
WSL2でStripedHyena-Nous-7Bを試してみる

自称「Transformerを超えた世界を垣間見るオープンソースモデル」であるStripedHyena-7Bを試してみましょう。
flash_attnがエラーとなってしまって、とりまとめるのに時間がかかりました。
使用するPCは、GALLERIA UL9C-R49(RTX 4090 laptop 16GB)、Windows 11+WSL2です。
現時点で2つモデルが公開されています。
StripedHyena-Hessian-7B (SH 7B) : ベースモデル
StripedHyena-Nous-7B (SH-N 7B) : チャットモデル
今回は、チャットモデルであるStripedHyena-Nous-7Bを試します。
使用するPCは、GALLERIA UL9C-R49(RTX 4090 laptop 16GB)、Windows 11+WSL2です。
準備
python3 -m venv stripedhyena-7b
cd $_
source bin/activatepip install。いつものパッケージだけでなく、
pip install torch transformers accelerateこちも忘れずに。flash_attnのためにwheelが必要です。
(注記)この時点では「必要」だったのですが、後述の通りこのversionのflash_attnだと上手く動かなかったので、このinstallは不要です、はい。
pip install wheel
pip install flash_attnですので、pip listの結果は後ほど・・・。
コードの準備
llm変数と、build_prompt関数を適切に修正します。
トークン数が長いとおかしな回答になってしまう(ループし出す)ので、1024ではなく256と小さくしています。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
import time
llm = "togethercomputer/StripedHyena-Nous-7B"
tokenizer = AutoTokenizer.from_pretrained(llm)
model = AutoModelForCausalLM.from_pretrained(
llm,
device_map="auto",
trust_remote_code=True
)
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
INST_SYS="あなたは優秀なAIです。すべて日本語で回答してください。"
def build_prompt(user_query, chat_history):
prompt = f"### Instruction:\n{user_query}\n\n### Response:"
if chat_history:
prompt = chat_history + "\n" + prompt
return prompt
def q(user_query, chat_history):
start = time.process_time()
# 推論の実行
sys_input = f"### System:\n{INST_SYS}\n"
prompt = build_prompt(user_query, chat_history)
input_ids = tokenizer.encode(
sys_input + prompt,
return_tensors="pt"
)
output_ids = model.generate(
input_ids.to(device=model.device),
max_new_tokens=256,
do_sample=True,
temperature=0.8,
streamer=streamer,
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
chat_history = prompt + output
end = time.process_time()
print(end - start)
return chat_history
試してみる
flash_attn?でエラー発生
流し込むと、以下のようなエラーが発生しました。。。
Traceback (most recent call last):
File "/path/to/.cache/huggingface/modules/transformers_modules/togethercomputer/StripedHyena-Nous-7B/42777970d603597dadb768705896533eb9556a07/layers.py", line 21, in __init__
from flash_attn.ops.rms_norm import rms_norm as rmsnorm_func
File "/path/to/venv/stripedhyena-7b/lib/python3.10/site-packages/flash_attn/ops/rms_norm.py", line 7, in <module>
from flash_attn.ops.layer_norm import (
File "/path/to/venv/stripedhyena-7b/lib/python3.10/site-packages/flash_attn/ops/layer_norm.py", line 4, in <module>
import dropout_layer_norm
ModuleNotFoundError: No module named 'dropout_layer_norm'
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "/path/to/venv/stripedhyena-7b/query-7b.py", line 8, in <module>
model = AutoModelForCausalLM.from_pretrained(
File "/path/to/venv/stripedhyena-7b/lib/python3.10/site-packages/transformers/models/auto/auto_factory.py", line 561, in from_pretrained
return model_class.from_pretrained(
File "/path/to/venv/stripedhyena-7b/lib/python3.10/site-packages/transformers/modeling_utils.py", line 3450, in from_pretrained
model = cls(config, *model_args, **model_kwargs)
File "/path/to/.cache/huggingface/modules/transformers_modules/togethercomputer/StripedHyena-Nous-7B/42777970d603597dadb768705896533eb9556a07/modeling_hyena.py", line 38, in __init__
self.backbone = StripedHyena(model_config)
