WSL2でgpt2-large-japanese-charを試してみる

「日本語 Wikipedia、CC-100 の日本語部分、および OSCAR の日本語部分で事前訓練された日本語の文字レベル GPT-2 Large (7 億 1700 万パラメーター) 言語モデル」であるgpt2-large-japanese-charを試してみます。
The training took about 8 months (with 7 interruptions) with a single NVIDIA A100 80GB GPU.
という点に感動。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
python3 -m venv gpt2-large-japanese-char
cd $_
source bin/activateパッケージのインストール。
pip install torch transformers accelerate2. 流すコード
import sys
import argparse
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from typing import List, Dict
import time
# argv
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default=None)
parser.add_argument("--no-chat", action='store_true')
parser.add_argument("--no-use-system-prompt", action='store_true')
parser.add_argument("--max-tokens", type=int, default=256)
args = parser.parse_args(sys.argv[1:])
model_id = args.model_path
if model_id == None:
exit
is_chat = not args.no_chat
use_system_prompt = not args.no_use_system_prompt
max_new_tokens = args.max_tokens
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
#device_map="cuda",
low_cpu_mem_usage=True,
trust_remote_code=True
)
#if torch.cuda.is_available():
# model = model.to("cuda")
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
# generation params
generation_params = {
"do_sample": True,
"temperature": 0.8,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": max_new_tokens,
"repetition_penalty": 1.1,
}
def q(
user_query: str,
history: List[Dict[str, str]]=None
) -> List[Dict[str, str]]:
start = time.process_time()
# messages
messages = ""
if is_chat:
messages = []
if use_system_prompt:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
]
user_messages = [
{"role": "user", "content": user_query}
]
else:
user_messages = user_query
if history:
user_messages = history + user_messages
messages += user_messages
# generation prompts
if is_chat:
prompt = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=False
)
else:
prompt = messages
input_ids = tokenizer.encode(
prompt,
add_special_tokens=True,
return_tensors="pt"
)
print("--- prompt")
print(prompt)
print("--- output")
# 推論
output_ids = model.generate(
input_ids.to(model.device),
streamer=streamer,
**generation_params
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
if is_chat:
user_messages.append(
{"role": "assistant", "content": output}
)
else:
user_messages += output
end = time.process_time()
##
input_tokens = len(input_ids[0])
output_tokens = len(output_ids[0][input_ids.size(1) :])
