
SNSから取得できる渋滞情報はどのくらいの精度なのか検証してみた

こんにちは、デルタです。ナビタイムジャパンの研究開発部門で道路規制や渋滞情報などの交通情報提供を担当しています。
渋滞情報、何で確認してる?
みなさんは車でお出かけする際に、渋滞情報を何で確認されていますか?
渋滞表示のある地図を見る、ニュースを見る、ラジオを聴くなど様々な方法がありますが、最近はSNSで確認されている方も多いのではないでしょうか。
今回はSNSで拡散される「渋滞」に関する投稿について、情報の鮮度や渋滞が起こっている場所の位置特定はどの程度の精度なのかについて調査してみようと思います。
2022年6月19日(日)に発生した中央道での渋滞を対象に、
当日のTwitterでつぶやかれたツイートのうち「中央道」「渋滞」の両方のワードを含むツイートの数の推移は実際の渋滞開始時刻やピーク時刻と比較してどうだったか?
出現回数の多かったワードから詳細な渋滞地点は推測できるか?
の二つの視点から調査していきます。
また、調査過程で使用したPythonでのTwitter API利用方法や、昨年11月に公開されたTwitter API v2などについても記載させていただきます。
調査対象の渋滞を見てみる
6月19日(日)に起こった中央道での渋滞をターゲットにして調査していきます。
下図のマップ上の赤線が渋滞、オレンジ線は混雑、紫の線は事故が起こっている場所になります。
画像中央の中央道上り、大月ICから八王子JCTのあたりにご注目ください。


渋滞は14時ごろから八王子JCTを先頭に始まりました。

談合坂SAまで続いた18時がピークとなっています。

渋滞は22時ごろには収束したようです。
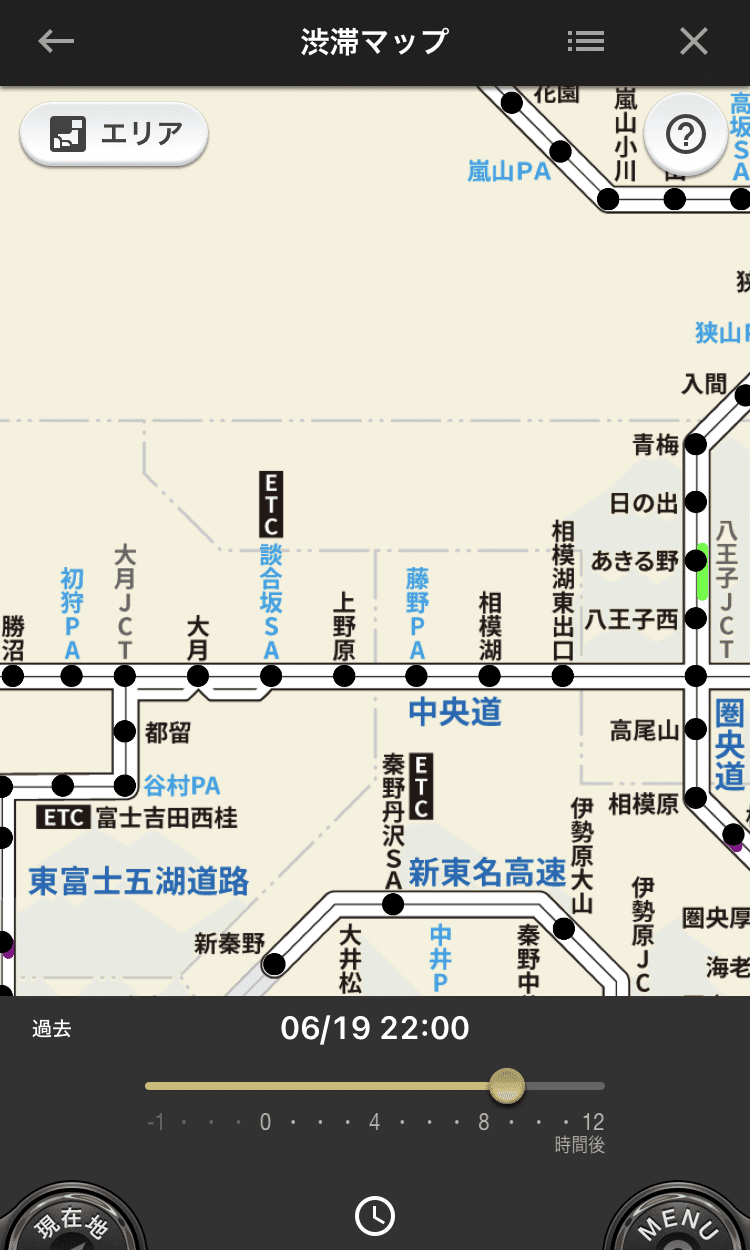
こちらは当社のカーナビアプリである「カーナビタイム」の過去の渋滞を確認する機能を利用しています。
Twitter APIを利用した検索方法
まずはTwitter APIを利用して当日のTwitterでつぶやかれたツイートのうち「中央道」「渋滞」の両方のワードを含むツイートの数の推移を確認していきます。
利用するのはSearch TweetsのRecent searchです。
以下はAPIの説明になりますので、興味のある方以外は読み飛ばしていただいて大丈夫です。
Recent searchの使い方
検索クエリに一致する過去7日間のツイートが返却されます。
クエリガイドに従ったクエリを作成する必要がありますが、普段検索で使っているようにワードを指定すれば大方は大丈夫です。
例えば今回のように二つのワードを含むツイートに絞りたい時は「中央道 渋滞」のようにスペース区切りで入れればOKです。(「+」で繋いでも良い)
クエリさえ指定すれば結果が返却されますが、今回の場合は日付や時間帯も指定したいので
start_time
end_time
の二つのパラメータも指定します。
また、max_resultsについてはデフォルトが10と小さめの設定になっているので用途によっては増やすといいと思います。
レスポンスですが、デフォルトではツイートのidと本文のみが返却されます。
今回はこれで十分ですが、その他の情報が欲しい場合はtweet.fieldsを指定することになります。
Pythonでの実装例としてはこのような感じです。
def search_recent(keyword: str) -> list:
# max_resultsを超えて取得したい場合に使用するトークン
next_token = None
# timeは指定の形式で設定
params = {
"query": keyword,
"start_time": "%Y-%m-%dT%H:%M:%SZ",
"end_time": "%Y-%m-%dT%H:%M:%SZ",
"max_results": 100
}
# ツイート本文格納用
tweets = []
while True:
if next_token is not None:
params["next_token"] = next_token
parsed_params = urllib.parse.urlencode(params)
# bearer_tokenには自分のトークンを設定してください
headers = {"Authorization": f"Bearer {bearer_token}"}
res = requests.request(
"GET", endpoint_search_recent, params=parsed_params, headers=headers)
if res.status_code != 200:
raise Exception(res.status_code, res.text)
res_json = res.json()
# 取得ツイート数が0なら終了
if res_json["meta"]["result_count"] == 0:
break
tweets.extend([data["text"] for data in res_json["data"]])
next_token = res_json.get("meta").get("next_token")
if next_token is None or tweet_count >= limit_count:
break
return tweetsTwitter API v1.1からv2への変更点
Twitter API v2のRecent searchはTwitter API Standard v1.1のSearch Tweetsに対応しています。
主な違いは以下の通りです。
レスポンスがシンプルになり使いやすくなった(v1.1ではすべてのfieldを返却していたが、必要なものだけ選べるようになっている)
v1.1では「Premium」以上の有料契約が必要であった過去7日より以前のツイートを取得する方法が変わった(v2ではall searchを利用することにより7日より以前のツイートも取得することが可能です、後述するAcademic Researchというアクセスレベルが必要になります)
searchの違いについて詳しくはこちらを参照してください。
また、Twitter API全体の変更点としては
一番下のアクセスレベルであればアカウント作成時の申請が不要になった(以前は英作文をしての申請が必要でした)
Conversation IDの導入によりリプライの流れを解析できるようになった
Essential / Elevated / Academic Research の3つのアクセスレベルが設定された(今までは有料だった範囲が申請すれば無料で使えるようになっているようです)
などがあります。
なお、v1.1から移行するにはDeveloper Portalからプロジェクトの設定が必要になります。(Bearer Tokenもプロジェクト設定時に取得可能)
渋滞に関連したツイート数推移
では、さっそくTwitter APIを利用して取得したツイート数の推移を確認しましょう。

