
Ubuntu-Docker環境のRe:dashが動かなくなったその後に

おはようございます、ねすたです、よろしくどうぞお願いします。
今回は、自社で使っているDockerイメージによるRe:dash環境が再起動時に動かなくなった際、原因とその解決策を書き留めたいと思います。
環境について
今回動かなくなった環境はこちらです。
・Ubuntu 18.04(AWSにて作成)
・Re:dash Docker 9.0.0-beta.b42121
異変
Redash用のEC2インスタンスを再起動した際、Redashのクエリが動かなくなり、ん?と思って停止→起動をかけたら今度はログイン画面すら表示されなくなってしまった。
原因を探る
最初は「Dockerだけ起動失敗した?」と思いながらターミナル上で直接インスタンスに入り、
$ docker-compose up -dを実行したら、
ERROR: Couldn't connect to Docker daemon at http+docker://localhost - is it running?って言われた。
ググってみると、どうやらDocker-daemonの起動に失敗しているご様子。
詳細を見てみる。
$ sudo service docker statusこんな感じ。

なので強制的に起動する。
$ sudo start dockerすると、
sudo: unable to resolve host ip-10-8-80-155: Resource temporarily unavailableやら「Internal Server Error」やら言われてコマンドが何も打てない事態に。
途方に暮れる
詰んだ・・・と思いつつ再度ssh接続してみると、
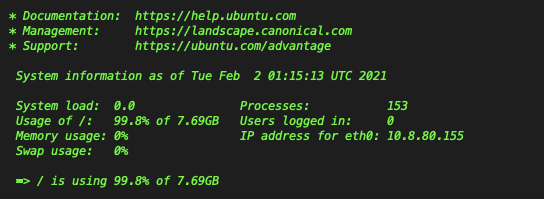
[Usage of]項目を見ると、ストレージパンパンやん...!
という訳で今回の原因はストレージが不足してコマンドが実行できなくなったことでした。
解決策
ストレージを増やす。
EC2コンソールより対象インスタンスを停止(しなくても変更できそうですが一応)し、「ストレージ」タブからボリュームIDリンクを押下してボリユーム一覧画面に遷移する。
対象ボリュームを選択し、アクションボタンからボリューム変更を行う。

今回は8GB→32GBに変更。
確認
インスタンスを再起動後、ブラウザからRedashできているかなーと思いましたがそう甘くはなかったのでターミナルからインスタンスに入る。
本当はdocker-daemonの起動→Dockerの起動ってやるべきだと思うのですが、今回はUbuntuの再起動をしました。
$ sudo rebootしばらくしたらまたターミナルから入り、確認します。
$ sudo service docker statusActive項目が「failed」から「active」になりました。

dockerも起動済みでした。
ブラウザからも問題なく使えるようになりました。
結論
ターミナルで入ったときにアラート出してくれていたんだなあ...
灯台下暗しでした。
こちらからは以上です。
この記事が気に入ったらサポートをしてみませんか?