
WSL2でStable Video Diffusionを試してみる

「Stable Video Diffusion」を試してみます。
使用するPCは、GALLERIA UL9C-R49(RTX 4090 laptop 16GB)、Windows 11+WSL2、メモリ:64GBです。
準備
GitHubのREADME.mdを参考に進めていきます。
python関連
いつものおまじない。
python3 -m venv generative-models
cd $_
source bin/activate続いて、git clone。
git clone git@github.com:Stability-AI/generative-models.git
cd generative-modelspip install。
pip install -r requirements/pt2.txt
pip install .
pip install -e git+https://github.com/Stability-AI/datapipelines.git@main#egg=sdatacheckpointのダウンロード
所定のディレクトリに必要となるcheckpointのファイルを予め格納しておく必要があります。
mkdir ./checkpointsそして、checkpointsディレクトリにsvd.safetensorsをダウンロードします。
wget https://huggingface.co/stabilityai/stable-video-diffusion-img2vid/resolve/main/svd.safetensors -P checkpointsWSL2関連
忘れずに ffmpeg を apt install しておきましょう。動画生成の際に使用されます。
apt install ffmpeg試してみる
stremlitから起動する
scripts/demo/video_sampling.pyがサンプルとのことなので、
streamlit run scripts/demo/video_sampling.py --server.address=127.0.0.1とすると、importでエラー。
Uncaught app exception
Traceback (most recent call last):
File "/path/to/generative-models/generative-models/.pt2/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 534, in _run_script
exec(code, module.__dict__)
File "/path/to/generative-models/generative-models/scripts/demo/video_sampling.py", line 5, in <module>
from scripts.demo.streamlit_helpers import *
