
WSL2でTinyLlama-1.1B-ChatをvLLMとともに試してみる

TinyLlama-1.1B-Chatを「vLLMがないときー」「vLLMがあるときー」のそれぞれでどう違うか試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
venvを構築して
python3 -m venv tinyllama
cd $_
source bin/activatepip installします。
pip install torch transformers accelerate
pip install vllm2. コード
transformers版
毎回類似のを貼り付けるのもアレなので、GitHubにcommitしておきました。
こんな感じで実行します。引数としてhuggingfaceのパスを指定します。
$ python -i query.py TinyLlama/TinyLlama-1.1B-Chat-v1.0vLLM版
こちらも同様の実行方法です。
$ python -i query4vllm.py TinyLlama/TinyLlama-1.1B-Chat-v1.0vLLMは最初にVRAMをドカンと確保します。TinyLlamaなのにVRAMを大量に使用していたらまったく意味がないので、なるべく少なくするためにLLMの初期化パラメータを追加しています。
--- a/scripts/query4vllm.py
+++ b/scripts/query4vllm.py
@@ -15,6 +15,7 @@ model = LLM(
trust_remote_code=True,
#tensor_parallel_size=2,
#max_model_len=1024
+ gpu_memory_utilization=0.2
)メモリ使用量を削減するためのオプションgpu_memory_utilizationを追加し、その値を0.2としました。
ちなみに0.1ですと「メモリが足りん!」とエラーが発生します。
3. 試してみる - transformers版
応答内容はあまり気にせず、速さに注目します。
聞いてみる
実行します。
$ python -i ~/path/to/home/scripts/query.py TinyLlama/TinyLlama-1.1B-Chat-v1.0英語で聞いてみましょう。
>>> chat_history = q("What is Doraemon?")Doraemon is a popular Japanese comic strip character created by Fujiko F. Fujio. The main character, Doraemon (also known as Nobita), is a talking cat who enjoys playing pranks on his human friend, Obi-Wan Nobita. Doraemon has appeared in over 400 original comics and over 30 animated TV shows since its debut in 1969. Its popularity has continued to grow globally, with Doraemon having his own movie in 2011, television anime series beginning in 1982, and spin-off novels and manga published in English-language media.
prompt tokens = 58
output tokens = 145 (49.316306 [tps])
total time = 2.940204 [s]
のび太は、オビ=ワン・ケノービだったのか。
推論速度
パフォーマンスの部分だけを抜き出します。
>>> chat_history = q("What is Doraemon?")
(snip)
prompt tokens = 58
output tokens = 145 (49.316306 [tps])
total time = 2.940204 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 223
output tokens = 159 (51.498514 [tps])
total time = 3.087468 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 402
output tokens = 108 (54.930001 [tps])
total time = 1.966139 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 530
output tokens = 256 (55.209918 [tps])
total time = 4.636848 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 807
output tokens = 256 (55.418982 [tps])
total time = 4.619356 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 1084
output tokens = 256 (54.470654 [tps])
total time = 4.699778 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 1361
output tokens = 256 (53.447798 [tps])
total time = 4.789720 [s]
>>>平均すると 秒あたり53.7トークンでした。
GPUリソース使用状況
こちらは起動直後。VRAMは2.5GB 使用。

数回聞いた後のVRAM状況はこちら。3.3GBと増えてます。
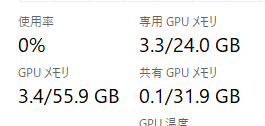
追加で聞くたびにメモリはどんどん増えていきます。max_lengthが2048 [1] なので、その付近まで試したところ、3.9GBを使用していました。
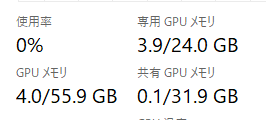
[1] generation_config.json · TinyLlama/TinyLlama-1.1B-Chat-v1.0
4. 試してみる - vLLM版
続いて、vLLM版です。応答内容はtransformersと変わらないので、速さに注目します。
$ python -i ~/path/to/home/scripts/query4vllm.py TinyLlama/TinyLlama-1.1B-Chat-v1.0推論速度
パフォーマンスの部分だけを抜き出します。
>>> chat_history = q("What is Doraemon?")
(snip)
prompt tokens = 58
output tokens = 173 (158.150231 [tps])
total time = 1.093897 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 251
output tokens = 286 (177.426465 [tps])
total time = 1.611935 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 557
output tokens = 299 (173.762724 [tps])
total time = 1.720737 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 876
output tokens = 129 (153.242923 [tps])
total time = 0.841801 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 1025
output tokens = 71 (138.546209 [tps])
total time = 0.512464 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 1116
output tokens = 560 (192.491313 [tps])
total time = 2.909222 [s]
>>> chat_history = q("Continue", chat_history)
(snip)
prompt tokens = 1696
output tokens = 102 (119.933021 [tps])
total time = 0.850475 [s]平均すると 秒あたり169.8トークンでした。
GPUリソース使用状況
起動直後、4.0GBとなっています。
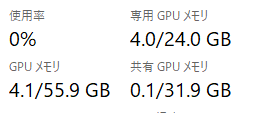
max_lengthである2048近くまで、聞き続けると、、、
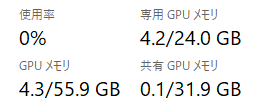
4.2GBでした。
ちなみに、オプションgpu_memory_utilization自体を追加しない場合、起動直後に20.8GBのVRAMを使用します。Tinyの意味がない。

5. まとめ
vLLMのオプションgpu_memory_utilizationを設定することで、
メモリの使用量はtransformers使用時とほぼ変わない
秒あたりのトークン生成性能は約 3.1 倍(169.8÷53.7)
になることが分かりました。vLLMすごい。
おまけ
で紹介したスクリプトを使用して作成したグラフ(の一部)がこちら。
CSVファイル内のデータを適切な時間帯(From/To)でgrepするとより対象が明確になりますね。はい。
この記事が気に入ったらサポートをしてみませんか?