
WSL2でDynamiCrafterを試してみる

「事前学習されたビデオ拡散事前分布を利用して、テキストプロンプトに基づいたオープンドメインの静止画像をアニメーション化できる」らしいDynamiCrafterを試してみます。
追記 - 2024/02/07 12:50
モデル512のperframe_aeの件をissue報告したところ、設定追加頂けました。このため、最新のソースを使用する限りは別途設定を編集する必要はありません。
・add perframe_ae to 512config · Doubiiu/DynamiCrafter@623f5b4 · GitHub
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
環境構築
python3 -m venv dynamicrafter
cd $_
source bin/activateリポジトリをクローンして、
git clone https://github.com/Doubiiu/DynamiCrafter.gitパッケージのインストールです。
pip install -r requirements.txtモデルのダウンロード
必要となるモデルのチェックポイントをダウンロードします。とりあえず3つともダウンロードしましょう。
wget -P checkpoints/dynamicrafter_1024_v1 https://huggingface.co/Doubiiu/DynamiCrafter_1024/resolve/main/model.ckpt
wget -P checkpoints/dynamicrafter_512_v1 https://huggingface.co/Doubiiu/DynamiCrafter_512/resolve/main/model.ckpt
wget -P checkpoints/dynamicrafter_256_v1 https://huggingface.co/Doubiiu/DynamiCrafter/resolve/main/model.ckptダウンロードしてきたファイルは、こちら。すべて 9.8G。
$ find checkpoints/ -type f -ls
119805240 10192924 -rw-r--r-- 1 user user 10437549158 Feb 3 16:33 checkpoints/dynamicrafter_1024_v1/model.ckpt
120586242 10192924 -rw-r--r-- 1 user user 10437548346 Feb 3 16:38 checkpoints/dynamicrafter_512_v1/model.ckpt
121110530 10192920 -rw-r--r-- 1 user user 10437545635 Nov 28 23:44 checkpoints/dynamicrafter_256_v1/model.ckpt
学習させたデータセット自体は見当たらず。
2. 起動する前に
設定ファイル
モデル毎に設定ファイルが用意されています。
$ ls -l configs/
total 12
-rw-r--r-- 1 user user 2595 Feb 5 20:11 inference_1024_v1.0.yaml
-rw-r--r-- 1 user user 2381 Feb 5 20:11 inference_256_v1.0.yaml
-rw-r--r-- 1 user user 2571 Feb 5 20:11 inference_512_v1.0.yaml
$パラメータの説明はREADMEにもないので、ソースを読まないとわからんですね・・・。
コマンドライン用
単一GPU用と複数GPU用の2つあります。
# 単一GPU用
sh script/run.sh
# 複数GPu用
sh script/run_mp.shdiffコマンドで差分を見ると、大きな違いは以下の部分。
-CUDA_VISIBLE_DEVICES=0 python3 scripts/evaluation/inference.py \
+CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python3 -m torch.distributed.launch \
+--nproc_per_node=8 --nnodes=1 --master_addr=127.0.0.1 --master_port=23456 --node_rank=0 \
+scripts/evaluation/ddp_wrapper.py \
+--module 'inference' \torch.distributed.launch経由で実行している点でしょうか。しかし、8固定かいな…。
複数GPU用の処理も scripts/evaluation/inference.pyが呼び出されます。この.pyが受け付ける引数は、以下です。
--savedir: 結果の保存パス
--ckpt_path: チェックポイントのパス
--config: 設定 (yaml) パス
--prompt_dir: ビデオとプロンプトを含むデータ ディレクトリ
--n_samples: プロンプトごとのサンプル数
--ddim_steps: 正の場合は ddim のステップ、それ以外の場合は DDPM を使用
--ddim_eta: ddim サンプリングのeta (0.0 は決定的サンプリングを生成)
--bs: 推論のバッチサイズ。1である必要があり
--height: ピクセル空間での画像の高さ
--width: ピクセル空間での画像の幅
--frame_stride: 256 モデルのフレーム ストライド制御 (大きい→大きいモーション)、512 または 1024 モデルの FPS 制御 (小さい → 大きいモーション)
--unconditional_guidance_scale: プロンプト分類子なしのガイダンス付き
--seed: seed_everything のシード
--video_length: 推定ビデオの長さ
--negative_prompt: ネガティブプロンプト
--text_input: I2V モデルにテキストを入力するかどうか
--multiple_cond_cfg: 複数条件 cfg を使用するかどうか
--cfg_img: 画像調整のためのガイダンススケール
--timestep_spacing: タイムステップをスケーリングする方法。 詳細は、https://huggingface.co/papers/2305.08891 の表2を参照のこと
--guidance_rescale: https://huggingface.co/papers/2305.08891 におけるガイダンスのリスケール
--perframe_ae: フレームごとの AE デコードを使用する場合、特に 576x1024 のモデルの場合はGPU メモリを節約するために True に設定
--loop: ループビデオを生成するかどうか
--gfi: 生成フレーム補間 (gfi) を生成するかどうか
run.sh、run_mp.shともに--configオプションにて、前述のconfigファイルが指定されています。ですので、configファイルの値を修正すればそれが適用されます。
run.sh、run_mp.sh内で、これらオプションがずらっと指定されて、scripts/evaluation/inference.pyが呼び出されています。
なお、パラメータ値は、以下の順番で上書きされます。
①configファイルの値
②scripts/evaluation/inference.pyのオプションで指定された値で上書き(または初期設定)
Gradio用
コマンドラインは以下です。
python gradio_app.py --res 1024--res: DynamiCrafterの各モデルに応じて256、512、1024のいずれかを指定します。デフォルト値は 1024です。
1024: 指定したイメージから576x1024の動画
512: 指定したイメージから320x512の動画
256: 指定したイメージから256x256の動画
gradio_app.pyも下の方(Image2Videoクラス)でconfigファイルが読み込まれます。
scripts/gradio/i2v_test.py: config_file='configs/inference_'+resolution.split('_')[1]+'_v1.0.yaml'gradio_app.pyでは、run.shやrun_mp.shとは異なり、configファイル内の値が最終的なパラメータ値となります。
3. 試してみる - RTX 4090(24GB)
Gradioで試します。

