WSL2でstablelm-zephyr-3bを試してみる

stablelm-zephyr-3bを試してみます。
使用するPCは、GALLERIA UL9C-R49(RTX 4090 laptop 16GB)、Windows 11+WSL2です。
準備
python3 -m venv stablelm-zephyr-3b
cd $_
source bin/activatepip install
pip install torch transformers acceleratepip list
$ pip list
Package Version
------------------------ ----------
accelerate 0.25.0
certifi 2023.11.17
charset-normalizer 3.3.2
filelock 3.13.1
fsspec 2023.12.1
huggingface-hub 0.19.4
idna 3.6
Jinja2 3.1.2
MarkupSafe 2.1.3
mpmath 1.3.0
networkx 3.2.1
numpy 1.26.2
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.3.101
nvidia-nvtx-cu12 12.1.105
packaging 23.2
pip 22.0.2
psutil 5.9.6
PyYAML 6.0.1
regex 2023.10.3
requests 2.31.0
safetensors 0.4.1
setuptools 59.6.0
sympy 1.12
tokenizers 0.15.0
torch 2.1.1
tqdm 4.66.1
transformers 4.36.0
triton 2.1.0
typing_extensions 4.9.0
urllib3 2.1.0コードの準備
こちらに記載のinstruction formatを参考に、コードを作成します。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
import time
llm = "stabilityai/stablelm-zephyr-3b"
tokenizer = AutoTokenizer.from_pretrained(llm)
model = AutoModelForCausalLM.from_pretrained(
llm,
device_map="auto",
trust_remote_code=True
)
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
INST_SYS="あなたは優秀なAIです。すべて日本語で回答してください。"
def build_prompt(user_query, chat_history):
prompt = f"<|user|>\n{user_query}\n<|endoftext|>\n<|assistant|>\n"
if chat_history:
prompt = chat_history + "<|endoftext|>\n" + prompt
return prompt
def q(user_query, chat_history):
start = time.process_time()
# 推論の実行
sys_input = f"<|system|>\n{INST_SYS}\n"
prompt = build_prompt(user_query, chat_history)
input_ids = tokenizer.encode(
sys_input + prompt,
return_tensors="pt"
)
output_ids = model.generate(
input_ids.to(device=model.device),
max_new_tokens=1024,
do_sample=True,
temperature=0.8,
streamer=streamer,
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
chat_history = prompt + output
end = time.process_time()
print(end - start)
return chat_history試してみる
pythonを起動してコード流し込んだら・・・。
tokenizer_config.json: 100%|██████████████████████████████████████████████████████████| 5.21k/5.21k [00:00<00:00, 46.0MB/s]
tokenizer.json: 100%|█████████████████████████████████████████████████████████████████| 2.11M/2.11M [00:00<00:00, 11.5MB/s]
special_tokens_map.json: 100%|████████████████████████████████████████████████████████████| 587/587 [00:00<00:00, 6.14MB/s]
Special tokens have been added in the vocabulary, make sure the associated word embeddings are fine-tuned or trained.
config.json: 100%|████████████████████████████████████████████████████████████████████████| 840/840 [00:00<00:00, 8.29MB/s]
configuration_stablelm_epoch.py: 100%|████████████████████████████████████████████████| 5.27k/5.27k [00:00<00:00, 50.8MB/s]
A new version of the following files was downloaded from https://huggingface.co/stabilityai/stablelm-zephyr-3b:
- configuration_stablelm_epoch.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
modeling_stablelm_epoch.py: 100%|██████████████████████████████████████████████████████| 27.8k/27.8k [00:00<00:00, 195MB/s]
A new version of the following files was downloaded from https://huggingface.co/stabilityai/stablelm-zephyr-3b:
- modeling_stablelm_epoch.py
. Make sure to double-check they do not contain any added malicious code. To avoid downloading new versions of the code file, you can pin a revision.
