WSL2でLlama-3.1-70B-Japanese-Instruct-2407-ggufを試してみる

CyberAgentが先日公開した「meta-llama/Meta-Llama-3.1-70B-Instruct に基づいた日本語の継続的に事前トレーニングされたモデル」のGGUFフォーマット変換モデル Llama-3.1-70B-Japanese-Instruct-2407-gguf が公開されましたので、試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
venv構築
python3 -m venv llama3.1
cd $_
source bin/activateパッケージのインストール。
pip install torch transformers続いて、llama-cpp-python。cuBALSを有効にするために、
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-pythonでインストールします。アップグレードするときは
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python --upgrade --force-reinstall --no-cache-dirです。
2. GGUFフォーマットの選択
mmnga/Llama-3.1-70B-Japanese-Instruct-2407-gguf をみると .ggufのファイルが23種あります。
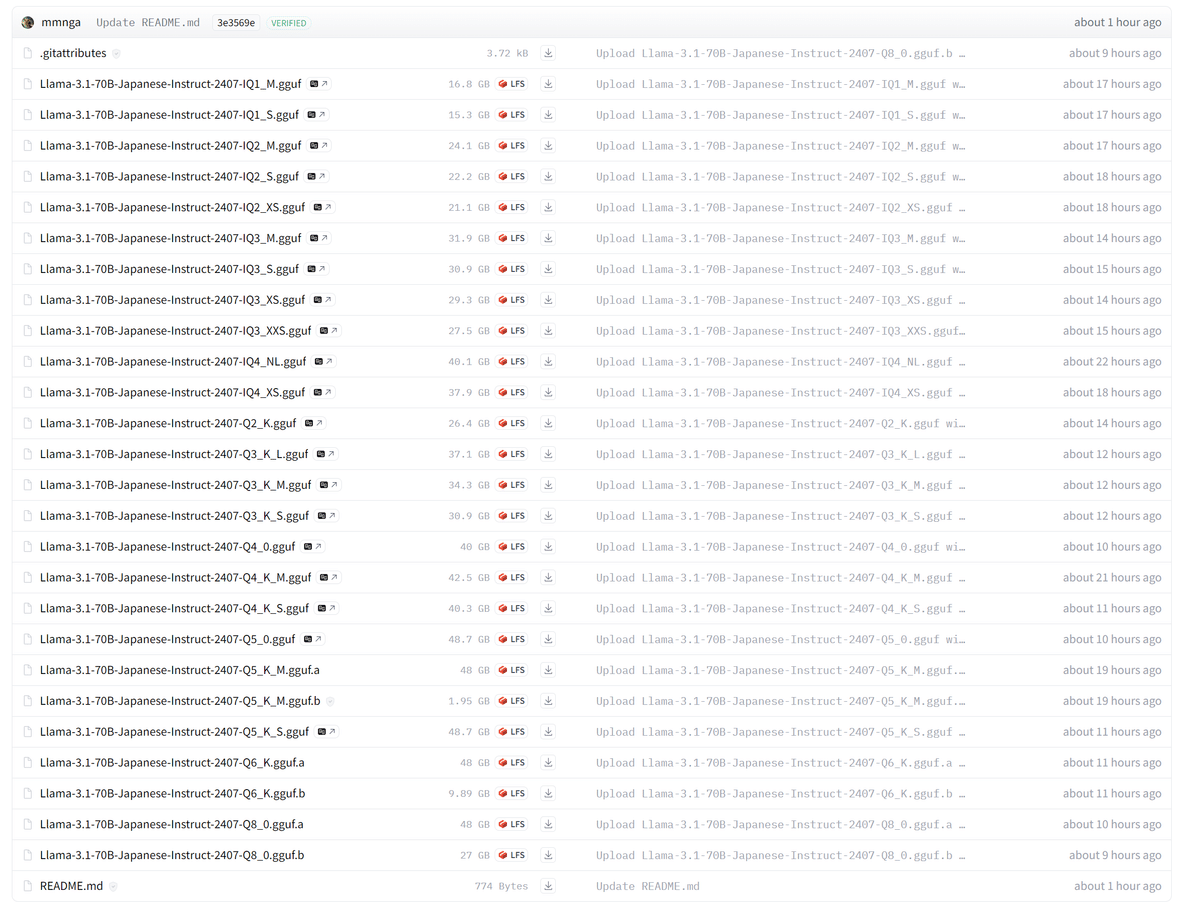
たくさんあるので、llama.cppの llama.cpp/examples/quantize/quantize.cpp の中を覗いてみるに、18行目から始まるQUANT_OPTIONS変数の定義がその対象のようです。
以下は、私の頭を整理するために、量子化&GGUFフォーマット別に分類したリストです。
今回は、4bit量子化で40GB未満のモデルである IQ4_XS で試してみます。
非量子化(のモデルをGGUFフォーマットに変換するために定義しているようです)
{ "F16", LLAMA_FTYPE_MOSTLY_F16, "14.00G, +0.0020 ppl @ Mistral-7B", },
{ "BF16", LLAMA_FTYPE_MOSTLY_BF16, "14.00G, -0.0050 ppl @ Mistral-7B", },
{ "F32", LLAMA_FTYPE_ALL_F32, "26.00G @ 7B", },レガシー量子化
{ "Q4_0", LLAMA_FTYPE_MOSTLY_Q4_0, " 4.34G, +0.4685 ppl @ Llama-3-8B", },
{ "Q4_0_4_4", LLAMA_FTYPE_MOSTLY_Q4_0_4_4, " 4.34G, +0.4685 ppl @ Llama-3-8B", },
{ "Q4_0_4_8", LLAMA_FTYPE_MOSTLY_Q4_0_4_8, " 4.34G, +0.4685 ppl @ Llama-3-8B", },
{ "Q4_0_8_8", LLAMA_FTYPE_MOSTLY_Q4_0_8_8, " 4.34G, +0.4685 ppl @ Llama-3-8B", },
{ "Q4_1", LLAMA_FTYPE_MOSTLY_Q4_1, " 4.78G, +0.4511 ppl @ Llama-3-8B", },
{ "Q5_0", LLAMA_FTYPE_MOSTLY_Q5_0, " 5.21G, +0.1316 ppl @ Llama-3-8B", },
{ "Q5_1", LLAMA_FTYPE_MOSTLY_Q5_1, " 5.65G, +0.1062 ppl @ Llama-3-8B", },
{ "Q8_0", LLAMA_FTYPE_MOSTLY_Q8_0, " 7.96G, +0.0026 ppl @ Llama-3-8B", },
k-quants
{ "Q2_K", LLAMA_FTYPE_MOSTLY_Q2_K, " 2.96G, +3.5199 ppl @ Llama-3-8B", },
{ "Q2_K_S", LLAMA_FTYPE_MOSTLY_Q2_K_S, " 2.96G, +3.1836 ppl @ Llama-3-8B", },
{ "Q3_K", LLAMA_FTYPE_MOSTLY_Q3_K_M, "alias for Q3_K_M" },
{ "Q3_K_S", LLAMA_FTYPE_MOSTLY_Q3_K_S, " 3.41G, +1.6321 ppl @ Llama-3-8B", },
{ "Q3_K_M", LLAMA_FTYPE_MOSTLY_Q3_K_M, " 3.74G, +0.6569 ppl @ Llama-3-8B", },