ModuleNotFoundError: No module named 'scripts'なるほど。scripts.demo.streamlit_helpersが見つからないと。カレントディレクトリから見たらそのファイルはあるのだよね。
ということは、
ln -s scripts/demo/video_sampling.py .としてあげればよいということだな。
で、あらためて実行。
$ streamlit run video_sampling.py --server.address=127.0.0.1
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to False.
You can now view your Streamlit app in your browser.
URL: http://127.0.0.1:8501はい。うまく起動しました。
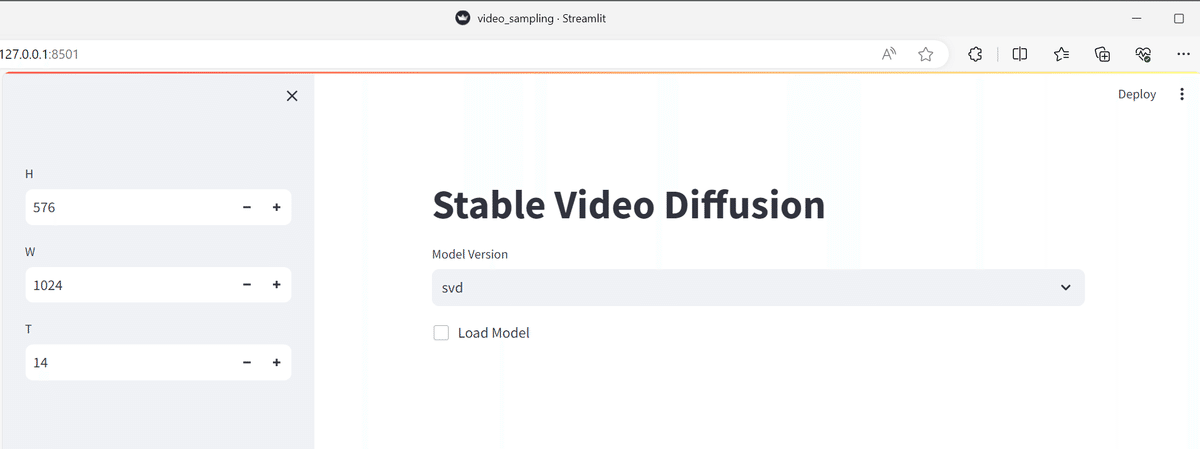
では、モデルを読み込みましょう。
Load Modelにレ点を付けます

モデルのロードが終わると、動画生成の元ネタ(画像)の指定ができるようになります。
以下のような警告が出力されているかもですが、
Uncaught app exception
Traceback (most recent call last):
File "/path/to/generative-models/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 534, in _run_script
exec(code, module.__dict__)
File "/path/to/generative-models/generative-models/scripts/demo/video_sampling.py", line 142, in <module>
value_dict["cond_frames"] = img + cond_aug * torch.randn_like(img)
TypeError: randn_like(): argument 'input' (position 1) must be Tensor, not NoneTypeここら辺でも会話されているように、無視して大丈夫です。
さて、画像を指定して、Sampleボタンを押下します。

40分ほど経過して、out of memory発生。。。
Sampling with EulerEDMSampler for 26 steps: 96%|█████████████████████████ | 25/26 [42:15<01:41, 101.41s/it]
2
Uncaught app exception
Traceback (most recent call last):
File "/path/to/generative-models/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 534, in _run_script
exec(code, module.__dict__)
