
WSL2でELYZA-japanese-Llama-2-13bを試してみる

130億パラメータの「Llama 2」をベースとした日本語LLM「ELYZA-japanese-Llama-2-13b」を公開されましたので、試してみます。
使用するPCは、GALLERIA UL9C-R49(RTX 4090 laptop 16GB)、メモリは64GB、OSはWindows 11+WSL2です。
メモリ、載りきるかな…。量子化しないと厳しいかな…。
1. 準備
venv環境の構築
python3 -m venv elyza-japanese-llama-2
cd $_
source bin/activateパッケージのインストール
pip intall torch transformers accelerate2. コードの準備
使用するモデルは、elyza/ELYZA-japanese-Llama-2-13b-instructです。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
import time
llm = "elyza/ELYZA-japanese-Llama-2-13b-instruct"
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
llm,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
llm,
torch_dtype="auto",
device_map="auto",
trust_remote_code=True
)
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
# Llama 2 based
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
def build_prompt(user_query, chat_history=None):
prompt = "{chat_history}{b_inst} {system}{prompt} {e_inst} ".format(
chat_history=chat_history,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}",
prompt=user_query,
e_inst=E_INST,
)
return prompt
def q(user_query, chat_history=None):
start = time.process_time()
# 推論の実行
prompt = build_prompt(user_query, chat_history)
input_ids = tokenizer.encode(
tokenizer.bos_token + prompt,
add_special_tokens=False,
return_tensors="pt"
)
output_ids = model.generate(
input_ids.to(device=model.device),
max_new_tokens=1024,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.8,
streamer=streamer,
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