{ "Q3_K_L", LLAMA_FTYPE_MOSTLY_Q3_K_L, " 4.03G, +0.5562 ppl @ Llama-3-8B", },
{ "Q4_K", LLAMA_FTYPE_MOSTLY_Q4_K_M, "alias for Q4_K_M", },
{ "Q4_K_S", LLAMA_FTYPE_MOSTLY_Q4_K_S, " 4.37G, +0.2689 ppl @ Llama-3-8B", },
{ "Q4_K_M", LLAMA_FTYPE_MOSTLY_Q4_K_M, " 4.58G, +0.1754 ppl @ Llama-3-8B", },
{ "Q5_K", LLAMA_FTYPE_MOSTLY_Q5_K_M, "alias for Q5_K_M", },
{ "Q5_K_S", LLAMA_FTYPE_MOSTLY_Q5_K_S, " 5.21G, +0.1049 ppl @ Llama-3-8B", },
{ "Q5_K_M", LLAMA_FTYPE_MOSTLY_Q5_K_M, " 5.33G, +0.0569 ppl @ Llama-3-8B", },
{ "Q6_K", LLAMA_FTYPE_MOSTLY_Q6_K, " 6.14G, +0.0217 ppl @ Llama-3-8B", },
I-quants (SOTA 2-bit quants)
Important Matrixを計算前提のGGUFフォーマット。
{ "IQ2_XXS", LLAMA_FTYPE_MOSTLY_IQ2_XXS, " 2.06 bpw quantization", },
{ "IQ2_XS", LLAMA_FTYPE_MOSTLY_IQ2_XS, " 2.31 bpw quantization", },
{ "IQ2_S", LLAMA_FTYPE_MOSTLY_IQ2_S, " 2.5 bpw quantization", },
{ "IQ2_M", LLAMA_FTYPE_MOSTLY_IQ2_M, " 2.7 bpw quantization", },
{ "IQ1_S", LLAMA_FTYPE_MOSTLY_IQ1_S, " 1.56 bpw quantization", },
{ "IQ1_M", LLAMA_FTYPE_MOSTLY_IQ1_M, " 1.75 bpw quantization", },
{ "IQ3_XXS", LLAMA_FTYPE_MOSTLY_IQ3_XXS, " 3.06 bpw quantization", },
{ "IQ3_S", LLAMA_FTYPE_MOSTLY_IQ3_S, " 3.44 bpw quantization", },
{ "IQ3_M", LLAMA_FTYPE_MOSTLY_IQ3_M, " 3.66 bpw quantization mix", },
{ "IQ3_XS", LLAMA_FTYPE_MOSTLY_IQ3_XS, " 3.3 bpw quantization", },
{ "IQ4_NL", LLAMA_FTYPE_MOSTLY_IQ4_NL, " 4.50 bpw non-linear quantization", },
{ "IQ4_XS", LLAMA_FTYPE_MOSTLY_IQ4_XS, " 4.25 bpw non-linear quantization", },
3. 流し込むコード
ggufを読み込めるようにしたコードがこちら。query4llama-cpp.pyとして保存します。
コードの詳細(説明)は以下の記事を参照ください。
import sys
import argparse
from huggingface_hub import hf_hub_download
from llama_cpp import Llama, llama_chat_format
from typing import List, Dict
import time
# argv
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default=None)
parser.add_argument("--ggml-model-path", type=str, default=None)
parser.add_argument("--ggml-model-file", type=str, default=None)
parser.add_argument("--no-chat", action='store_true')
parser.add_argument("--no-use-system-prompt", action='store_true')
parser.add_argument("--max-tokens", type=int, default=256)
parser.add_argument("--n-ctx", type=int, default=2048)