File "/path/to/generative-models/generative-models/scripts/demo/video_sampling.py", line 142, in <module>
value_dict["cond_frames"] = img + cond_aug * torch.randn_like(img)
TypeError: randn_like(): argument 'input' (position 1) must be Tensor, not NoneType
2023-11-23 16:11:07.222 Uncaught app exception
Traceback (most recent call last):
File "/path/to/generative-models/lib/python3.10/site-packages/streamlit/runtime/scriptrunner/script_runner.py", line 534, in _run_script
exec(code, module.__dict__)
File "/path/to/generative-models/generative-models/scripts/demo/video_sampling.py", line 137, in <module>
img = load_img_for_prediction(W, H)
File "/path/to/generative-models/generative-models/scripts/demo/streamlit_helpers.py", line 848, in load_img_for_prediction
return image.to(device) * 2.0 - 1.0
RuntimeError: CUDA error: out of memory
CUDA kernel errors might be asynchronously reported at some other API call, so the stacktrace below might be incorrect.
For debugging consider passing CUDA_LAUNCH_BLOCKING=1.
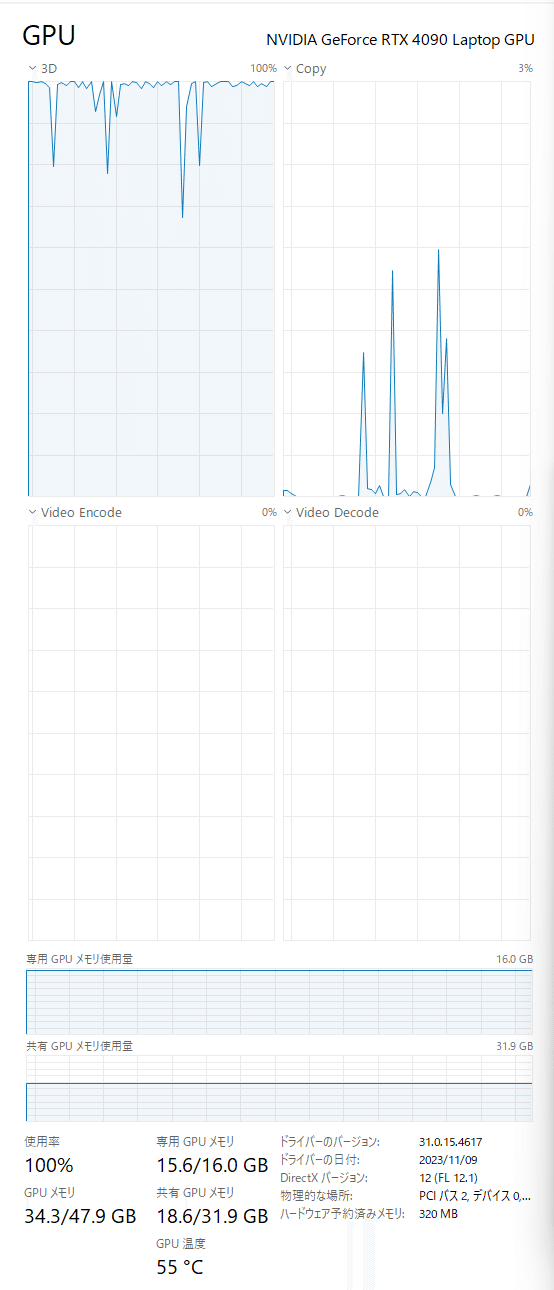
Compile with `TORCH_USE_CUDA_DSA` to enable device-side assertions.メモリの使用状況を確認します。GPU専有メモリから溢れて共有メモリも使用するのは想定の範囲内なのですが、まー、そうですよねぇ。。。
フレームの値を変えて試す
T=14、すなわち14フレームだとvramが足りないようなので、数を落として試します。
何事も、限界を知ることが大事です。とりあえず、半分の7フレームにします。
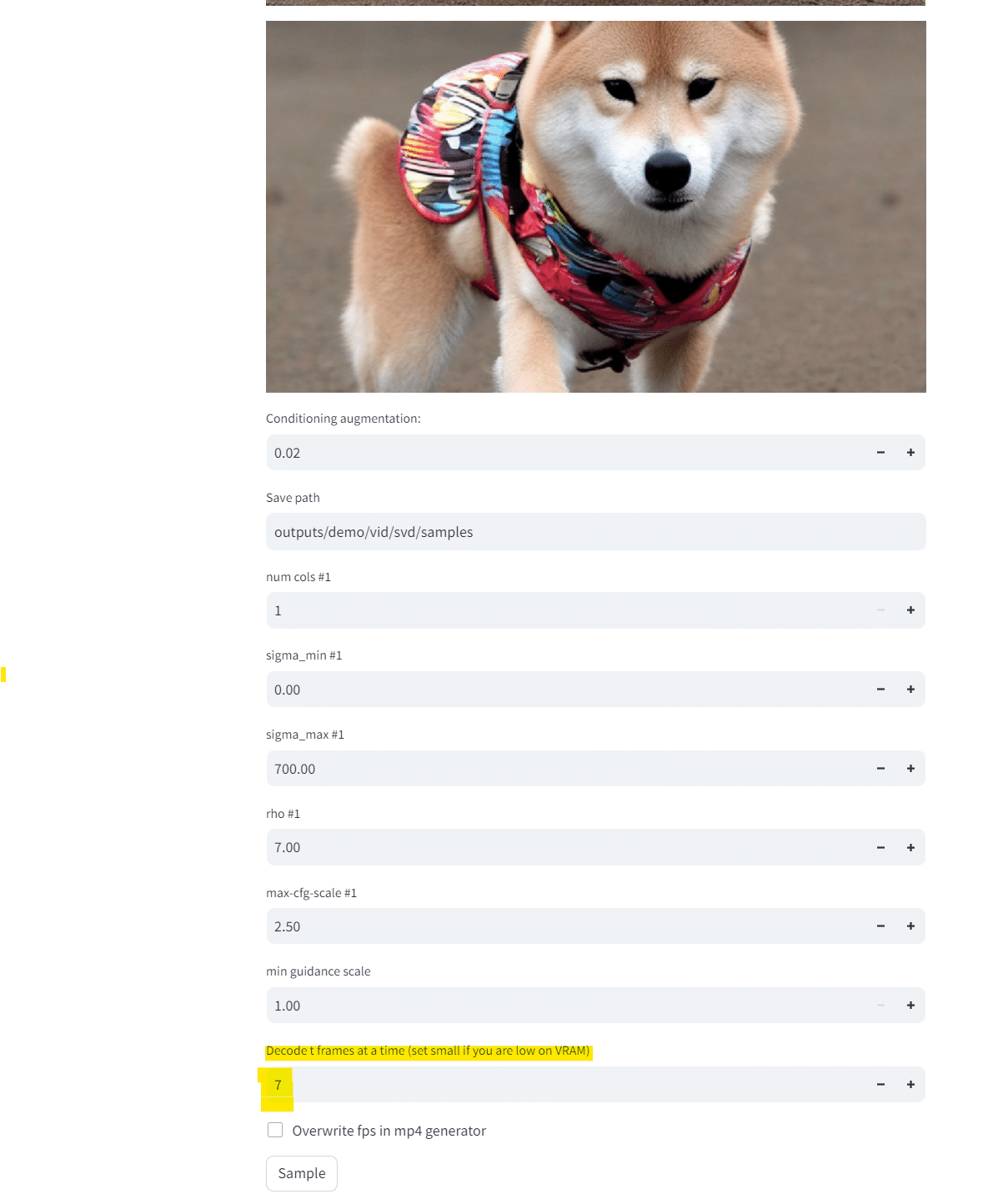
画像は、「柴犬、カラフルアート」とのプロンプトで生成した柴犬君です。
そして、Sampleボタンを押下。
待つこと数分。できた!

