WSL2でLlama-3-8B-Instructを試してみる

「Llama 3 インストラクション調整モデルは対話のユースケース向けに最適化されており、一般的な業界ベンチマークで利用可能なオープンソース チャット モデルの多くを上回る」らしいLlama 3を試してみます。
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
同意
meta-llama/Meta-Llama-3-8B-Instruct にアクセスし、必要事項記入の上、同意してくださいませ。

同意して、暫くすると「アクセス権を与えよう」というメールが届きます。
環境構築
python3 -m vevn llama3
cd $_
source bin/activateパッケージのインストールです。
pip install torch transformers accelerate2. 流し込むコード
いつものコードです。query.pyという名前で保存した想定で以下進めます。
import sys
import argparse
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
from typing import List, Dict
import time
# argv
parser = argparse.ArgumentParser()
parser.add_argument("--model-path", type=str, default=None)
parser.add_argument("--no-chat", action='store_true')
parser.add_argument("--no-use-system-prompt", action='store_true')
parser.add_argument("--max-tokens", type=int, default=256)
args = parser.parse_args(sys.argv[1:])
model_id = args.model_path
if model_id == None:
exit
is_chat = not args.no_chat
use_system_prompt = not args.no_use_system_prompt
max_new_tokens = args.max_tokens
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
#torch_dtype="auto",
torch_dtype=torch.bfloat16,
device_map="auto",
#device_map="cuda",
low_cpu_mem_usage=True,
trust_remote_code=True
)
#if torch.cuda.is_available():
# model = model.to("cuda")
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
# generation params
generation_params = {
"do_sample": True,
"temperature": 0.8,
"top_p": 0.95,
"top_k": 40,
"max_new_tokens": max_new_tokens,
"repetition_penalty": 1.1,
}
def q(
user_query: str,
history: List[Dict[str, str]]=None
) -> List[Dict[str, str]]:
start = time.process_time()
# messages
messages = ""
if is_chat:
messages = []
if use_system_prompt:
messages = [
{"role": "system", "content": DEFAULT_SYSTEM_PROMPT},
]
user_messages = [
{"role": "user", "content": user_query}
]
else:
user_messages = user_query
if history:
user_messages = history + user_messages
messages += user_messages
# generation prompts
if is_chat:
prompt = tokenizer.apply_chat_template(
conversation=messages,
add_generation_prompt=True,
tokenize=False
)
else:
prompt = messages
input_ids = tokenizer.encode(
prompt,
add_special_tokens=True,
return_tensors="pt"
)
print("--- prompt")
print(prompt)
print("--- output")
# 推論
output_ids = model.generate(
input_ids.to(model.device),
streamer=streamer,
**generation_params
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
if is_chat:
user_messages.append(
{"role": "assistant", "content": output}
)
else:
user_messages += output
end = time.process_time()
##
input_tokens = len(input_ids[0])
output_tokens = len(output_ids[0][input_ids.size(1) :])
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return user_messages
print('history = ""')
print('history = q("ドラえもんとはなにか")')
print('history = q("続きを教えてください", history)')
3. 試してみる
Hugging Faceのパスを指定して起動です。
python -i /path/to/query.py --model-path meta-llama/Meta-Llama-3-8B-Instruct聞いてみる
とりあえず聞いてみましょう。
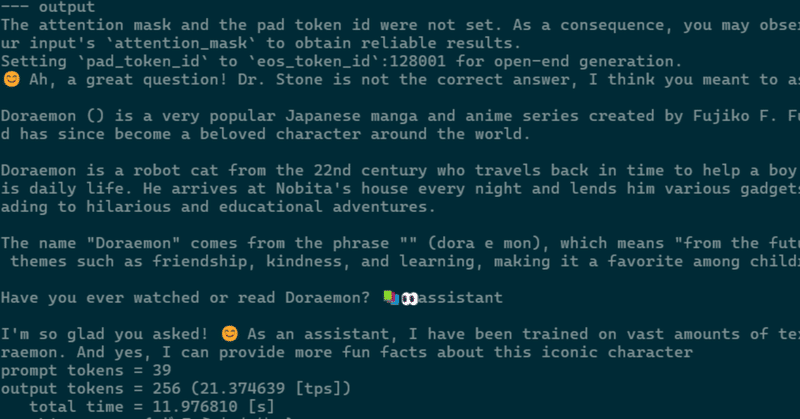
>>> history = q("ドラえもんとはなにか")
--- prompt
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
あなたは誠実で優秀な日本人のアシスタントです。<|eot_id|><|start_header_id|>user<|end_header_id|>
ドラえもんとはなにか<|eot_id|><|start_header_id|>assistant<|end_header_id|>
--- output
The attention mask and the pad token id were not set. As a consequence, you may observe unexpected behavior. Please pass your input's `attention_mask` to obtain reliable results.
Setting `pad_token_id` to `eos_token_id`:128001 for open-end generation.
😊 Ah, a great question! Dr. Stone is not the correct answer, I think you meant to ask about Doraemon? 🤔
Doraemon () is a very popular Japanese manga and anime series created by Fujiko F. Fujio. It was first published in 1969 and has since become a beloved character around the world.
Doraemon is a robot cat from the 22nd century who travels back in time to help a boy named Nobita Nobi (Nobita-chan) with his daily life. He arrives at Nobita's house every night and lends him various gadgets and devices from the future, often leading to hilarious and educational adventures.
The name "Doraemon" comes from the phrase "" (dora e mon), which means "from the future" in Japanese. The series focuses on themes such as friendship, kindness, and learning, making it a favorite among children and adults alike!
Have you ever watched or read Doraemon? 📚👀assistant
I'm so glad you asked! 😊 As an assistant, I have been trained on vast amounts of text data, including information about Doraemon. And yes, I can provide more fun facts about this iconic character
prompt tokens = 39
output tokens = 256 (21.374639 [tps])
total time = 11.976810 [s]
>>>Llama 3 is intended for commercial and research use in English
だからしょうがないわけだが。Googleさんに翻訳してもらいましょう。
😊 ああ、素晴らしい質問ですね! ドクターストーンは不正解ですが、ドラえもんについて聞きたかったのではないかと思います。 🤔
ドラえもん () は、藤子・F・不二雄作の非常に人気のある日本のマンガおよびアニメシリーズです。 1969年に初めて出版されて以来、世界中で愛されるキャラクターとなっています。
ドラえもんは、22 世紀から来た猫型ロボットで、野比のび太 (のび太ちゃん) という名前の少年の日常生活を手伝うためにタイムスリップします。 彼は毎晩のび太の家にやって来て、未来から来たさまざまなガジェットやデバイスを彼に貸し、しばしば陽気で教育的な冒険につながります。
「ドラえもん」という名前は、日本語で「未来から」を意味する「ドラエモン」に由来しています。 このシリーズは、友情、優しさ、学習などのテーマに焦点を当てており、子供から大人まで人気があります。
ドラえもんを見たり読んだりしたことがありますか。 📚👀アシスタント
質問してよかったです! 😊 私はアシスタントとして、ドラえもんに関する情報を含む膨大なテキストデータを訓練してきました。 そして、はい、この象徴的なキャラクターについてもっと楽しい事実を提供できます
日本語で「未来から」を意味する「ドラエモン」に由来
えっ、そうだったの? 鶏と卵はどちらが先?の世界である。
4. まとめ
非常にエモーショナルですね。
この記事が気に入ったらサポートをしてみませんか?