parser.add_argument("--n-threads", type=int, default=1)
parser.add_argument("--n-gpu-layers", type=int, default=-1)
args = parser.parse_args(sys.argv[1:])
## check and set args
model_id = args.model_path
if model_id == None:
exit
if args.ggml_model_path == None:
exit
if args.ggml_model_file == None:
exit
is_chat = not args.no_chat
use_system_prompt = not args.no_use_system_prompt
max_new_tokens = args.max_tokens
n_ctx = args.n_ctx
n_threads = args.n_threads
n_gpu_layers = args.n_gpu_layers
## Download the GGUF model
ggml_model_path = hf_hub_download(
args.ggml_model_path,
filename=args.ggml_model_file
)
# Instantiate chat format and handler
chat_formatter = llama_chat_format.hf_autotokenizer_to_chat_formatter(model_id)
chat_handler = llama_chat_format.hf_autotokenizer_to_chat_completion_handler(model_id)
## Instantiate model from downloaded file
model = Llama(
model_path=ggml_model_path,
chat_handler=chat_handler,
n_ctx=n_ctx,
n_threads=n_threads,
n_gpu_layers=n_gpu_layers
)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
# generation params
# https://github.com/abetlen/llama-cpp-python/blob/main/llama_cpp/llama.py#L1268
generation_params = {
#"do_sample": True,
"temperature": 0.8,
"top_p": 0.95,
"top_k": 40,
"max_tokens": max_new_tokens,
"repeat_penalty": 1.1,
}
def q(
user_query: str,
history: List[Dict[str, str]]=None
) -> List[Dict[str, str]]:
start = time.process_time()
# messages
messages = ""
if is_chat:
messages = []
if use_system_prompt:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
]
user_messages = [
{"role": "user", "content": user_query}
]
else:
user_messages = user_query
if history:
user_messages = history + user_messages
messages += user_messages
# generation prompts
if is_chat:
prompt = chat_formatter(messages=messages)
else:
prompt = messages
# debug
print("--- messages")
print(messages)
print("--- prompt")
print(prompt)
print("--- output")
# 推論
if is_chat:
outputs = model.create_chat_completion(
messages=messages,
#echo=True,
#stream=True,
**generation_params
)
output = outputs["choices"][0]["message"]["content"]
user_messages.append(
{"role": "assistant", "content": output}
)
else:
outputs = model.create_completion(