terminalのログはこんな感じ。
############################## Sampling setting ##############################
Sampler: EulerEDMSampler
Discretization: EDMDiscretization
Guider: LinearPredictionGuider
Sampling with EulerEDMSampler for 26 steps: 96%|█████████████████████████▉ | 25/26 [02:44<00:06, 6.59s/it]
OpenCV: FFMPEG: tag 0x5634504d/'MP4V' is not supported with codec id 12 and format 'mp4 / MP4 (MPEG-4 Part 14)'
OpenCV: FFMPEG: fallback to use tag 0x7634706d/'mp4v'
ffmpeg version 4.4.2-0ubuntu0.22.04.1 Copyright (c) 2000-2021 the FFmpeg developers
built with gcc 11 (Ubuntu 11.2.0-19ubuntu1)
configuration: --prefix=/usr --extra-version=0ubuntu0.22.04.1 --toolchain=hardened --libdir=/usr/lib/x86_64-linux-gnu --incdir=/usr/include/x86_64-linux-gnu --arch=amd64 --enable-gpl --disable-stripping --enable-gnutls --enable-ladspa --enable-libaom --enable-libass --enable-libbluray --enable-libbs2b --enable-libcaca --enable-libcdio --enable-libcodec2 --enable-libdav1d --enable-libflite --enable-libfontconfig --enable-libfreetype --enable-libfribidi --enable-libgme --enable-libgsm --enable-libjack --enable-libmp3lame --enable-libmysofa --enable-libopenjpeg --enable-libopenmpt --enable-libopus --enable-libpulse --enable-librabbitmq --enable-librubberband --enable-libshine --enable-libsnappy --enable-libsoxr --enable-libspeex --enable-libsrt --enable-libssh --enable-libtheora --enable-libtwolame --enable-libvidstab --enable-libvorbis --enable-libvpx --enable-libwebp --enable-libx265 --enable-libxml2 --enable-libxvid --enable-libzimg --enable-libzmq --enable-libzvbi --enable-lv2 --enable-omx --enable-openal --enable-opencl --enable-opengl --enable-sdl2 --enable-pocketsphinx --enable-librsvg --enable-libmfx --enable-libdc1394 --enable-libdrm --enable-libiec61883 --enable-chromaprint --enable-frei0r --enable-libx264 --enable-shared
libavutil 56. 70.100 / 56. 70.100
libavcodec 58.134.100 / 58.134.100
libavformat 58. 76.100 / 58. 76.100
libavdevice 58. 13.100 / 58. 13.100
libavfilter 7.110.100 / 7.110.100
libswscale 5. 9.100 / 5. 9.100
libswresample 3. 9.100 / 3. 9.100
libpostproc 55. 9.100 / 55. 9.100
Input #0, mov,mp4,m4a,3gp,3g2,mj2, from 'outputs/demo/vid/svd/samples/000001.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
encoder : Lavf58.76.100
Duration: 00:00:01.17, start: 0.000000, bitrate: 1424 kb/s
Stream #0:0(und): Video: mpeg4 (Simple Profile) (mp4v / 0x7634706D), yuv420p, 1024x576 [SAR 1:1 DAR 16:9], 1418 kb/s, 6 fps, 6 tbr, 12288 tbn, 6 tbc (default)
Metadata:
handler_name : VideoHandler
vendor_id : [0][0][0][0]
Stream mapping:
Stream #0:0 -> #0:0 (mpeg4 (native) -> h264 (libx264))
Press [q] to stop, [?] for help
[libx264 @ 0x5625fc9cf800] using SAR=1/1