# print(output)
chat_history = prompt + output
end = time.process_time()
print(end - start)
return chat_historyでは、次へ。
3. 試してみる
聞いてみましょう。
chat_history = q("ドラえもんとはなにか")WARNING:root:Some parameters are on the meta device device because they were offloaded to the cpu.
ドラえもんは、藤子・F・不二雄によって描かれた日本の漫画作品です。1970年から週刊少年サンデーで連載が始まり、現在も映画やテレビの作品が制作され続けている人気作品です。物語の主人公であるのび太と、彼の持ち主であるねずみのドラえもんが、いろいろな道具を使って様々な冒険や騒動を繰り広げる姿が描かれています。
281.4886788
CPUにオフロードされてしまったためか、4分40秒近くかかっています。
ドラえもんは決して「ねずみ」でもなく、のび太の持ち主でもないのだが…。
続きを聞いてみます。
chat_history = q("続きを教えてください", chat_history)ドラえもんの道具は、現実世界のものとは異なり、ある要素を加えることで、非現実的な効果を生み出すという方法がとられています。例えば、「のび太のしっぽ Communicator」は、動物のしっぽを取り付けることで、その動物に変身してしまうというものです。他にも、「アニメ化能力パワー」は、アニメのキャラクターのように動くことができるようになるものや、「秘密道具カメラ」は、撮影した人や物にタ イムストップをかけることができるものなどがあります。全部で43巻の短編作品からなり、独特な世界観で多くの人々を魅了し続けています。
385.9696732
4. リソース使用状況
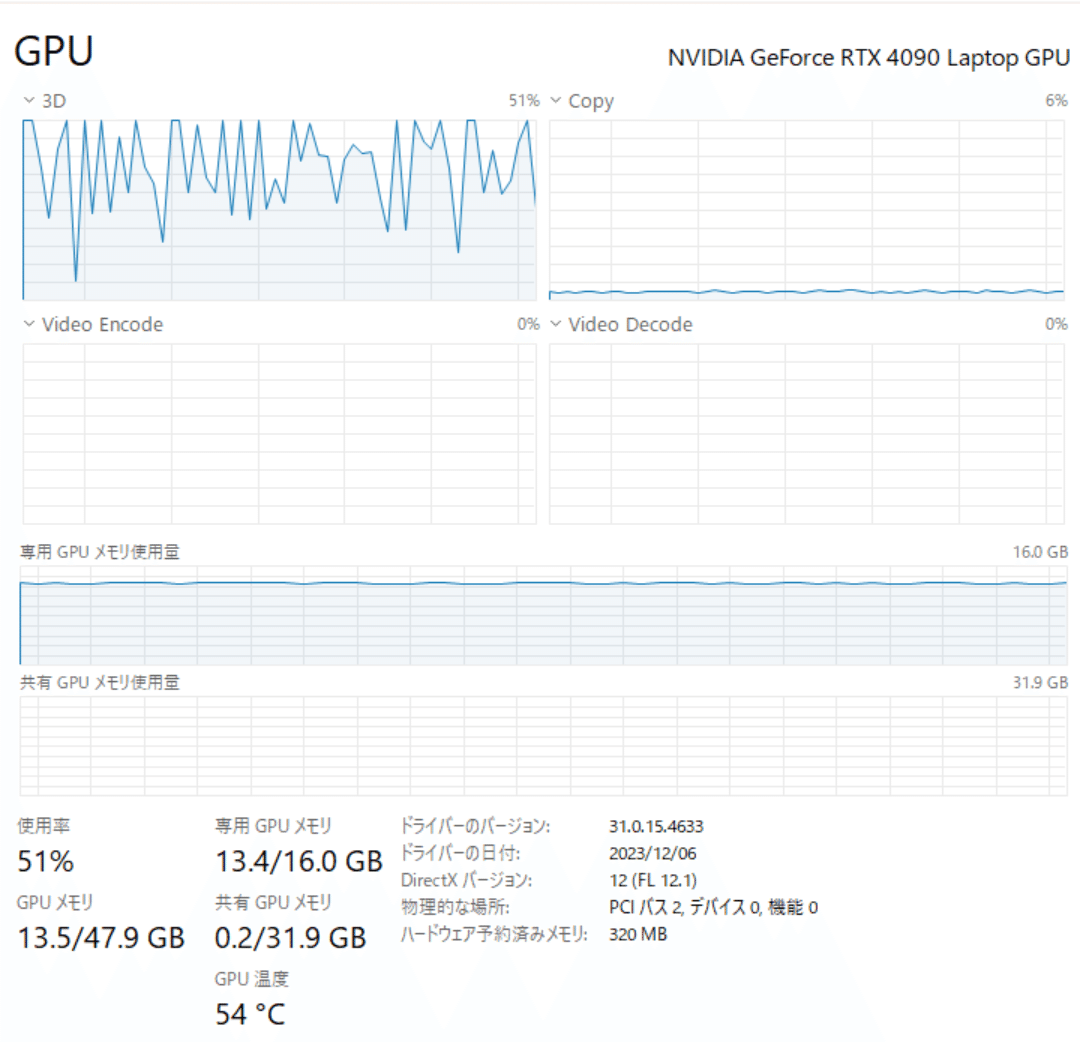
タスクマネージャー
オフロードされたためか、GPU専用メモリは13.4GBと使い切ってないです。
topコマンド
pythonコマンドが13.4G程使用しています。これがCPUオフロード分なのかしら。
Tasks: 41 total, 2 running, 39 sleeping, 0 stopped, 0 zombie
%Cpu(s): 2.9 us, 0.1 sy, 0.0 ni, 97.0 id, 0.0 wa, 0.0 hi, 0.0 si, 0.0 st
MiB Mem : 31947.9 total, 261.9 free, 14041.0 used, 17644.9 buff/cache
MiB Swap: 8192.0 total, 8149.8 free, 42.2 used. 17419.5 avail Mem
PID USER PR NI VIRT RES SHR S %CPU %MEM TIME+ COMMAND
577 shoji_n+ 20 0 76.6g 13.4g 323700 R 96.7 42.9 7:55.19 python
322 root 20 0 1229744 83928 27296 S 0.0 0.3 0:01.73 python3.10
(snip)5. まとめ
少なくとも40GBはほしいですね、GPUメモリ…。
関連
この記事が気に入ったらサポートをしてみませんか?