(1) モデル1024
与えたプロンプトは、
a llama on the Earth programming a code
生成された動画はこちら。
DynamiCrafterをRTX 4090(24GB)でお試し中。モデルは3つ。
— NOGUCHI, Shoji (@noguchis) February 5, 2024
・576x1024動画生成: 18.3GB。Laptop GPU(16GB)だとCUDA OOM。
・320x512動画生成: 12.8GBからの37.2GBへ(他のと挙動が違う)
・256x256動画生成: 11.9GB。
添付生成動画は 576x1024のもの。https://t.co/W87YNUSiGX pic.twitter.com/ZqXhWMmXYl
動画生成時、VRAMは18.3GB使用でした。

OSメモリは13.4GBほど。
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
104564 shoji_n+ 20 0 85.1g 13.4g 761460 S 101.0 42.8 3:08.85 python生成にかかった時間は、194.05秒 です。
(3回ほど試しましたが、194~197秒の間でした。)
Saved in a_llama_on_the_Earth_programming_a_code. Time used: 194.05 seconds(2) モデル512
サンプルのこちらで試しました。

Generateボタンを押下直後は、VRAM使用量は12.8GBだったのですが、

数十秒を経過したところからVRAM使用量が増え、13.5GBほど溢れました。生成に要した時間は120.51秒でした。

Saved in time-lapse_of_a_blooming_flower_with_lea. Time used: 120.51 secondsDynamiCrafter。
— NOGUCHI, Shoji (@noguchis) February 5, 2024
320x512動画生成で花が開く! 同じ物体に見えますよね。すごい。
noteにまとめねば。 pic.twitter.com/OKC7QdWpFi
このモデルだけ挙動が違うのはなぜかしら・・・。
気になったら確認しないときが済みません。設定ファイルを比較して見ましょう。以下は1024と512の差分です。
--- configs/inference_1024_v1.0.yaml
+++ configs/inference_512_v1.0.yaml
@@ -11,16 +11,15 @@
cond_stage_key: caption
cond_stage_trainable: False
conditioning_key: hybrid
- image_size: [72, 128]
+ image_size: [40, 64]
channels: 4
scale_by_std: False
scale_factor: 0.18215
use_ema: False
uncond_type: 'empty_seq'
use_dynamic_rescale: true
- base_scale: 0.3
+ base_scale: 0.7
fps_condition_type: 'fps'
- perframe_ae: True
unet_config:
target: lvdm.modules.networks.openaimodel3d.UNetModel
params:
@@ -51,7 +50,7 @@
temporal_length: 16
addition_attention: true
image_cross_attention: true
- default_fs: 10
+ default_fs: 24
fs_condition: true
first_stage_config:モデル1024はperframe_aeパラメータがTrueと指定されており、VRAM使用が抑止されているようです。このパラメータをTrueにして、再度試してみましょう。
VRAMは12.8GB、生成時間は53.26秒でした。モデル512のときもperframe_ae: Trueを指定した方が良さそうです。

