WSL2でMixtral 8x7B Instruct with AWQ & Flash Attention 2を試してみる

24GBのVRAMで動くという噂の「Mixtral 8x7B Instruct with AWQ & Flash Attention 2」を試してみます。
2024/1/2 18:00追記。
弊環境(RTX 4090(24GB))ですと、VRAMオフロードを無効にして実行するとCUDA OOMが発生しました。ゆえに、VRAM 24GBだけでは動かない、という結論に至りました。はい。
Mixtral 8x7B Instruct with AWQ & Flash Attention 2 🔥
— Vaibhav (VB) Srivastav (@reach_vb) December 30, 2023
All in ~24GB GPU VRAM!
With the latest release of AutoAWQ - you can now run Mixtral 8x7B MoE with Flash Attention 2 for blazingly fast inference.
All in < 10 lines of code.
The only real change except loading AWQ weights… pic.twitter.com/3KLkKQnOup
使用するPCはドスパラさんの「GALLERIA UL9C-R49」。スペックは
・CPU: Intel® Core™ i9-13900HX Processor
・Mem: 64 GB
・GPU: NVIDIA® GeForce RTX™ 4090 Laptop GPU(16GB)
・OS: Ubuntu22.04 on WSL2(Windows 11)
です。
1. 準備
python3 -m venv mixtral-8x7b
cd $_
source bin/activateパッケージのインストールです。
pip install torch acceleratetransformersは 4.36.2だとAWQがエラーを吐きます。このため、gitからビルド&インストールしましょう。
pip install git+https://github.com/huggingface/transformers.gitAWQとFlash Attentionのパッケージもインストールします。
pip install autoawq flash_attnpip listです。
$ pip list
Package Version
------------------------ ------------
absl-py 2.0.0
accelerate 0.25.0
aiohttp 3.9.1
aiosignal 1.3.1
async-timeout 4.0.3
attributedict 0.3.0
attrs 23.2.0
autoawq 0.1.8
blessings 1.7
cachetools 5.3.2
certifi 2023.11.17
chardet 5.2.0
charset-normalizer 3.3.2
click 8.1.7
codecov 2.1.13
colorama 0.4.6
coloredlogs 15.0.1
colour-runner 0.1.1
coverage 7.4.0
DataProperty 1.0.1
datasets 2.16.1
deepdiff 6.7.1
dill 0.3.7
distlib 0.3.8
einops 0.7.0
evaluate 0.4.1
filelock 3.13.1
flash-attn 2.4.2
frozenlist 1.4.1
fsspec 2023.10.0
huggingface-hub 0.20.1
humanfriendly 10.0
idna 3.6
inspecta 0.1.3
Jinja2 3.1.2
joblib 1.3.2
jsonlines 4.0.0
lm_eval 0.4.0
lxml 5.0.0
MarkupSafe 2.1.3
mbstrdecoder 1.1.3
mpmath 1.3.0
multidict 6.0.4
multiprocess 0.70.15
networkx 3.2.1
ninja 1.11.1.1
nltk 3.8.1
numexpr 2.8.8
numpy 1.26.2
nvidia-cublas-cu12 12.1.3.1
nvidia-cuda-cupti-cu12 12.1.105
nvidia-cuda-nvrtc-cu12 12.1.105
nvidia-cuda-runtime-cu12 12.1.105
nvidia-cudnn-cu12 8.9.2.26
nvidia-cufft-cu12 11.0.2.54
nvidia-curand-cu12 10.3.2.106
nvidia-cusolver-cu12 11.4.5.107
nvidia-cusparse-cu12 12.1.0.106
nvidia-nccl-cu12 2.18.1
nvidia-nvjitlink-cu12 12.3.101
nvidia-nvtx-cu12 12.1.105
ordered-set 4.1.0
packaging 23.2
pandas 2.1.4
pathvalidate 3.2.0
peft 0.7.1
Pillow 10.1.0
