
WSL2でSwallow-7b-plus-hfを試してみる

「主に日本語データの追加を伴う、Llama2ファミリーからの継続的な事前トレーニングを受けた」Swallowモデル群に、先日plusが追加されたようなので、試してみます。
plusのinstructモデルはComing Soonなので、ベースモデルを今回は試します。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
準備
python3 -m venv swallow
cd $_
source bin/activateパッケージのインストールです。
pip install torch transformers accelerate流し込むコード
いつもと同じです。query.pyというファイル名で保存します。
import sys
import argparse
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from typing import List, Dict
import time
# argv
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default=None)
parser.add_argument("--no-chat", action='store_true')
parser.add_argument("--no-use-system-prompt", action='store_true')
parser.add_argument("--max-tokens", type=int, default=256)
args = parser.parse_args(sys.argv[1:])
model_id = args.model_path
if model_id == None:
exit
is_chat = not args.no_chat
use_system_prompt = not args.no_use_system_prompt
max_new_tokens = args.max_tokens
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
#device_map="cuda",
low_cpu_mem_usage=True,
trust_remote_code=True
)
#if torch.cuda.is_available():
# model = model.to("cuda")
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
# generation params
generation_params = {
"do_sample": True,
"temperature": 0.8,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": max_new_tokens,
"repetition_penalty": 1.1,
}
def q(
user_query: str,
history: List[Dict[str, str]]=None
) -> List[Dict[str, str]]:
start = time.process_time()
# messages
messages = ""
if is_chat:
messages = []
if use_system_prompt:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
]
user_messages = [
{"role": "user", "content": user_query}
]
else:
user_messages = user_query
if history:
user_messages = history + user_messages
messages += user_messages
# generation prompts
if is_chat:
prompt = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=False
)
else:
prompt = messages
input_ids = tokenizer.encode(
prompt,
add_special_tokens=True,
return_tensors="pt"
)
print("--- prompt")
print(prompt)
print("--- output")
# 推論
output_ids = model.generate(
input_ids.to(model.device),
streamer=streamer,
**generation_params
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
if is_chat:
user_messages.append(
{"role": "assistant", "content": output}
)
else:
user_messages += output
end = time.process_time()
##
input_tokens = len(input_ids[0])
output_tokens = len(output_ids[0][input_ids.size(1) :])
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return user_messages
print('history = ""')
print('history = q("ドラえもんとはなにか")')
print('history = q("続きを教えてください", history)')
試してみる
chat(instruct)モデルではないので、--no-chatとして起動します。
(補足)--no-chatと指定とすると、chat_templateを使用せずにプロンプトを生成します。
python -i ./query.py --model-path tokyotech-llm/Swallow-7b-plus-hf \
--no-chat聞いてみましょう。
>>> history = q("ドラえもんとはなにか")
--- prompt
ドラえもんとはなにか
--- output
ドラえもんについて考えている。
「ドラえもん」という言葉からなにを思い浮かべるだろうか。
漫画、アニメ、映画、本、キャラクターグッズ......?
そんな中で、もっとも一般的なものはやはり「漫画」と答える人が多いのではないかと思う。
漫画版ドラえもんは全6巻にわたる傑作だと思っているし、アニメ版ドラえもんもまた、日本人にとってかけがえのない財産とも言うべき名作であることに疑いはない。
しかし、この記事でわたしはドラえもんの「映画」について書こうと思っている。
ドラえもんの映画といえば、国民的長寿番組の劇場版作品として現在まで続いており、そのどれもが非常にクオリティの高い作品ばかりであり、ファンのみならず多くの観客の心を掴んできた。
2019年3月1日時点で、38作目の『のび太の月面探査記』が公開されている。
今回はその映画シリーズの中でも私が個人的に好きな作品を紹介したい
prompt tokens = 9
output tokens = 256 (29.448138 [tps])
total time = 8.693249 [s]
>>> history = q("", history)ドラえもんについて考えている。
「ドラえもん」という言葉からなにを思い浮かべるだろうか。
漫画、アニメ、映画、本、キャラクターグッズ......?
