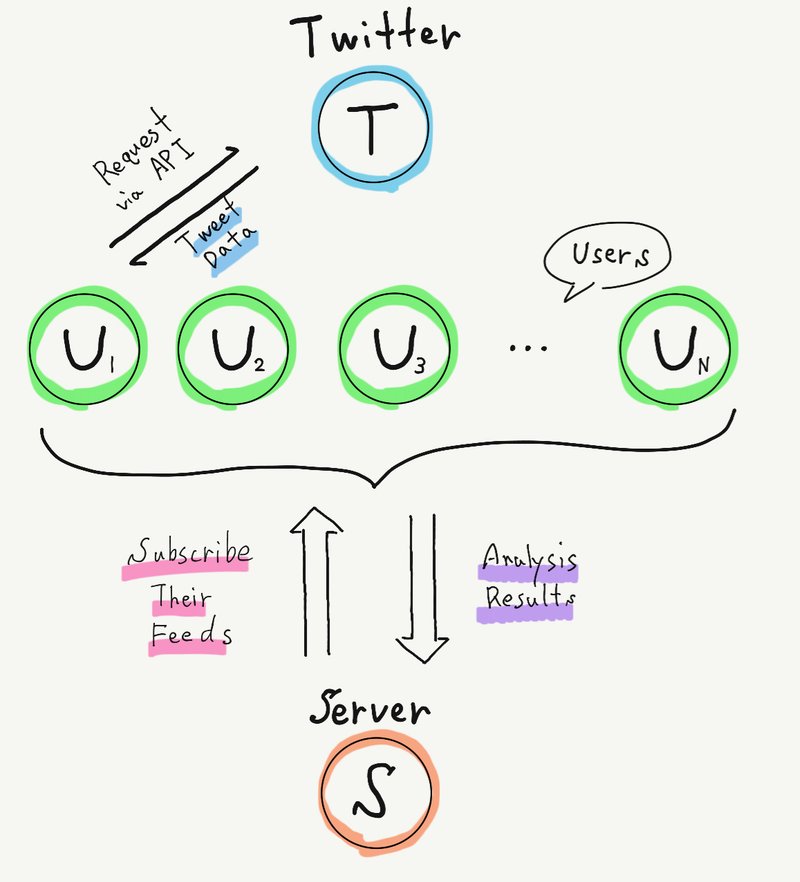
これは限りなく黒に近いグレー(と思いたいがおそらくは黒)なやり方だが、データを直接やり取りする方法がないわけではない。Twitter (以下、T とする), 利用者(以下、U とする)、中央サーバ(以下、S とする)の関係を記述すると次の通りとなる:

T - U 関係: U は API を介して T からデータを得る。もちろんこの際には T の規約を遵守せねばならない。T は U の情報を握っているので、規約違反があればすぐに BAN することができる。
U - S 関係: U は S の提供するウェブページ上で GitHub 連携を行なうことで、S に対して Private リポジトリへのアクセス権を付与できる。S はその権限を行使して、 U の Private リポジトリに「U の代理として」アクセスし、「U が T から得たデータ」を取得できる。
S - T 関係: このとき S は U が T の規約に違反しており BAN される可能性があることを知っているが、これを通報せずもみ消すことができる(とはいえ、そもそも S は U の T 側における情報を知りえないために、個人を特定して通報できないはずだ)。T は S が U に対して "規約を意図的に破らせている" ものとして処罰したいが、その証拠が得られないため行動を起こせない。もちろん S は T のサービスを利用していないかぎり、規約違反も存在し得ない。
T と S の間を U が仲介するような図となるが、U が意図的に規約を破っている(S が U に規約を破らせている)ことに目をつぶれば、法的にも問題はないし(表面上は)誰も規約を破っていない状態が保たれる。証拠がないので T は U を罰せないし、アカウントがわからないので S は U を報告できない(し、するインセンティブもない)。
処理済みの結果データだけ集める仕組み
さすがに裏で見つからないとはいえ、明らかに意図的かつ強制的に規約を破るようなことをやっていたら訴訟リスクが怖いということもあり、別の方法を考えた;各個人で分析まで行なって結果データを公開し、そのURLを集約することで中央サーバにデータを集める仕組みだ。
〈「見える」機能をつくる〉とも関連してくるが、GitHub Actions + GitHub Pages を使えば、生データを非公開にしたまま分析結果データを共有できるし、更新結果を通知できる仕組みも整えられそうなことがわかった。
まずは、個々人でデータを収集し、必要な分析を行う(現在のところ、収集まではできているが分析する機能はまだ実装できていない)。こうして、Twitter から得た生データと、そこから得た分析結果データが手元に残る。この工程はすべて自動化し、GitHub Actions 上で実行される想定となる。
次に、分析結果データを外部へ公開する。そのためのページ構築を GitHub Actions で行い、その成果物をデータとともに GitHub Pages へデプロイすることになる。これで、外部の第三者からでも分析結果データ(を表示するページ) を閲覧可能となった。
最後に、中央サーバに分析結果データの在り処を伝える。これは、固定の URL でもよいが、どうせなら RSS / ATOM の仕組みを採用したい。これを使えば、単一の URL だけ渡せば済むし、更新があるたびに最新のデータを取りに行くことが出来る。定期的に中央サーバのクロウラーがRSSのリストを巡回し、更新されていれば新たなデータを取得しに行く……という流れである。
全体を通して、規約にも法律にも触れていないように見える。しいて言えば「分析」フェーズに倫理的な問題という視点で規約違反に抵触する可能性がある程度だろうか。まだまだ荒削りな構想だが、採用できる見込みは十分にあると考えられる。
まとめ
現時点での問題点の整理と、解決方法の検討を行なった。ミクロな問題については、開発を進めて機能を充実させることで改善が見込めることがわかった。マクロな問題については、まず一つ目にかなりグレーどころかほぼ黒となるアプローチが存在することを示した。こちらについては、法的な問題点を整理できるだけの知識がまだないため採用には踏み切れなかった。もう一つのアプローチとして、個々人が分析結果を保持しつつ GitHub Pages を採用し RSS Feed の形で中央サーバにデータを集約するという方式を示した。こちらは規約にも法律にも触れておらず、十分に採用できる見込みが高いことがわかった。
おわりに
今回は、記事①と②の問題点の整理とそれらに対する「悪魔的」解決法を考えた。結局のところ、〈未だ機能が少ないから早くもっと実装しろ〉という結論にしかならなかったが……。「悪魔的」と考えていたアプローチはよくよく考えると現実的に訴訟リスク高くね?となったので、実は SATwi 自体お蔵入りになるところだった。一方で生データではなく分析結果だけを公開し、それを GitHub Pages with RSS Feed で公開・更新する←それを中央サーバで集約するという方針であれば、多少の問題は残るにせよ、直ちに規約違反や法律違反にはなり得ないということがわかった(のでこの記事を書いた)。
次回、記事④ではより平和的な利用法に関する検討ならびに "もっと実行頻度を増やしたい" という人向けの Tips を提示する予定だ。そんなこと書くよりまずは機能を充実させる方が優先だろ!!!というツッコミはあると思うので、次の記事まではおそらく結構な間隔が空くと思われる。また、記事⑤が出るかどうかはわからないが、新機能をたくさん実装できた暁には、その解説等を書くかもしれない。
それでは皆様、よき Twitter Lifeを!
この記事が気に入ったらサポートをしてみませんか?