pip 22.0.2
platformdirs 4.1.0
pluggy 1.3.0
portalocker 2.8.2
protobuf 4.25.1
psutil 5.9.7
pyarrow 14.0.2
pyarrow-hotfix 0.6
pybind11 2.11.1
Pygments 2.17.2
pyproject-api 1.6.1
pytablewriter 1.2.0
python-dateutil 2.8.2
pytz 2023.3.post1
PyYAML 6.0.1
regex 2023.12.25
requests 2.31.0
responses 0.18.0
rootpath 0.1.1
rouge-score 0.1.2
sacrebleu 2.4.0
safetensors 0.4.1
scikit-learn 1.3.2
scipy 1.11.4
sentencepiece 0.1.99
setuptools 59.6.0
six 1.16.0
sqlitedict 2.1.0
sympy 1.12
tabledata 1.3.3
tabulate 0.9.0
tcolorpy 0.1.4
termcolor 2.4.0
texttable 1.7.0
threadpoolctl 3.2.0
tokenizers 0.15.0
toml 0.10.2
tomli 2.0.1
torch 2.1.2
torchvision 0.16.2
tox 4.11.4
tqdm 4.66.1
tqdm-multiprocess 0.0.11
transformers 4.37.0.dev0
triton 2.1.0
typepy 1.3.2
typing_extensions 4.9.0
tzdata 2023.4
urllib3 2.1.0
virtualenv 20.25.0
xxhash 3.4.1
yarl 1.9.4
zstandard 0.22.02. コード
こちらです。Mistralなので[INST]…[/INST]です。
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer
import time
#model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
#model_id = "TheBloke/Mixtral-8x7B-Instruct-v0.1-AWQ"
model_id = "casperhansen/mixtral-instruct-awq"
# トークナイザーとモデルの準備
tokenizer = AutoTokenizer.from_pretrained(
model_id,
trust_remote_code=True
)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype="auto",
device_map="auto",
attn_implementation="flash_attention_2",
trust_remote_code=True
)
streamer = TextStreamer(
tokenizer,
skip_prompt=True,
skip_special_tokens=True
)
# Llama 2 based
B_INST, E_INST = "[INST]", "[/INST]"
B_SYS, E_SYS = "<<SYS>>\n", "\n<</SYS>>\n\n"
DEFAULT_SYSTEM_PROMPT = "あなたは誠実で優秀な日本人のアシスタントです。"
def build_prompt(user_query, chat_history=None):
prompt = "{chat_history}{b_inst} {system}{prompt} {e_inst} ".format(
chat_history=chat_history,
b_inst=B_INST,
system=f"{B_SYS}{DEFAULT_SYSTEM_PROMPT}{E_SYS}",
prompt=user_query,
e_inst=E_INST,
)
return prompt
def q(user_query, chat_history=None):
start = time.process_time()
prompt = build_prompt(user_query, chat_history)
#
input_ids = tokenizer.encode(
tokenizer.bos_token + prompt,
add_special_tokens=False,
return_tensors="pt"
)
# 推論
output_ids = model.generate(
input_ids.to(device=model.device),
max_new_tokens=256,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
do_sample=True,
temperature=0.8,
streamer=streamer,
)
output = tokenizer.decode(
output_ids[0][input_ids.size(1) :],
skip_special_tokens=True
)
chat_history = prompt + output