そんな中で、もっとも一般的なものはやはり「漫画」と答える人が多いのではないかと思う。
漫画版ドラえもんは全6巻にわたる傑作だと思っているし、アニメ版ドラえもんもまた、日本人にとってかけがえのない財産とも言うべき名作であることに疑いはない。
しかし、この記事でわたしはドラえもんの「映画」について書こうと思っている。
ドラえもんの映画といえば、国民的長寿番組の劇場版作品として現在まで続いており、そのどれもが非常にクオリティの高い作品ばかりであり、ファンのみならず多くの観客の心を掴んできた。
2019年3月1日時点で、38作目の『のび太の月面探査記』が公開されている。
今回はその映画シリーズの中でも私が個人的に好きな作品を紹介したい
これは、なかなかいい感じである。いままで最高かもしれない。続きを聞いてみる。
>>> history = q("", history)。
まず、1つめ。
『ぼくの生まれた日』(2016)
本作はタイトル通り、ドラえもん誕生を巡る物語である。
舞台は、ドラえもんが生まれる20世紀。のび太の町は21世紀へと向かっていた。
そしてそこに登場するのはなんと、未来デパートのセールスマン・ナカムラさん。彼は時空を超え、のび太の町へドラえもんを届けにやってきたのだ。
これだけでもワクワクする展開なのだが、さらに注目すべき点は、本作におけるタイムパラドックスを上手く利用したストーリーである。
ドラえもんの道具を使って過去改変を行うのび太とそれを阻止しようとするセワシとの攻防は見ていてハラハラさせられる。
特に終盤になるとセワシが窮地に立たされるのだが、そこで発揮されるドラミの超絶チート能力により一気に形勢逆転するシーンは爽快感が半端じゃない。
何度観ても飽きることなく楽しめる本作は間違いなく傑作と言える。
すごい。これはすごい。すごい。ナカムラさんではなくナカメグロさんだけど、すごい。
以下は、尽きるまで聞いた結果。
ドラえもんとはなにか
ドラえもんについて考えている。
「ドラえもん」という言葉からなにを思い浮かべるだろうか。
漫画、アニメ、映画、本、キャラクターグッズ......?
そんな中で、もっとも一般的なものはやはり「漫画」と答える人が多いのではないかと思う。
漫画版ドラえもんは全6巻にわたる傑作だと思っているし、アニメ版ドラえもんもまた、日本人にとってかけがえのない財産とも言うべき名作であることに疑いはない。
しかし、この記事でわたしはドラえもんの「映画」について書こうと思っている。
ドラえもんの映画といえば、国民的長寿番組の劇場版作品として現在まで続いており、そのどれもが非常にクオリティの高い作品ばかりであり、ファンのみならず多くの観客の心を掴んできた。
2019年3月1日時点で、38作目の『のび太の月面探査記』が公開されている。
今回はその映画シリーズの中でも私が個人的に好きな作品を紹介したい。
まず、1つめ。
『ぼくの生まれた日』(2016)
本作はタイトル通り、ドラえもん誕生を巡る物語である。
舞台は、ドラえもんが生まれる20世紀。のび太の町は21世紀へと向かっていた。
そしてそこに登場するのはなんと、未来デパートのセールスマン・ナカムラさん。彼は時空を超え、のび太の町へドラえもんを届けにやってきたのだ。
これだけでもワクワクする展開なのだが、さらに注目すべき点は、本作におけるタイムパラドックスを上手く利用したストーリーである。
ドラえもんの道具を使って過去改変を行うのび太とそれを阻止しようとするセワシとの攻防は見ていてハラハラさせられる。
特に終盤になるとセワシが窮地に立たされるのだが、そこで発揮されるドラミの超絶チート能力により一気に形勢逆転するシーンは爽快感が半端じゃない。
何度観ても飽きることなく楽しめる本作は間違いなく傑作と言える。
続いてはこちら。
『新・のび太の日本誕生』(2016)
本作は1989年に公開された第4作目『のび太の日本誕生』のリメイク作品である。
ストーリー自体はあまり変わりはないが、ジャイアンとスネ夫が自分達だけで冒険に出かけるなどオリジナル要素も盛り込まれている。
また、冒頭に出てくる原始時代のククルを救うためにタイムパトロールの隊員たちが奮闘するシーンは、後の本編に繋がる伏線のような役割も果たしている。
本作のテーマソングである斉藤和義さんの『歩いて帰ろう』は、今なお色褪せることのない名曲で、その歌詞と物語が一致するところも素晴らしい。
最後にご紹介するのはこちら。
『STAND BY ME ドラえもん』(2014)
2014年に公開された山崎貴監督によるCGアニメーション作品。
原作者・藤子・F・不二雄先生の生誕80周年記念企画の一環として制作された。
本作は大人向けの内容になっており、普段子供向けの作品を鑑賞する機会が少ない方にもぜひ観てほしい。
本作には、原作のエピソード「雪山のロマンス」「のび太の結婚前夜」「さようならドラえもん」を再構築した三部構成となっている。
大人になりすっかり情けなくなったのび太と、いつまでも変わらぬドラえもんの姿は、観る側の涙腺を容赦なく刺激する。
また、挿入歌である秦基博さんの『ひまわりの約束』が物語に深みを与えており、本当に素晴らしい。
ここでは3作品しかご紹介出来ませんでしたが、他にも名作揃いですのでぜひ一度ご覧ください。
GPUリソース
RTX 4090 Laptop GPU(16GB)で試しました。使用していたVRAMは 14.8GB(15.5 - 0.7)。
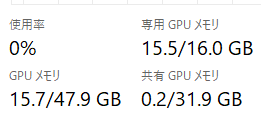
推論の性能は 27~29トークン/秒あたりでした。
関連
この記事が気に入ったらサポートをしてみませんか?