
Pythonで「儲かりそうなアメリカ株」を見つける_その2

割安株の見つけ方
本noteは、↓でやったことの解説noteです。
上記のnoteで、Pyhonを使ってスクレイピングして、株価情報を取得し「割安株」を一気にスクリーニングしました。まだ読まれてない方は先にどうぞ。
おさらいで、山口さんの書籍で紹介されていた「割安株」の見つけ方を図解したものがこちらです。詳しくはこちらで解説してます。
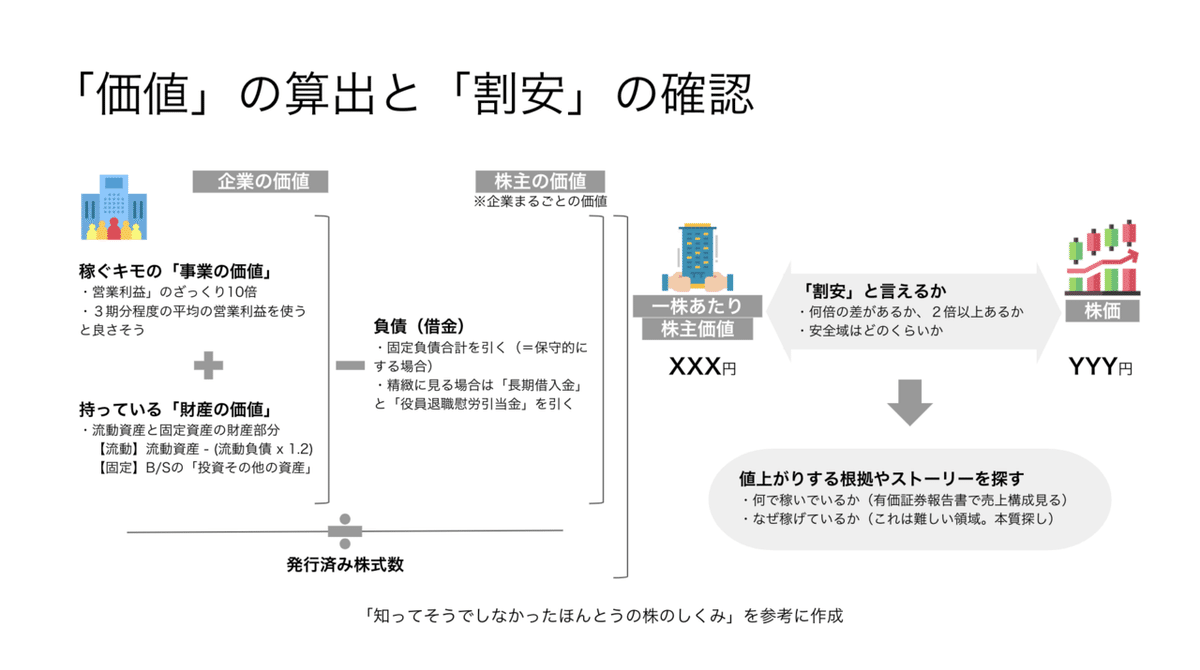
※書籍を参考に本note作成者が作成
結論として下記の株が「割安」となりました。NASDAQ銘柄のみでやった結果です。
AAL:American Airlines Group アメリカン航空
AMCX:AMC Networks A AMC ネットワーク A
AXAS:Abraxas Petroleum アブラクサス ペトロリアム
CENT:Century Communities Inc センチュリー コミュニティーズ
CHRS:Coherus Biosciences コヘラス バイオサイエンス
CMLS:Cumulus Media Inc A キュムラス メディア A
CXDC:China XD Plastics Co Ltd チャイナXDプラスチックス
DISCB:Discovery Inc ディスカバリー
FOX:Fox B フォックス B
GSKY:GreenSky A グリーンスカイ A
HA:Hawaiian ハワイアン
LTRPB:Liberty TripAdvisor Holdings Inc リバティ・トリップアドバイザー
NCMI:National Cinemedia Inc ナショナル シネメディア
NHTC:Natural Health Trends Corp ナチュラル ヘルス トレンズ
SIGA:SIGA Technologies Inc シガ テクノロジーズ
SND:Smart Sand Inc スマート サンド
SPKE:Spark Energy Inc A スパークエナジー A
TGA:TransGlobe Energy Corp トランスグローブ エナジー
TUSK:Mammoth Energy Services Inc マンモス エナジー サービス
UONE:Urban One Inc アーバン・ワン
※21/01/23時点の株価と market watchで取得した企業情報より
※SBI証券で取扱のあるNASDAQ銘柄が母数
これらの「割安株」を楽に一気に見つけるためにやった事の紹介です。
こんな方におすすめです
・株式投資を勉強中の方
・Pythonを勉強中で、投資など何に活かしたい方
・Googleスプレッドシートやエクセルを勉強中の方や得意な方
・日本株だけじゃなく、米国株も好きな方
本noteで、以下が出来るようになることが見込まれます。
①Pythonを使った基本的な「スクレイピング」のやり方、テクニック
②山口式の銘柄選定を、実際に活かせられる
③一社ずつ調べなくても、網羅的なリストから手軽に銘柄を見つけられる
※Pythonは最低限必要な箇所で使用し、その他はエクセルやスプレッドシートの便利機能も使いますこんな方におすすめです
なるべく初学者の方にわかりやすいように、Pythonは必要最低限のところでしか使ってません。がしかし、全く触ったことがない方は、本noteを買うのもったいないのでご注意ください。
また、株や会計のことを多少は知っている方がこの後の内容がわかりやすいです。全く知らない方は、今回参考にしたこちらがおすすめです。
楽しんでいただけたら幸いです。
大きな流れ
下記の流れで、米国の「割安株」を一気に探します。
step 1:株価サイトをスクレイピングして企業情報の収集、リスト化する
step 2:山口氏の手法で「割安株」をリストから一気に探す
step 1:株価サイトをスクレイピングして企業情報の収集、リスト化する
それでは参りましょう。
●「割安株」を見つけるために必要な企業情報
山口さん流の「割安株の見つけ方」には以下の企業の会計情報が必要になります。
①営業利益(3期分程度)
②流動資産額と投資その他の資産合計
③流動負債額
④固定負債額(もしくは、長期借入金と役員退職慰労引当金)
⑤発行済株式数
⑥現在の株価
で、こちらを米国株ver.に置き換えると下記となります。
① Operating income (for about three fiscal years)
② Total current assets and investments and other assets
③ Current liabilities
④ Long-term liabilities (or long-term debt and reserve for directors' retirement benefits)
⑤ Number of shares issued
⑥ Current stock price
※DeepLで翻訳
①〜⑤を下記サイトから取得し、⑥はGoogleスプレッドシートの関数を用いて取得します。
●スクレイピングする
前回、NYSEの株の情報を取ったときと同様に、こちらのサイトからスクレイピングをさせて頂きます。ありがとうございます。
①〜⑤については各企業の下記の部分をスクレイピングする必要があります。
① Operating income (for about three fiscal years)
Operating income(営業利益)というジャストの項目がないため、GrossIncome(売上高総利益)からSG&A Expence(販売費及び一般管理費)を差し引いて求めます。なのでこの2項目をスクレイピングします。