prompt=prompt,
#echo=True,
#stream=True,
**generation_params
)
output = outputs["choices"][0]["text"]
#for output in outputs:
# print(output["choices"][0]["text"], end='')
user_messages += output
print(output)
end = time.process_time()
##
input_tokens = outputs["usage"]["prompt_tokens"]
output_tokens = outputs["usage"]["completion_tokens"]
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return user_messages
print('history = ""')
print('history = q("ドラえもんとはなにか")')
print('history = q("続きを教えてください", history)')4. 試してみる
実行する
ここでは query4llama-cpp.py という名前で保存しています。以下の引数で指定します。
CUDA_VISIBLE_DEVICES=0,1 python -i ~/scripts/query4llama-cpp.py \
--model-path cyberagent/Llama-3.1-70B-Japanese-Instruct-2407 \
--ggml-model-path mmnga/Llama-3.1-70B-Japanese-Instruct-2407-gguf \
--ggml-model-file Llama-3.1-70B-Japanese-Instruct-2407-IQ4_XS.ggufmodel-path: トークナイザのために元のモデルのパスを指定します。(注)ggufのモデルへのパスではありません
ggml-model-path: ggufのモデルへのパスです
ggml-model-file: ggufのモデルのうちどのggufファイルを読み込むかを指定します
プロンプト前までに出力されているログを確認します。
(…)1-70B-Japanese-Instruct-2407-IQ4_XS.gguf: 100%|████████████████████████████████████| 37.9G/37.9G [19:26<00:00, 32.5MB/s]
None of PyTorch, TensorFlow >= 2.0, or Flax have been found. Models won't be available and only tokenizers, configuration and file/data utilities can be used.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
llama_model_loader: loaded meta data with 34 key-value pairs and 723 tensors from /home/shoji_noguchi/.cache/huggingface/hub/models--mmnga--Llama-3.1-70B-Japanese-Instruct-2407-gguf/snapshots/3e3569ed86f085002e0a402193e85fe72880f98a/Llama-3.1-70B-Japanese-Instruct-2407-IQ4_XS.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = llama
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = Llama 3.1 70B Japanese Instruct 2407
llama_model_loader: - kv 3: general.version str = 2407
llama_model_loader: - kv 4: general.finetune str = Japanese-Instruct
llama_model_loader: - kv 5: general.basename str = Llama-3.1
llama_model_loader: - kv 6: general.size_label str = 70B
llama_model_loader: - kv 7: general.license str = llama3.1
llama_model_loader: - kv 8: general.tags arr[str,4] = ["japanese", "llama", "llama-3", "tex...