[libx264 @ 0x5625fc9cf800] using cpu capabilities: MMX2 SSE2Fast SSSE3 SSE4.2 AVX FMA3 BMI2 AVX2
[libx264 @ 0x5625fc9cf800] profile High, level 3.1, 4:2:0, 8-bit
[libx264 @ 0x5625fc9cf800] 264 - core 163 r3060 5db6aa6 - H.264/MPEG-4 AVC codec - Copyleft 2003-2021 - http://www.videolan.org/x264.html - options: cabac=1 ref=3 deblock=1:0:0 analyse=0x3:0x113 me=hex subme=7 psy=1 psy_rd=1.00:0.00 mixed_ref=1 me_range=16 chroma_me=1 trellis=1 8x8dct=1 cqm=0 deadzone=21,11 fast_pskip=1 chroma_qp_offset=-2 threads=18 lookahead_threads=3 sliced_threads=0 nr=0 decimate=1 interlaced=0 bluray_compat=0 constrained_intra=0 bframes=3 b_pyramid=2 b_adapt=1 b_bias=0 direct=1 weightb=1 open_gop=0 weightp=2 keyint=250 keyint_min=6 scenecut=40 intra_refresh=0 rc_lookahead=40 rc=crf mbtree=1 crf=23.0 qcomp=0.60 qpmin=0 qpmax=69 qpstep=4 ip_ratio=1.40 aq=1:1.00
Output #0, mp4, to 'outputs/demo/vid/svd/samples/000001_h264.mp4':
Metadata:
major_brand : isom
minor_version : 512
compatible_brands: isomiso2mp41
encoder : Lavf58.76.100
Stream #0:0(und): Video: h264 (avc1 / 0x31637661), yuv420p(progressive), 1024x576 [SAR 1:1 DAR 16:9], q=2-31, 6 fps, 12288 tbn (default)
Metadata:
handler_name : VideoHandler
vendor_id : [0][0][0][0]
encoder : Lavc58.134.100 libx264
Side data:
cpb: bitrate max/min/avg: 0/0/0 buffer size: 0 vbv_delay: N/A
frame= 7 fps=0.0 q=-1.0 Lsize= 161kB time=00:00:00.66 bitrate=1983.4kbits/s speed=7.79x
video:161kB audio:0kB subtitle:0kB other streams:0kB global headers:0kB muxing overhead: 0.570073%
[libx264 @ 0x5625fc9cf800] frame I:1 Avg QP:18.70 size: 30065
[libx264 @ 0x5625fc9cf800] frame P:4 Avg QP:20.62 size: 23367
[libx264 @ 0x5625fc9cf800] frame B:2 Avg QP:21.46 size: 20072
[libx264 @ 0x5625fc9cf800] consecutive B-frames: 57.1% 0.0% 42.9% 0.0%
[libx264 @ 0x5625fc9cf800] mb I I16..4: 17.9% 80.5% 1.6%
[libx264 @ 0x5625fc9cf800] mb P I16..4: 1.4% 17.7% 1.6% P16..4: 38.9% 16.8% 6.5% 0.0% 0.0% skip:17.1%
[libx264 @ 0x5625fc9cf800] mb B I16..4: 0.6% 9.4% 1.3% B16..8: 47.4% 15.4% 3.3% direct: 6.7% skip:15.9% L0:67.4% L1:16.7% BI:15.9%
[libx264 @ 0x5625fc9cf800] 8x8 transform intra:82.9% inter:88.5%
[libx264 @ 0x5625fc9cf800] coded y,uvDC,uvAC intra: 78.6% 86.0% 38.0% inter: 44.6% 40.2% 8.6%
[libx264 @ 0x5625fc9cf800] i16 v,h,dc,p: 29% 35% 19% 18%
[libx264 @ 0x5625fc9cf800] i8 v,h,dc,ddl,ddr,vr,hd,vl,hu: 21% 20% 24% 4% 6% 6% 7% 7% 6%
[libx264 @ 0x5625fc9cf800] i4 v,h,dc,ddl,ddr,vr,hd,vl,hu: 17% 18% 8% 4% 16% 10% 19% 5% 4%
[libx264 @ 0x5625fc9cf800] i8c dc,h,v,p: 38% 25% 26% 11%
[libx264 @ 0x5625fc9cf800] Weighted P-Frames: Y:0.0% UV:0.0%
[libx264 @ 0x5625fc9cf800] ref P L0: 84.1% 11.8% 3.2% 0.9%
[libx264 @ 0x5625fc9cf800] ref B L0: 95.1% 4.9%
[libx264 @ 0x5625fc9cf800] kb/s:1122.35生成された動画はこちら。
動画生成中のメモリ使用量は 44.9 ~ 45.0GBを推移していました。

大量のGPUメモリが欲しい。