Saved in a_woman_looking_out_in_the_rain. Time used: 53.26 seconds(3) モデル256
VRAM使用量は11.9GBで、モデル512のような増加はなし。動画生成に要した時間は28.96秒でした。

Saved in man_fishing_in_a_boat_at_sunset. Time used: 28.96 secondsなお、perframe_aeパラメータがTrueにして試してみましたが、VRAM使用量、時間(29.45秒)ともに大きな変化はありませんでした。
4. 試してみる - RTX 4090 Laptop GPU(16GB)
(1) モデル1024
CUDA OOM発動により起動しませんでした。
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 1.12 GiB (GPU 0; 15.99 GiB total capacity; 14.48 GiB already allocated; 0 bytes free; 14.89 GiB reserved in total by PyTorch) If reserved memory is >> allocated memory try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF(2) モデル512
●perframe_ae: True 指定なし
VRAM 15.5GB、溢れが 37.2GB (38.0 - 0.8) 、動画生成に要した時間は196.18秒でした。RTX 4090と比較すると、1.5倍の時間です。

Saved in time-lapse_of_a_blooming_flower_with_lea. Time used: 196.18 seconds●perframe_ae: True 指定あり
VRAMは溢れず12.6GB (14.3 - 1.7)、生成時間も102.69秒と短縮されました。

Saved in a_bonfire_is_lit_in_the_middle_of_a_fiel. Time used: 102.69 seconds(3) モデル256
●perframe_ae: True 指定なし
VRAM 15.7GB、溢れが 4.7GB (5.5 - 0.8) 、動画生成に要した時間は61.45秒でした。RTX 4090と比較すると、生成時間は2倍強です。
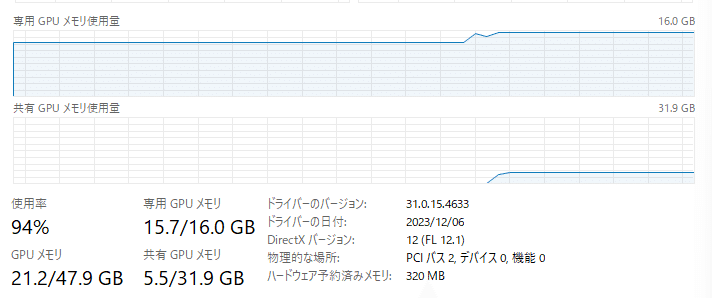
Saved in man_fishing_in_a_boat_at_sunset. Time used: 61.45 seconds●perframe_ae: True 指定あり
VRAMは溢れず11.8GB (13.5 - 1.7)、生成時間も46.48秒と短縮されました。

Saved in a_woman_looking_out_in_the_rain. Time used: 46.48 seconds5. まとめ
RTX 4090 - モデル別GPUリソースと生成速度
モデル1024 : 18.3GB、194.05秒(未測定)
モデル512: 12.8GB、53.26秒(120.51秒)
モデル256: 11.9GB、29.45秒(28.96秒)
※括弧内はperframe_ae: True指定なし
RTX 4090 Laptop GPU - モデル別GPUリソースと生成速度
モデル1024 : CUDA OOM発生
モデル512: 12.6GB、102.69秒(196.18秒)
モデル256: 11.8GB、46.48秒(61.45秒)
※括弧内はperframe_ae: True指定なし
まとめのまとめ
「perframe_ae: True」を指定して、VRAM使用量を抑止するのが吉です。
VRAM 24GB
「perframe_ae: True」を指定することで3つのモデルともに普通に動きました
VRAM 16GB
モデル1024はCUDA OOMのため起動しませんでした
「perframe_ae: True」を指定することでモデル512、256の両方ともVRAMが溢れずに動きました
補足 - 2024/2/6
run.shとrun_mp.shをよくよく見ると、
if [ "$1" == "256" ]; then
(snip)
else
(snip)
--timestep_spacing 'uniform_trailing' --guidance_rescale 0.7 --perframe_ae
fiとモデル256以外、つまりモデル512と1024は --perframe_ae が有効となっていました。
gradio_app.pyからの呼び出しのときだけ、モデル512の挙動があれれ?となるわけね・・・。
追記 - 2024/02/07 12:50
モデル512のperframe_aeの件をissue報告したところ、設定追加頂けました。このため、最新のソースを使用する限りは別途設定を編集する必要はありません。
・add perframe_ae to 512config · Doubiiu/DynamiCrafter@623f5b4 · GitHub
Crafter関連
この記事が気に入ったらサポートをしてみませんか?