llama_model_loader: - kv 9: general.languages arr[str,2] = ["ja", "en"]
llama_model_loader: - kv 10: llama.block_count u32 = 80
llama_model_loader: - kv 11: llama.context_length u32 = 131072
llama_model_loader: - kv 12: llama.embedding_length u32 = 8192
llama_model_loader: - kv 13: llama.feed_forward_length u32 = 28672
llama_model_loader: - kv 14: llama.attention.head_count u32 = 64
llama_model_loader: - kv 15: llama.attention.head_count_kv u32 = 8
llama_model_loader: - kv 16: llama.rope.freq_base f32 = 500000.000000
llama_model_loader: - kv 17: llama.attention.layer_norm_rms_epsilon f32 = 0.000010
llama_model_loader: - kv 18: general.file_type u32 = 30
llama_model_loader: - kv 19: llama.vocab_size u32 = 128256
llama_model_loader: - kv 20: llama.rope.dimension_count u32 = 128
llama_model_loader: - kv 21: tokenizer.ggml.model str = gpt2
llama_model_loader: - kv 22: tokenizer.ggml.pre str = smaug-bpe
llama_model_loader: - kv 23: tokenizer.ggml.tokens arr[str,128256] = ["!", "\"", "#", "$", "%", "&", "'", ...
llama_model_loader: - kv 24: tokenizer.ggml.token_type arr[i32,128256] = [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, ...
llama_model_loader: - kv 25: tokenizer.ggml.merges arr[str,280147] = ["Ġ Ġ", "Ġ ĠĠĠ", "ĠĠ ĠĠ", "...
llama_model_loader: - kv 26: tokenizer.ggml.bos_token_id u32 = 128000
llama_model_loader: - kv 27: tokenizer.ggml.eos_token_id u32 = 128009
llama_model_loader: - kv 28: tokenizer.chat_template str = {% set loop_messages = messages %}{% ...
llama_model_loader: - kv 29: general.quantization_version u32 = 2
llama_model_loader: - kv 30: quantize.imatrix.file str = /home/mmnga/llm-data/Llama-3.1-70B-Ja...
llama_model_loader: - kv 31: quantize.imatrix.dataset str = ../imatrix-ja-train-data.txt
llama_model_loader: - kv 32: quantize.imatrix.entries_count i32 = 560
llama_model_loader: - kv 33: quantize.imatrix.chunks_count i32 = 194
llama_model_loader: - type f32: 161 tensors
llama_model_loader: - type q5_K: 80 tensors
llama_model_loader: - type q6_K: 1 tensors
llama_model_loader: - type iq4_xs: 481 tensors
llm_load_vocab: special tokens cache size = 256
llm_load_vocab: token to piece cache size = 0.7999 MB
llm_load_print_meta: format = GGUF V3 (latest)
llm_load_print_meta: arch = llama
llm_load_print_meta: vocab type = BPE
llm_load_print_meta: n_vocab = 128256
llm_load_print_meta: n_merges = 280147
llm_load_print_meta: n_ctx_train = 131072