end = time.process_time()
##
input_tokens = len(input_ids[0])
output_tokens = len(output_ids[0][input_ids.size(1) :])
total_time = end - start
tps = output_tokens / total_time
print(f"prompt tokens = {input_tokens:.7g}")
print(f"output tokens = {output_tokens:.7g} ({tps:f} [tps])")
print(f" total time = {total_time:f} [s]")
return chat_history3. 試してみよう
聞いてみる x1
chat_history = q("ドラえもんとはなにか")ドラえもん(ドラえもんです、これが)は、日本の漫画Serializer「週刊少年ジャンプ」で1969年から1982年まで連載された、小林ynamoの作品です。また、同シリーズをアニメーション化したものもあり、世界中で愛されています。
ドラえもんとは、通称の「犬」と呼ばれる、犬のような妖怪キツネの話です。ドラえもんは、主人公の坊主さんたちを助け、そのときに色んなことを、面白い話や、どうしたらいいのかわからない時には、親切に助けてくれる役割を果たします。
ドラえもんは、日本の文化のひとつでもあると言える、有名な漫画とアニメで、子どもたちから大人たちまで愛されています。また、彼の話を聞くことで、日本語を勉強することも重要です。
124.67883069999999
うーん・・・。犬じゃないし。速度も引っかかりますね。
続きを聞きます。
chat_history = q("続きを教えてください", chat_history)もちろんです!ドラえもんの話には、まださらに面白い要素があります。
例えば、ドラえもんの主人公は、坊主さんたちであり、彼らは、山寺で生活しています。彼らは、普段、簡素な生活を送っていますが、時々は、山寺での手荒な日々から、ドラえもんの助けがあって、楽しい出来事も起こったりします。
また、ドラえもんの話は、世界中で愛されているのは、彼の愛らしい品物や、面白い仕草などが、多くの人にとって、魅力的な原因となっているからです。ドラえもんは、いつも、幸せな顔をしています。彼は、いつも、楽しいことや、面白いことをしています。彼の話は、いつも、感動的で、面白いでもあります。
ドラえもんという、愛らしいキャラクターと、その話が、世界中で愛されている理由は、彼らが、人々を喜ばせる力があるということです。ドラえもんの話を聞くことで、人々は、彼らの笑顔を見ることができ、幸せを感じることができます。
それでは、もう1つ、ドラえもんの話を聞いてみてください!
414.0190795
主人公は「坊主さんたち」ではない。山寺で生活はしていない。裏山は出てくるが。
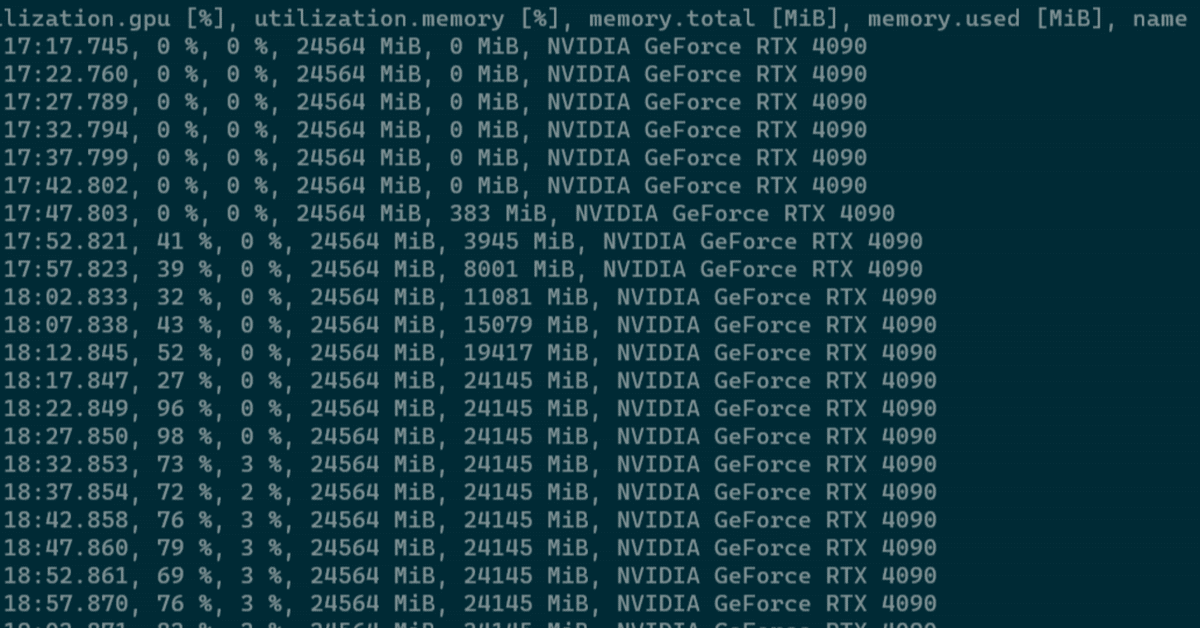
メモリ使用量は24,145MiB。搭載メモリは24,564 MiBなのでまだ余っている気もするし、余ってないと言われたらそんな気もする。
$ nvidia-smi --id=1 --query-gpu=timestamp,utilization.gpu,utilization.memory,memory.total,memory.used,name --format=csv -l 5
timestamp, utilization.gpu [%], utilization.memory [%], memory.total [MiB], memory.used [MiB], name
2024/01/02 12:51:44.245, 0 %, 0 %, 24564 MiB, 0 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:51:49.251, 0 %, 0 %, 24564 MiB, 0 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:51:54.254, 53 %, 0 %, 24564 MiB, 2963 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:51:59.260, 50 %, 0 %, 24564 MiB, 7513 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:04.262, 35 %, 0 %, 24564 MiB, 11053 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:09.265, 44 %, 0 %, 24564 MiB, 15195 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:14.268, 21 %, 0 %, 24564 MiB, 19417 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:19.270, 37 %, 0 %, 24564 MiB, 23905 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:24.273, 97 %, 0 