
TensorFlow Liteをバージョンアップして『AiRCAM』のAI処理を10%以上高速化!

こんにちは、Heavy metal is very very healthyです。ナビタイムジャパンで『AiRCAM』のAI・画像処理周りの開発を担当しています。
『AiRCAM』はドライブレコーダーアプリ(以下ドラレコ)ですが、端末側でAI・画像処理を動かすエッジAIアプリでもあります。今回は、そのエッジAIならではの苦労であるパフォーマンス改善のお話をしようと思います。
ドラレコアプリの性能要件は非常に厳しい
運転中のドライバーに対してリアルタイムによる警告を行う必要があるため、ドラレコアプリに求められる性能要件は一般的なアプリ(ゲームを除く)に比べ非常に高いです。fpsだと最低でも10fpsは必要です。つまり、1枚の画像を処理するのに与えられた時間は、わずか100msecです。
そういったごく限られた時間の中で、複数のAIモデルを動かしたり、画像処理を行って様々な機能を実現したりすると、あっという間にその時間は使い切ってしまいます。そのため、機能追加だけ行うのではなく定期的にプログラム全体のパフォーマンス改善を行うことが必要になります。
なおざりになりがちなミドルウェアの更新
とはいうものの、機能追加とは異なりパフォーマンス改善は時間をとってやれば必ず速度改善するという保証がありません。また、ファーストリリース以降、定期的にパフォーマンス改善は行ってきたため、細かい点で速度改善できる余地はあまり残されていませんでした。そこで、今回ミドルウェア
の更新に踏み切りました。
『AiRCAM』のAI・画像処理は、2つのミドルウェアの上で実現されています。
TensorFlow Liteは、AIによる画像認識処理、OpenCVは画像処理を行います。
TensorFlow Liteは、TensorFlowに含まれるモバイルフレンドリーなサブセットミドルウェアです。そのバージョンは、Github上のTensorFlowバージョンと同一です。
TensorFlow LiteのAIの画像認識処理とは、画像の中から車・人・横断歩道といったオブジェクトの検出や、その画像が高速・高速/一般並走道路・トンネルを走行している画像なのかを分類する処理です。これが、全体の処理の90%と、かなりの比重を占めています。一方、OpenCVの画像処理は画像データのカラーチャンネルの変換やリサイズ、画像データに含まれる輪郭形状の抽出といったそれぞれが軽量な処理になります。
TensorFlow Liteはファーストリリース以降、更新をずっと行っていませんでした。その理由としては、セキュリティ面で深刻な問題のあるケースがなかったのが一つ。もう一つは、『AiRCAM』のAI・画像処理プログラム全体がC++で書かれているため、ライブラリをソースコードからビルドする必要があり、なかなか難儀な作業であったためです(ターゲットOSもAndroid、iOSと2つもありビルド方法も異なります)。
気がつくと、最新のものと比べるとメジャーバージョンは2.x系と変化はないのですが、マイナーバージョンが5世代ほどの乖離がありました。
バージョンアップによる驚くべき効果
重い腰をあげ、最新のバージョン2.10 (対応当時)のビルド方法を調べました。案の定、いろいろとビルド方法が変わっていました。特に、変更が激しかったのがiOSです。C++ I/F用の静的ファイル生成用に用意されていたMakefileによるビルドのシェルスクリプトがなくなっていました。
v2.7からMakefileによるビルドは廃止されていました。
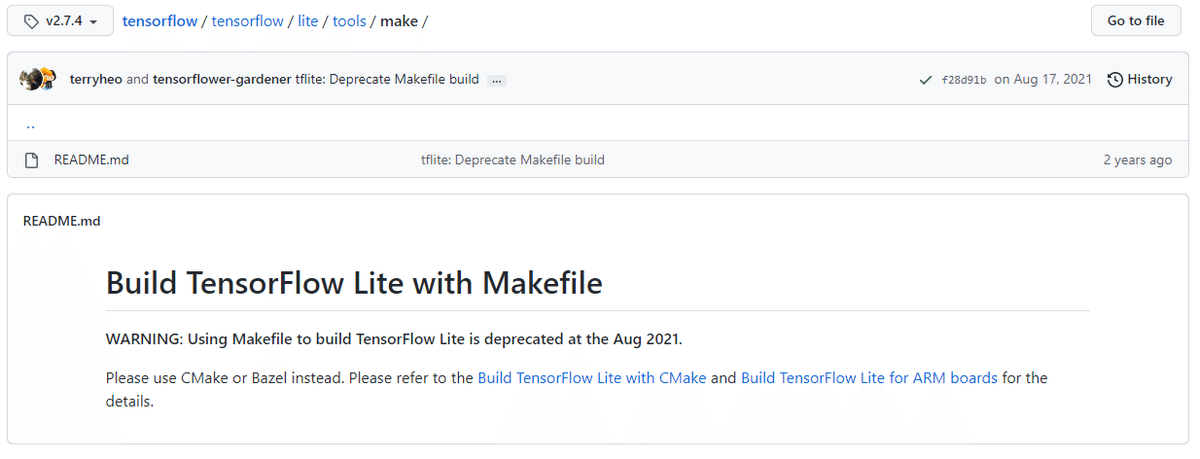
仕方なく、公式ドキュメントに載っている C I/F用のフレームワークビルド方法でフレームワークを生成し、呼び出し側のC++のコードも CのI/Fを呼び出すように修正しました。
Android側はBazelでのビルド方法でしたが、それが健在だったので以前構築した環境が使えました。ただ、BazelはTensorFlow Liteのバージョンがサポートするバージョン以上のものを使う必要があるので、アップデート作業は発生しました。Bazelはサポート対象がほぼTensorFlow Liteのバージョンごとに違うので注意が必要です。
そして、ビルド!巨大なミドルウェアなのでビルド時間もそこそこかかかります。数分単位では当然終わらず、ビルド環境のスペックにもよりますが最低でも1時間近くはかかります。。たまに、ビルド完了後にミドルウェアの更新の設定ミスに気づいたり、ビルドの最終段階のリンクステップでエラーとなり、やり直しとなったときは、ほんとに泣きたくなります。
そういった苦労を経て、ようやくできたビルド成果物でパフォーマンス測定をしてみた結果、Android/iOSともに10%以上という大幅な遅延改善が見られました!!以下のグラフは、1枚の画像に対する『AiRCAM』のAI・画像処理全体の平均遅延時間の改善効果を旧2.4と最新版2.10とで比べた結果となります。

端末の負荷状況によっては上記と異なる結果になる可能性があります。
他のメンバーが気づいてくれたのですが、どうも 2.10.0 の以下の対応がかなり効果あったようです。試しに、2.9系でパフォーマンス測定をしても速度改善はされませんでした。

TensorFlow LiteのC/C++ APIではAIモデルをメモリ展開する際にFlatbuffersを使ってシリアライズ化しているのでこの部分がメージャーバージョンアップでAIモデルのロード以外に、推論時のデータアクセスにも効果があったようです。
今回の学びと、今後の対策
TensorFlow Liteは、頻繁にアップデートされており、この記事を書いている段階でも、もうすでに2.11が公開され、2.12もRC版がリリースされています。やはり、今回のように大きな効果をもたらす変更が含まれている可能性があるので、もう少し頻繁に更新内容をチェックして負荷なく定期的なアップデートを実現する必要があるなと痛感しました。
今後は、ミドルウェアのGithubリリースページのRSSから最新版をビルド、
成果物からリグレションとパフォーマンステストを自動実行できる仕組みを構築していこうと思っています。今回は、最後までお読みいただきありがとうございました!