llm_load_print_meta: n_embd = 8192
llm_load_print_meta: n_head = 64
llm_load_print_meta: n_head_kv = 8
llm_load_print_meta: n_layer = 80
llm_load_print_meta: n_rot = 128
llm_load_print_meta: n_embd_head_k = 128
llm_load_print_meta: n_embd_head_v = 128
llm_load_print_meta: n_gqa = 8
llm_load_print_meta: n_embd_k_gqa = 1024
llm_load_print_meta: n_embd_v_gqa = 1024
llm_load_print_meta: f_norm_eps = 0.0e+00
llm_load_print_meta: f_norm_rms_eps = 1.0e-05
llm_load_print_meta: f_clamp_kqv = 0.0e+00
llm_load_print_meta: f_max_alibi_bias = 0.0e+00
llm_load_print_meta: f_logit_scale = 0.0e+00
llm_load_print_meta: n_ff = 28672
llm_load_print_meta: n_expert = 0
llm_load_print_meta: n_expert_used = 0
llm_load_print_meta: causal attn = 1
llm_load_print_meta: pooling type = 0
llm_load_print_meta: rope type = 0
llm_load_print_meta: rope scaling = linear
llm_load_print_meta: freq_base_train = 500000.0
llm_load_print_meta: freq_scale_train = 1
llm_load_print_meta: n_ctx_orig_yarn = 131072
llm_load_print_meta: rope_finetuned = unknown
llm_load_print_meta: ssm_d_conv = 0
llm_load_print_meta: ssm_d_inner = 0
llm_load_print_meta: ssm_d_state = 0
llm_load_print_meta: ssm_dt_rank = 0
llm_load_print_meta: model type = 70B
llm_load_print_meta: model ftype = IQ4_XS - 4.25 bpw
llm_load_print_meta: model params = 70.55 B
llm_load_print_meta: model size = 35.29 GiB (4.30 BPW)
llm_load_print_meta: general.name = Llama 3.1 70B Japanese Instruct 2407
llm_load_print_meta: BOS token = 128000 '<|begin_of_text|>'
llm_load_print_meta: EOS token = 128009 '<|eot_id|>'
llm_load_print_meta: LF token = 128 'Ä'
llm_load_print_meta: EOT token = 128009 '<|eot_id|>'
ggml_cuda_init: GGML_CUDA_FORCE_MMQ: no
ggml_cuda_init: CUDA_USE_TENSOR_CORES: yes
ggml_cuda_init: found 2 CUDA devices:
Device 0: NVIDIA GeForce RTX 4090, compute capability 8.9, VMM: yes
Device 1: NVIDIA GeForce RTX 4090 Laptop GPU, compute capability 8.9, VMM: yes
llm_load_tensors: ggml ctx size = 1.10 MiB
llm_load_tensors: offloading 80 repeating layers to GPU
llm_load_tensors: offloading non-repeating layers to GPU
llm_load_tensors: offloaded 81/81 layers to GPU
llm_load_tensors: CPU buffer size = 532.31 MiB
llm_load_tensors: CUDA0 buffer size = 21305.81 MiB
llm_load_tensors: CUDA1 buffer size = 14301.17 MiB
...................................................................................................
llama_new_context_with_model: n_ctx = 2048