File "/path/to/.cache/huggingface/modules/transformers_modules/togethercomputer/StripedHyena-Nous-7B/42777970d603597dadb768705896533eb9556a07/model.py", line 312, in __init__
self.norm = RMSNorm(config) if config.get("final_norm", True) else None
File "/path/to/.cache/huggingface/modules/transformers_modules/togethercomputer/StripedHyena-Nous-7B/42777970d603597dadb768705896533eb9556a07/layers.py", line 25, in __init__
raise ImportError(
ImportError: For `use_flash_rmsnorm`: `pip install git+https://github.com/HazyResearch/flash-attention.git#subdirectory=csrc/layer_norm`flash_attnのバージョンがマッチしてないんでしょうか。アレコレ考えず、指示通りにpip installしてみましょう。
$ pip install git+https://github.com/HazyResearch/flash-attention.git#subdirectory=csrc/layer_norm
Collecting git+https://github.com/HazyResearch/flash-attention.git#subdirectory=csrc/layer_norm
Cloning https://github.com/HazyResearch/flash-attention.git to /tmp/pip-req-build-_0pldhhz
Running command git clone --filter=blob:none --quiet https://github.com/HazyResearch/flash-attention.git /tmp/pip-req-build-_0pldhhz
Resolved https://github.com/HazyResearch/flash-attention.git to commit 9356a1c0389660d7e231ff3163c1ac17d9e3824a
Running command git submodule update --init --recursive -q
Preparing metadata (setup.py) ... done
Building wheels for collected packages: dropout-layer-norm
Building wheel for dropout-layer-norm (setup.py) ... error
error: subprocess-exited-with-error
× python setup.py bdist_wheel did not run successfully.
│ exit code: 1
╰─> [131 lines of output]
torch.__version__ = 2.1.1+cu121
(snip)
raise RuntimeError(message) from e
RuntimeError: Error compiling objects for extension
[end of output]
note: This error originates from a subprocess, and is likely not a problem with pip.
ERROR: Failed building wheel for dropout-layer-norm
Running setup.py clean for dropout-layer-norm
Failed to build dropout-layer-norm
Installing collected packages: dropout-layer-norm
Running setup.py install for dropout-layer-norm ... done
DEPRECATION: dropout-layer-norm was installed using the legacy 'setup.py install' method, because a wheel could not be built for it. A possible replacement is to fix the wheel build issue reported above. Discussion can be found at https://github.com/pypa/pip/issues/8368
Successfully installed dropout-layer-norm-0.1
$「wheelだとbuildできなかったので、レガシーな方法でinstallしたぜ(きりっ」とのことで、ずいぶん時間がかかりましたが、build&installは成功したようです。
あらためてpip list
$ pip list
Package Version
------------------------ ----------
accelerate 0.25.0
certifi 2023.11.17
charset-normalizer 3.3.2
dropout-layer-norm 0.1
einops 0.7.0
filelock 3.13.1
flash-attn 2.3.6
fsspec 2023.12.1
huggingface-hub 0.19.4
idna 3.6
Jinja2 3.1.2
MarkupSafe 2.1.3
mpmath 1.3.0
networkx 3.2.1
ninja 1.11.1.1
numpy 1.26.2
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.3.101
nvidia-nvtx-cu12 12.1.105
packaging 23.2
pip 22.0.2
psutil 5.9.6
PyYAML 6.0.1
regex 2023.10.3
requests 2.31.0
safetensors 0.4.1
setuptools 59.6.0
sympy 1.12
tokenizers 0.15.0
torch 2.1.1
tqdm 4.66.1
transformers 4.36.0
triton 2.1.0
typing_extensions 4.9.0
urllib3 2.1.0
wheel 0.42.0あらためて聞いてみる
流し込みし直して、聞いてみましょう。
chat_history = ""
chat_history = q("小学生にでもわかる言葉で教えてください。ドラえもんとはなにか", chat_history)WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu.
Initializing inference params...