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:29.276, 96 %, 0 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:34.283, 70 %, 3 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:39.286, 69 %, 2 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:44.288, 69 %, 3 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:49.291, 78 %, 3 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:54.295, 74 %, 3 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:52:59.298, 73 %, 3 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:53:04.301, 67 %, 3 %, 24564 MiB, 24145 MiB, NVIDIA GeForce RTX 4090
...聞いてみる x2
ためしに、RTX 4090 Laptop GPU(16GB)とRTX 4090(24GB)の両方有効にして聞いてみます。
chat_history = q("ドラえもんとはなにか")ドラえもん(です)は、日本の漫画作家、小島aaaaaaaaaacomics(あとで略称となります)が、1969年から1979年まで、青森縣にある雑 誌「あかあく」(あかあく)に連載されました。あとで、この作品は、テレビアニメシリーズとなり、1980年代に全世界で知名度を高め ました。
ドラえもんという主人公は、妖精の子どもで、彼らは、どんな悪霊も倒せます。彼らは、老人ホームで暮らしています。彼らの家では、 ホームに住んでいる老人たちと、妖精たちが、いろいろな価値観をつまんでいます。
ドラえもんシリーズは、彼らの日常的生活や、様々な物語を描いています。彼らは、時々、人間と交流することもありますが、ほとんど の場合、それは、彼ら自身で解決することができます。
ドラえもんシリーズは、今でも、世界中で愛されています。この作品は、多くの国で翻訳され、映画やゲームにも巻き込まれました。ド ラえもんシリーズは、彼らの感謝の言葉で、世界中の子供たちの心を温めます。
103.44255439999998
気持ちレスポンスが速くなった気がしますが、気のせいかも知れません。GPUのリソースを見てみましょう。
$ nvidia-smi --query-gpu=timestamp,utilization.gpu,utilization.memory,memory.total,memory.used,name --format=csv -l 5
timestamp, utilization.gpu [%], utilization.memory [%], memory.total [MiB], memory.used [MiB], name
2024/01/02 12:59:19.861, 1 %, 9 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:19.862, 0 %, 0 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:59:24.864, 16 %, 8 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:24.865, 22 %, 8 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:59:29.866, 21 %, 6 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:29.868, 40 %, 27 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:59:34.869, 42 %, 7 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:34.871, 38 %, 27 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:59:39.873, 39 %, 7 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:39.874, 31 %, 23 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:59:44.876, 36 %, 7 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:44.878, 35 %, 24 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:59:49.880, 38 %, 7 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:49.900, 32 %, 23 