model.safetensors: 100%|██████████████████████████████████████████████████████████████| 5.59G/5.59G [06:20<00:00, 14.7MB/s]
generation_config.json: 100%|█████████████████████████████████████████████████████████████| 111/111 [00:00<00:00, 1.11MB/s]
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:0 for open-end generation.聞いてみましょう。
>>> chat_history = ""
>>> chat_history = q("小学生にでもわかる言葉で教えてください。ドラえもんとはなにか", chat_history)ドラえは、日本語でも「ドラえ」という意味で、インターネット上でゲームや動画を再生するためのダウンロードアプリケーションやウ ェブサイトで生成されるデータフILEと�Tokさ、それでもデバイス(PC、スマートフォン、キット(パーソナルソフトウェア)など)のデータを収集して再生できる形である。また、Dラえは音楽や動画ファイルを無料でデモレイフで再生できる特定のダウンロードサイトで使用することもあります。
5.327688800000004
速いのだけれども・・・。回答がいまいち。
chat_history = q("続きを教えてください", chat_history)また、「ドラえ」はアイデアやコンテンツの再生やコンテンツ化(例:動画制作、写真制作、音楽制作)を簡単に行うためのツールやプ ログラムも象徴することもあります。そのため、小学生にもわかりやすい言葉で「ドラえ」を使うことで、インターネットで楽しみこと ができる理由が解らかれるでしょう。
4.11761589999999
速いのだけれども。tokenizerの問題かな。
リソース
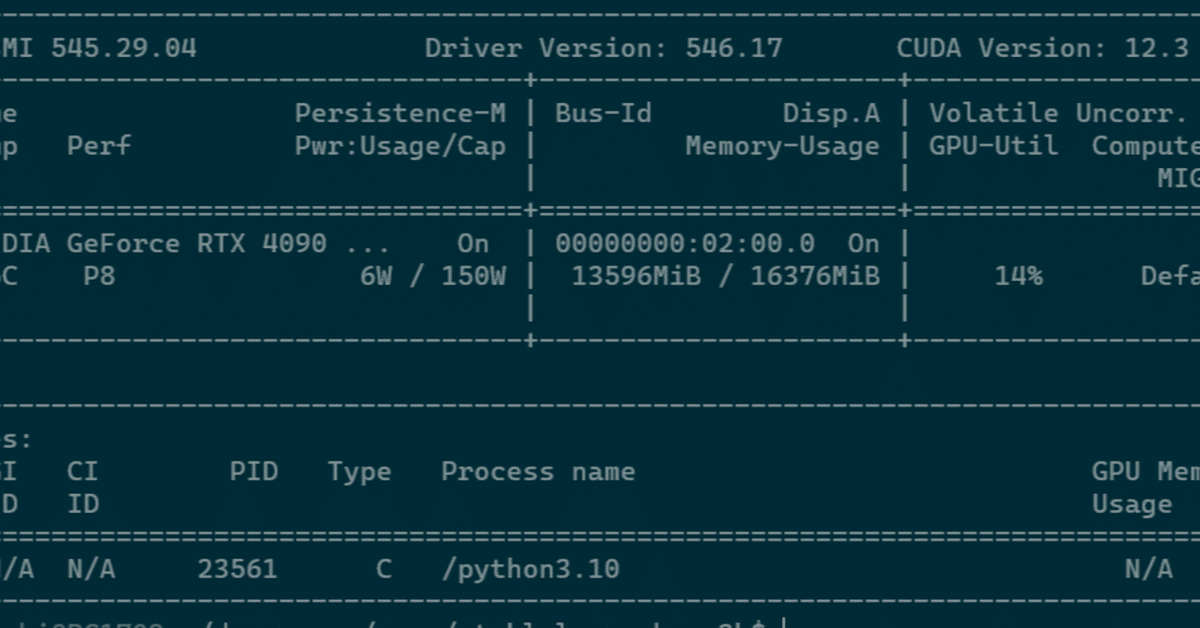
13.3GBぐらい。確かに、ミドルレンジのGPUカードでも動くかな。

この記事が気に入ったらサポートをしてみませんか?