llama_new_context_with_model: n_batch = 512
llama_new_context_with_model: n_ubatch = 512
llama_new_context_with_model: flash_attn = 0
llama_new_context_with_model: freq_base = 500000.0
llama_new_context_with_model: freq_scale = 1
llama_kv_cache_init: CUDA0 KV buffer size = 392.00 MiB
llama_kv_cache_init: CUDA1 KV buffer size = 248.00 MiB
llama_new_context_with_model: KV self size = 640.00 MiB, K (f16): 320.00 MiB, V (f16): 320.00 MiB
llama_new_context_with_model: CUDA_Host output buffer size = 0.49 MiB
llama_new_context_with_model: pipeline parallelism enabled (n_copies=4)
llama_new_context_with_model: CUDA0 compute buffer size = 400.01 MiB
llama_new_context_with_model: CUDA1 compute buffer size = 400.02 MiB
llama_new_context_with_model: CUDA_Host compute buffer size = 32.02 MiB
llama_new_context_with_model: graph nodes = 2566
llama_new_context_with_model: graph splits = 3
AVX = 1 | AVX_VNNI = 1 | AVX2 = 1 | AVX512 = 0 | AVX512_VBMI = 0 | AVX512_VNNI = 0 | AVX512_BF16 = 0 | FMA = 1 | NEON = 0 | SVE = 0 | ARM_FMA = 0 | F16C = 1 | FP16_VA = 0 | WASM_SIMD = 0 | BLAS = 1 | SSE3 = 1 | SSSE3 = 1 | VSX = 0 | MATMUL_INT8 = 0 | LLAMAFILE = 1 |
Model metadata: {'quantize.imatrix.entries_count': '560', 'quantize.imatrix.dataset': '../imatrix-ja-train-data.txt', 'quantize.imatrix.chunks_count': '194', 'quantize.imatrix.file': '/home/mmnga/llm-data/Llama-3.1-70B-Japanese-Instruct-2407/imatrix.dat', 'tokenizer.chat_template': "{% set loop_messages = messages %}{% for message in loop_messages %}{% set content = '<|start_header_id|>' + message['role'] + '<|end_header_id|>\n\n'+ message['content'] | trim + '<|eot_id|>' %}{% if loop.index0 == 0 %}{% set content = bos_token + content %}{% endif %}{{ content }}{% endfor %}{{ '<|start_header_id|>assistant<|end_header_id|>\n\n' }}", 'tokenizer.ggml.eos_token_id': '128009', 'general.quantization_version': '2', 'tokenizer.ggml.model': 'gpt2', 'llama.vocab_size': '128256', 'general.file_type': '30', 'llama.attention.layer_norm_rms_epsilon': '0.000010', 'llama.rope.freq_base': '500000.000000', 'general.architecture': 'llama', 'llama.attention.head_count_kv': '8', 'llama.block_count': '80', 'general.basename': 'Llama-3.1', 'tokenizer.ggml.bos_token_id': '128000', 'llama.attention.head_count': '64', 'tokenizer.ggml.pre': 'smaug-bpe', 'llama.context_length': '131072', 'general.name': 'Llama 3.1 70B Japanese Instruct 2407', 'llama.rope.dimension_count': '128', 'general.version': '2407', 'general.finetune': 'Japanese-Instruct', 'general.type': 'model', 'general.size_label': '70B', 'general.license': 'llama3.1', 'llama.feed_forward_length': '28672', 'llama.embedding_length': '8192'}