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:59:54.918, 39 %, 7 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:54.930, 31 %, 23 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 12:59:59.932, 31 %, 6 %, 16376 MiB, 13034 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 12:59:59.933, 39 %, 28 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 13:00:04.935, 42 %, 7 %, 16376 MiB, 13115 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 13:00:04.936, 30 %, 22 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 13:00:09.937, 41 %, 7 %, 16376 MiB, 12997 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 13:00:09.939, 35 %, 25 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 13:00:14.940, 35 %, 6 %, 16376 MiB, 12998 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 13:00:14.942, 35 %, 25 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 13:00:19.945, 39 %, 7 %, 16376 MiB, 12994 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 13:00:19.945, 36 %, 26 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 13:00:24.947, 26 %, 6 %, 16376 MiB, 12994 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 13:00:24.948, 37 %, 27 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 13:00:29.949, 39 %, 7 %, 16376 MiB, 12994 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 13:00:29.951, 32 %, 24 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 13:00:34.952, 39 %, 7 %, 16376 MiB, 12994 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 13:00:34.966, 27 %, 19 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090
2024/01/02 13:00:39.969, 0 %, 3 %, 16376 MiB, 12994 MiB, NVIDIA GeForce RTX 4090 Laptop GPU
2024/01/02 13:00:39.970, 0 %, 0 %, 24564 MiB, 12747 MiB, NVIDIA GeForce RTX 4090RTX 4090 Laptopはティスプレイ表示にも使用しています。今回のモデルのロードに要した総メモリ量は、RTX 4090のメモリ使用量である12,747 MiBの倍とすると 25,494 MiB。オーバーヘッドもあるからですかね?
1枚で40GBぐらいあると答えは分かるわけだが・・・。
4. まとめ(訂正)
24GB(RTX 4090)で Mixtral 8x7B Instruct with AWQ & Flash Attention 2 は動きました。以下、「5. VRAMオフロードしてました」に記載のとおり、VRAMオフロードを無効にするとCUDA OOMが発生しました。ゆえに、弊環境のRTX 4090(24GB)だとVRAMが足りず起動しない、ということになります。
ただ、応答結果がちょっと微妙な気がします。
5. VRAMオフロードしてました(追記)
model生成時の引数を autoから cuda に変更して実行したところ、
device_map="cuda"CUDA OOMが発生しました。
return t.to(device, dtype if t.is_floating_point() or t.is_complex() else None, non_blocking)