ドラえもんは、ドラえモンと呼ばれる人物です。ドラえモンは、日本のマンガとアニメの世界で非常に人気のあるキャラクターです。彼 はドラゴンと人間との混在した生き方をしている、そしてその中で冒険に出かけていることが特徴です。小学生は、ドラえもんが美しい 竜と美しい女性との冒険を見ることができます。
ドラえモンは、冒険を行う際に、彼の友人と彼が一緒に行く人々がいます。そして、彼らはそれぞれの力が違うことから、困難な状況に 直面します
58.186954300000004
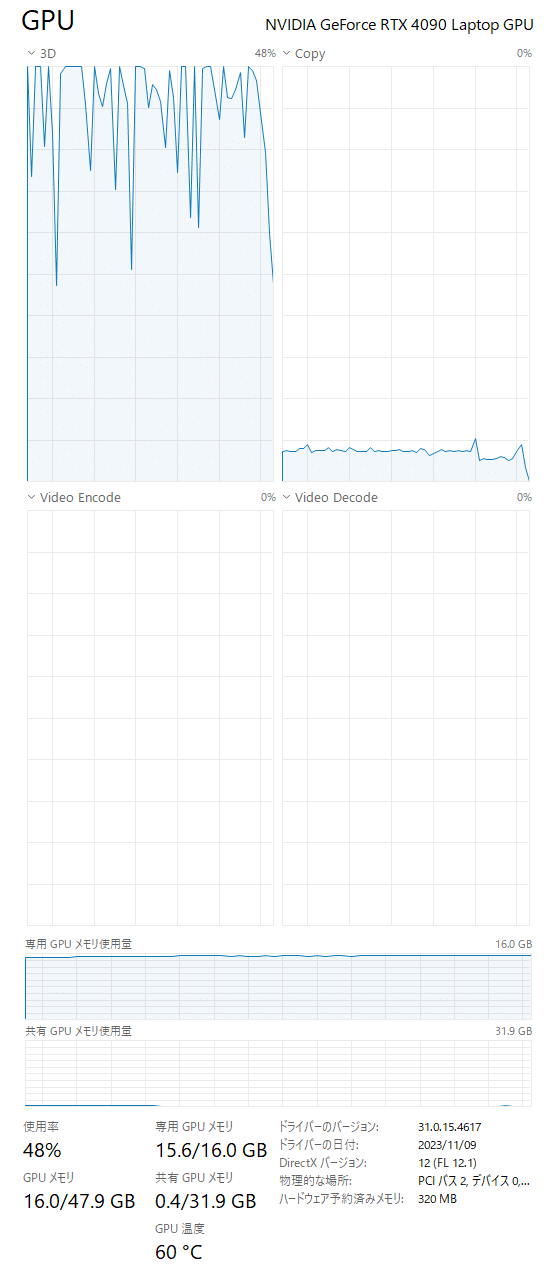
offloaded to the cpu? たしかに、GPUの専有メモリがぎりぎりだな・・・。
ぎりぎりのせいなのか、ちょっとゆっくりなのかもしれない。GPUメモリが欲しい。
chat_history = q("続きを教えてください", chat_history)Initializing inference params...
続き:
小学生への続き:
ドラえもんは、冒険中に彼が一緒に行く友人々がいます。それぞれの人々は、力、知識、または他の特性によって、困難な状況に直面し ます。これらの人々は、彼に彼の目標を求め、彼が冒険に出ることを決意すると、彼らも彼に支えてくれます。そして、彼らの彼らが持 っている力や知識は、彼が練り続けることで成長し、彼が成長することでもあります。
冒険に出ることで、ドラえモンやその友人たちが人�
76.5760026
途中で切れたので、さらに、
chat_history = q("続きを教えてください", chat_history)Initializing inference params...
続き:
冒険に出ることで、ドラえモンやその友人たちが人々として成長し、彼らの経験を受け積んで、未来にも多くの冒険が期待されます。彼 らは、彼が得る知識や力、そして彼らが得た経験から他の人々に教え、支えることで、他の世界にも喜ぶことができることです。
そして、ドラえモンとその友人たちの冒険には、それぞれの大きな価値があります。今回の質問に答えると、ドラえモンは、美しい竜と 美しい女性との冒険を行うことで、そして
71.73989889999999
ドラゴンボールとドラゴンクエストを混ぜたようなそんな感じ?
リソース
GPU専用メモリは 15.6 GB。16.0GBをフルで使い切ってないんだけどなぁ。
この記事が気に入ったらサポートをしてみませんか?