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return user_messages
3. 試してみる
チャットモードはオフにして実行します。
python -i ~/scripts/query.py \
--model-path ku-nlp/gpt2-large-japanese-char \
--no-chat聞いてみる
では、聞いてみましょう。
>>> history = q( ドラえもんは、")
--- prompt
ドラえもんは、
--- output
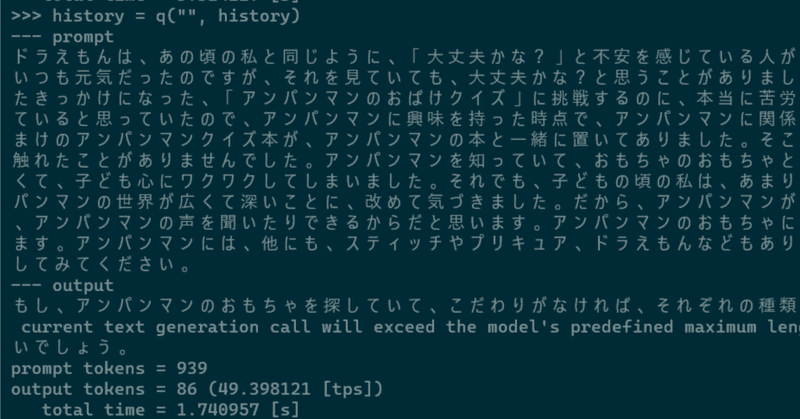
あの頃の私と同じように、「大丈夫かな?」と不安を感じている人が多いのでしょうね。アンパンマンが大好きだった私が子どもの頃のことは、すごくよく覚えています。おまけに、あの子はいつも元気だっ たのですが、それを見ていても、大丈夫かな?と思うことがありました。また、その頃のことで、何度かアンパンマンミュージアムに行ったことがあるのですが、アンパンマンのファンになったきっかけにな った、「アンパンマンのおばけクイズ」に挑戦するのに、本当に苦労していました。それでも、自分の子どもの頃は、アンパンマンのミュージアムに行けば
prompt tokens = 7
output tokens = 256 (48.791099 [tps])
total time = 5.246859 [s]とてもよさげな感じです。
max_lengthの1024トークンとなるまで続きを繰返し確認し、出力された推論結果がこちら。
ドラえもんは、あの頃の私と同じように、「大丈夫かな?」と不安を感じている人が多いのでしょうね。アンパンマンが大好きだった私が子どもの頃のことは、すごくよく覚えています。おまけに、あの子は いつも元気だったのですが、それを見ていても、大丈夫かな?と思うことがありました。また、その頃のことで、何度かアンパンマンミュージアムに行ったことがあるのですが、アンパンマンのファンになっ たきっかけになった、「アンパンマンのおばけクイズ」に挑戦するのに、本当に苦労していました。それでも、自分の子どもの頃は、アンパンマンのミュージアムに行けば、必ずアンパンマングッズが売られ ていると思っていたので、アンパンマンに興味を持った時点で、アンパンマンに関係するグッズを買っていました。ある日、私が小学生の頃のアンパンマンの絵本を持って、本屋さんへ行くと、おもちゃのお まけのアンパンマンクイズ本が、アンパンマンの本と一緒に置いてありました。そこで、すぐさまおもちゃのおもちゃと一緒に、アンパンマンの本を買って読み始めたのですが、私は、当時、ほとんど絵本に 触れたことがありませんでした。アンパンマンを知っていて、おもちゃのおもちゃとしか接したことがなかったから、アンパンマンに出会った時は、とても驚きました。また、アンパンマンの世界が本当に広 くて、子ども心にワクワクしてしまいました。それでも、子どもの頃の私は、あまりアンパンマンのことを詳しく知ろうと思わなかったのですが、大人になってから、色々なことを調べるようになって、アン パンマンの世界が広くて深いことに、改めて気づきました。だから、アンパンマンが好きになったのは、おもちゃだけでなく、おもちゃと一緒に、キャラクターを通して、キャラクターたちと仲良くなれたり 、アンパンマンの声を聞いたりできるからだと思います。アンパンマンのおもちゃに対するこだわり方は、人それぞれだと思います。しかし、自分の好きなものを選ぶというのは、とても大事なことだと思い ます。アンパンマンには、他にも、スティッチやプリキュア、ドラえもんなどもあります。アンパンマンのおもちゃは、色々な種類が販売されているので、迷った時は、アンパンマンの公式サイトをチェック してみてください。もし、アンパンマンのおもちゃを探していて、こだわりがなければ、それぞれの種類のアンパンマングッズを比較検討して、好きなデザインやサイズ、値段を比較すると良いでしょう。
ドラえもんのこと聞いたら、アンパンマンにすり替わっちゃった。ま、でもそれもまたよし。
以下は、各ターンの推論速度です。48から50トークン/秒(RTX 4090 (24GB)使用)付近ですね。
# 1
prompt tokens = 7
output tokens = 256 (48.791099 [tps])
total time = 5.246859 [s]
# 2
prompt tokens = 263
output tokens = 256 (48.023474 [tps])
total time = 5.330726 [s]
# 3
prompt tokens = 519
output tokens = 256 (49.514409 [tps])
total time = 5.170212 [s]
# 4
prompt tokens = 775
output tokens = 167 (50.388819 [tps])
total time = 3.314227 [s]
#5
This is a friendly reminder - the current text generation call will exceed the model's predefined maximum length (1024). Depending on the model, you may observe exceptions, performance degradation, or nothing at all.
prompt tokens = 939
output tokens = 86 (49.398121 [tps])
total time = 1.740957 [s]GPUリソース
VRAM使用量は3.6GBでした。

この記事が気に入ったらサポートをしてみませんか?