torch.cuda.OutOfMemoryError: CUDA out of memory. Tried to allocate 20.00 MiB. GPU 0 has a total capacty of 23.99 GiB of which 0 bytes is free. Including non-PyTorch memory, this process has 17179869184.00 GiB memory in use. Of the allocated memory 23.01 GiB is allocated by PyTorch, and 24.49 MiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONFつまり、VRAM 24GBだけでは動かないということがわかりました。
6. 時間計測(追記)
なんだか気持ちが悪くてすっきりしないので、GPUx1とGPUx2のそれぞれでトークンあたりの生成時間を計測しました。max_new_tokensを256として測定しています。
とりあえず、3回計測して平均出してみます。
GPU x1のとき
(注)VRAMオフロードを有効とした状態での測定です。
$ CUDA_VISIBLE_DEVICES=0 python -i query.py
>>> chat_history = q("ドラえもんとはなにか")
Драegoнбоール (ドラえもん) は日本のテレビアニメシリーズで、小さな竜(ドラゴン)ドラえもんと、彼の友達と家族が出てくる話です。このアニメシリーズは、小学校児たち向けに描かれ、楽しくて、教育的でもあります。ドラえもんは、主人公であり、彼の親しい友達 との関係や、彼自身の成長と学びを通して、常に新しい国々と Metropolises を訪れます。このアニメシリーズは、世界的に人気があり 、1990年代に始まって、今でも新しいエピソードが生まれています。
prompt tokens = 56
output tokens = 232 (2.830738 [tps])
total time = 81.957415 [s]
>>> chat_history = q("続きを教えてください", chat_history)
ドラえもん (Doraemon) は、小学校児たちの心を動かす、豊富な物語とともに、それぞれの国や都市を訪れ、アドベンチャーを経験する ことで、彼らが世界的な地域についての理解を深めることもできます。ドラえもんは、時代の経過とともに、現代に向けて進化し、テク ノロジーや文化についての知識を広めることも重要な役割を果たしています。また、このアニメシリーズは、日本語を学ぶことも、海外 の子供たちにとっての良いチャンスとなっています。
さらに、ドラえもんは、日本の文化を世界中に��
prompt tokens = 340
output tokens = 256 (1.225469 [tps])
total time = 208.899603 [s]
>>> chat_history = q("続きを教えてください", chat_history)
さらに、ドラえもんは、日本の文化を世界中に広め、皆さんがそれを知っていただくことで、国際的なやり取りや理解を促進することも 重要な役割を果たしています。ドラえもんは、日本の文化の要素と、現代の文化の交差を示しています。彼らは、日本の伝統的な食べ物 や服装、ホテルなどの文化的な要素を、現代的で魅力的なアニメで表現します。そして、これらの要素は、世界的な子供たちの心をそれ ぞれの国のカルチャーに興味を引き、それらと国際的なつながりを作り出します。
さらに、ドラえもんは、子供たちの道を
prompt tokens = 650
output tokens = 256 (0.638873 [tps])
total time = 400.705633 [s]
>>>うーん、入力のトークン数が増えると秒間の生成トークン数(以下、tps)がめっきりはっきりくっきりと落ちてます。これは、、、確実に溢れている。
「続きを」ではなく最初から問いかけ直すと、以下のように2.81 [tps]、2.73 [tps] という結果。
>>> chat_history = q("ドラえもんとはなにか")
ドラえもん(Doraemon)は、日本の漫画とアニメーションシリーズです。主人公は、時代転生して来た猫バカ猫(ネコベン)の一種、ド ラえもんと呼ばれる、四次元ポケットから様々なToolsを引き出して人間の男の子、野口ノブิタを助ける、AI(人工知能)が備わったロ ボットです。彼らの出会いは、野口の祖父の山口ハチemanがドラえもんの世界で、彼らの家族を助けるために、ドラえもんを持って帰っ てきたおかげです。
ドラえもんは、1969年から1996年にかけて、小小さん(小澤明)によって描かれた漫画シリーズで、
prompt tokens = 56
output tokens = 256 (2.819474 [tps])
total time = 90.797090 [s]
>>> chat_history = q("ドラえもんとはなにか")
ドラえもん (Doraemon) は、日本の漫画・アニメ・电影serial で、名作作家の福岛FX(フクイドH)が1969年に作り上げ、1970年に連載 開始した。
ドラえもんは、未来から来た猫バリアントのロボットで、小学校児のNOPPENの家族に寄席し、NOPPENに様々な役に立つアドベントURESを 経験する。ドラえもんは、時代を超えて愛されているキャラクターの1つで、日本の文化で深い地位を占めています。
以上がドラえもんとは何かについての説明です。他に何かを知りたい情報があれば、おっしゃってください。