渋滞している時間帯(画像ピンク色の範囲)はかなりツイート数が増えているようですね!
ツイート数が伸び始めたのは16時、ツイート数のピークは19時~20時、収束したのが23時のようです。

実際の渋滞は14時ごろ始まり、18時にピークを迎え、22時ごろには収束しています。
全体的に現実より1~2時間ほど遅れてTwitterに反映されるようです。
頻出名詞の解析による渋滞箇所の特定
渋滞の開始収束・ピーク時刻の比較に加え、渋滞が起こっている具体的な場所は推測可能なのかを検証してみます。
例えば、冒頭でお見せしたマップの赤線(渋滞)上のIC名などが出ているとある程度特定ができると言えそうです。

検証方法としては、先ほど抽出した「中央道」「渋滞」を含むツイートのうち、ツイート数のピークであった19時のツイートに出てきた名詞で出現回数が多いものを抜き出します。
解析には MeCab というオープンソース形態素解析エンジンを使用しています。

こちらが結果になります。
指定ワードの「中央道」「渋滞」以外では渋滞中に発生していた「事故」というワードや「サンデードライバー」などが目立ちますね。
残念ながら具体的な場所の特定まではできなさそうです。
まとめ
今回は、SNS(Twitter)で拡散される渋滞情報の鮮度や位置特定の精度について検証を行ってみました。
結論としては、
SNSでの渋滞情報収集は鮮度が1~2時間ほど低い
場所の特定は難しい
などが言えそうです。
ただ、渋滞が起こっている時間帯にツイート数が増えているのは確認できたため、これから通る予定の道で何かが起こっていることを検知する目的では使えそうですね。
また、今回は取得しなかったのですが、位置情報もRecent search APIのリクエスト時の設定により取得可能です。
Twitterにツイートを投稿するユーザー自身によって位置情報が公開設定になっている時のみ取得できるため、渋滞時にそのようなユーザーがいればより詳細な位置の特定ができるケースもありそうですね。
今回使用したソースコードはこちらで公開しています。
ちなみに当社のカーナビアプリでは事故が起こった際の渋滞の予測なども行っています。
お出かけの際に、ぜひ利用してみてください!