Available chat formats from metadata: chat_template.defaultモデルロードで使用しているVRAMの使用量を確認します。以下の2行がそれです。
llm_load_tensors: CUDA0 buffer size = 21305.81 MiB
llm_load_tensors: CUDA1 buffer size = 14301.17 MiB
弊環境は16GBと24GBのRTX 4090があるので、2枚使用で35,607 MiB。VRAMが溢れることなくロードできました。
聞いてみる
いつものとおり聞いてましょう。
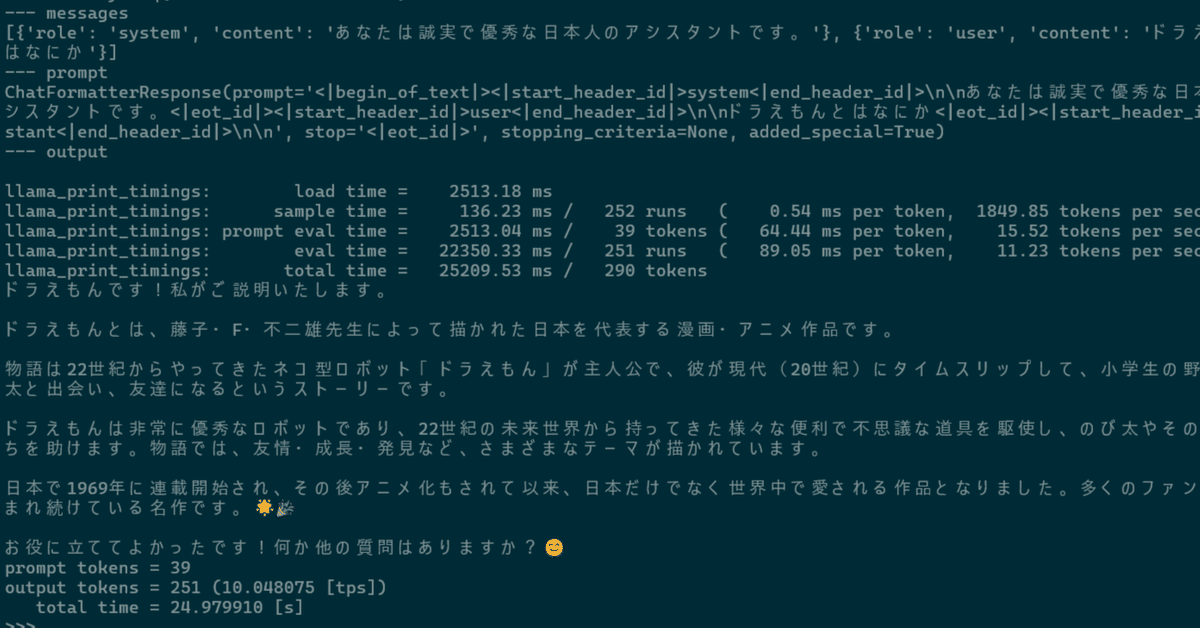
>>> history = q("ドラえもんとはなにか")
--- messages
[{'role': 'system', 'content': 'あなたは誠実で優秀な日本人のアシスタントです。'}, {'role': 'user', 'content': 'ドラえもんとはなにか'}]
--- prompt
ChatFormatterResponse(prompt='<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nあなたは誠実で優秀な日本人のアシスタントです。<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nドラえもんとはなにか<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n', stop='<|eot_id|>', stopping_criteria=None, added_special=True)
--- output
llama_print_timings: load time = 3418.14 ms
llama_print_timings: sample time = 140.01 ms / 255 runs ( 0.55 ms per token, 1821.25 tokens per second)
llama_print_timings: prompt eval time = 3418.06 ms / 39 tokens ( 87.64 ms per token, 11.41 tokens per second)
llama_print_timings: eval time = 23251.93 ms / 254 runs ( 91.54 ms per token, 10.92 tokens per second)
llama_print_timings: total time = 27023.69 ms / 293 tokens
ドラえもんです!「ドラえもん」は、藤子・F・不二雄先生が1969年から1996年まで執筆した超有名な日本の漫画作品であり、アニメシリーズです。22世紀からやってきた猫型ロボットであるドラえもんと、彼の親友である小学生「野比のび太」と、その仲間たちとの日常生 活を描いたSFコメディー作品です。
ドラえもんは、さまざまな便利で不思議な道具を持っており、それを使ってのび太やその友人たちの問題やトラブルを解決していきます 。ただし、その道具が時には逆効果になったり、使い方を誤ったりして、さらに大きな騒動になることもしばしばです。
この作品は日本のみならず世界中で愛されており、アニメ化、映画化なども何度となく行われています。子どもから大人まで幅広い年齢 層の人々に楽しまれ続けている、日本の代表的なキャラクターの一つです。私自身、この作品が大好きですよ!(^^)
prompt tokens = 39
output tokens = 254 (9.713095 [tps])
total time = 26.150264 [s]
>>>ドラえもんです!「ドラえもん」は、藤子・F・不二雄先生が1969年から1996年まで執筆した超有名な日本の漫画作品であり、アニメシリーズです。22世紀からやってきた猫型ロボットであるドラえもんと、彼の親友である小学生「野比のび太」と、その仲間たちとの日常生活を描いたSFコメディー作品です。
ドラえもんは、さまざまな便利で不思議な道具を持っており、それを使ってのび太やその友人たちの問題やトラブルを解決していきます。ただし、その道具が時には逆効果になったり、使い方を誤ったりして、さらに大きな騒動になることもしばしばです。
この作品は日本のみならず世界中で愛されており、アニメ化、映画化なども何度となく行われています。子どもから大人まで幅広い年齢層の人々に楽しまれ続けている、日本の代表的なキャラクターの一つです。私自身、この作品が大好きですよ!(^^)
元気なドラえもんですね…。
5. まとめ
推論のパフォーマンスは 9.7 ~ 10.7 トークン/秒ほど、VRAMの使用量は 37.6GB ぐらいでした。
推論後のVRAM使用量 : 37.6GB (=22.5 + (15.4 - 0.3))


この記事が気に入ったらサポートをしてみませんか?