prompt tokens = 56
output tokens = 253 (2.733366 [tps])
total time = 92.559854 [s]
>>>最初の問いかけの3回平均は 2.7929 [tps] でした。
GPU x2のとき
$ CUDA_VISIBLE_DEVICES=0 python -i query.py
>>> chat_history = q("ドラえもんとはなにか")
ドラえもん(ドラえもん dollfie)は、日本の漫画家・ミュージシャン AXSART(エイクスアート)さんがデスIGNし、日本のフィギュアメーカー・ベアリーリボト(ベアリーリボット)が製造・販売する、チビの男性キャラクターです。
ドラえもんは、1980年代に漫画創作活動を開始し、現在もその人気を受け持っています。ドラえもんの世界観は、日本の民俗や古い町並 みなど、日本の文化を鮮明に描き出したもので、多くの人の心に響き、愛されています。
ドラえもんというキャラクターは、漫画以外にもアニ
prompt tokens = 56
output tokens = 256 (4.751487 [tps])
total time = 53.877867 [s]
>>> chat_history = q("続きを教えてください", chat_history)
番と、ゲーム、小説、アニメなど、多様なメディアで盛大に普及し、グローバルなポップカルチャーとなりました。
ドラえもんの世界には、様々なキャラクターが出てくるので、人気のあるキャラクターたちと共に、ドラえもんの世界が広がります。そ して、ドラえもんの愛好者たちがグッズや衣類などを通じて、ドラえもんと同様の生活を送ります。
さらに、ドラえもんの人気は、世界中の多くの国に広がっており、現在もドラえもんへの愛さは徐々に広がっています。
prompt tokens = 366
output tokens = 231 (4.786091 [tps])
total time = 48.264860 [s]
>>> chat_history = q("続きを教えてください", chat_history)
ドラえもんは、世界中で愛されるキャラクターであると同時に、日本語を学びたい人たちにとっても重要な役割を果たしています。ドラ えもんの漫画やアニメは、日本語の文化を簡単に理解することができ、日本語の勉強を支援することができます。
ドラえもんの好奇心旺盛な性格や、常に元気な表情は、多くの人にとって、笑いにつながり、ストレスを軽減することができます。ドラ えもんは、幼い子どもたちから大人まで、すばру趣味や、心にやさしいタレントとして愛されています。
ドラえもんの人気
prompt tokens = 650
output tokens = 256 (4.531461 [tps])
total time = 56.493916 [s]
>>>入力のトークン数が増えようが、安定した速度です。GPU x1と条件合わせるために、あと2回最初の問いかけを測定します。
>>> chat_history = q("ドラえもんとはなにか")
ドラえもん(ドラえもんでございます)は、日本の漫画・アニメシリーズです。1969年に由木祐作先生が初めて描き下ろし、1970年から 毎週木曜日に掲示する漫画シリーズでした。主人公は、猫に変身した小学生の道 INCLUDING TAG* 津endetaro です。ドラえもんは、子どもたちにとっての理想的な友達であり、「もののけもの」(妖怪)との関わりを通して、幼児の心に贈る愛と巧みな話題の取り扱いで知 られています。
ドラえもんは、1980年代以降、日本全国で大きく普及し、多種のメディアに
prompt tokens = 56
output tokens = 256 (4.514812 [tps])
total time = 56.702251 [s]
>>> chat_history = q("ドラえもんとはなにか")
ドラえもん (Doraemon) は、日本の漫画やアニメーションで知られているキャラクターです。彼は、hentai Kamederu (変態亀デル) の後輩で、未来から来た猫リとーン (猫ロイドン) として、小林 Futoshi (小林 フートシ) の孫の友達として生活しています。ドラえмоんは、隠し小箱 (フクラミド) から様々な奇跡の道具を現代に持ち込んでくれます。ドラえもんは、日本の子供たちの心を温め、楽しませる 役割を果たしています。
prompt tokens = 56
output tokens = 215 (4.833369 [tps])
total time = 44.482432 [s]最初の問いかけの3回平均は 4.6884 [tps] でした。
結論
(1) 秒間あたりのトークン生成数
3回平均は、GPU x2のほうが 1.67 倍程度の速度ということが分かりました。
・GPU x1: 2.7929 [tps]
・GPU x2: 4.6884 [tps]
2枚だと処理が分散されるから自ずと速くなる…ですね。2枚で1.67倍ですし。
GPU x2のほうがかなり速かったです。つまり、私の体感は当てにならないということ。心改め、適当なことは書かずきちんと計測します。
(2) プロンプトのトークン数が増えたとき
VRAM 24GBだとあふれています。入力増えたら「そりゃそうだよね」と言われればそうなんですが…。
関連
この記事が気に入ったらサポートをしてみませんか?