https://www.marketwatch.com/investing/stock/goog/financials
② Current assets(流動資産額)

https://www.marketwatch.com/investing/stock/goog/financials/balance-sheet
③ Current liabilities(流動負債額)
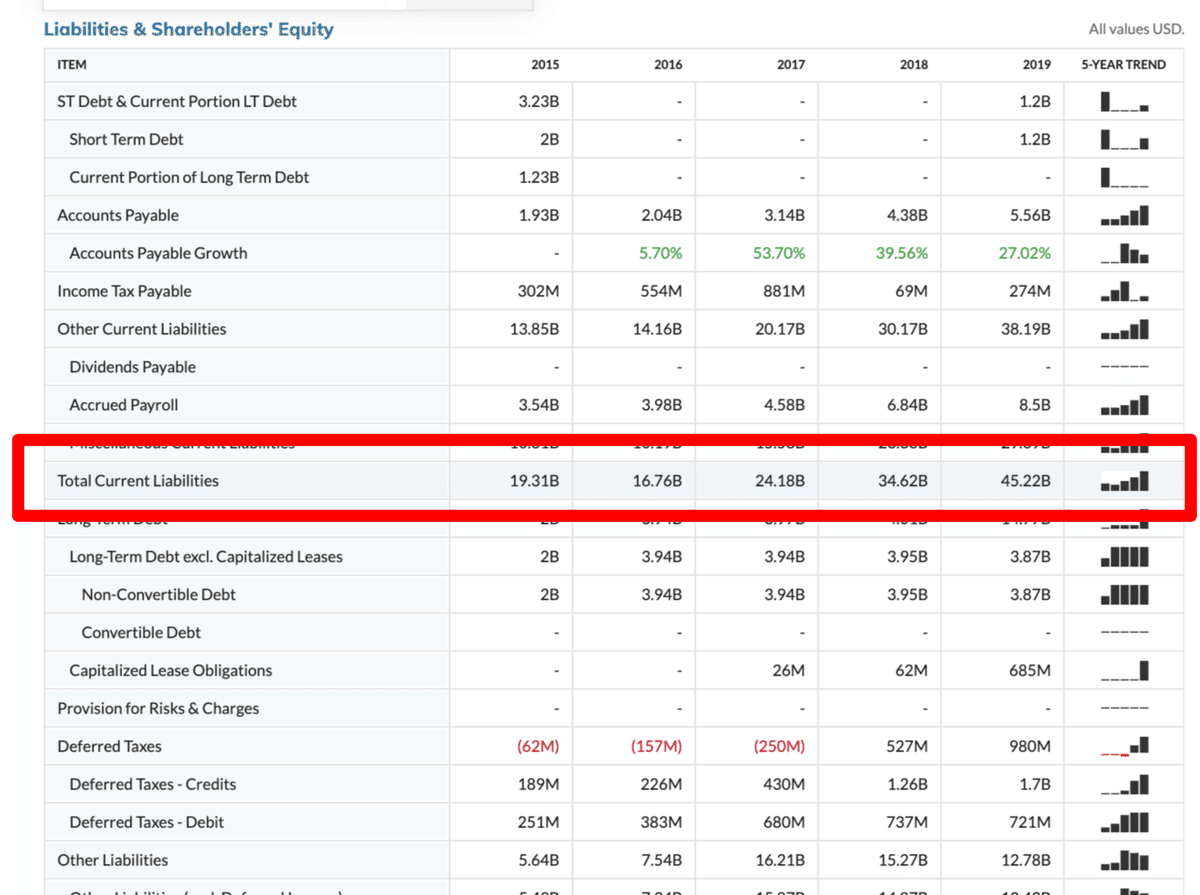
https://www.marketwatch.com/investing/stock/goog/financials/balance-sheet
④ Long-term liabilities (or long-term debt and reserve for directors' retirement benefits)固定負債額(もしくは、長期借入金と役員退職慰労引当金)

https://www.marketwatch.com/investing/stock/goog/financials/balance-sheet
役員退職慰労引当金というもののジャストなものがないので近しいものとして「Provision for Risks & Charges」を取得します。
⑤ Number of shares issued(発行済株式数)

https://www.marketwatch.com/investing/stock/goog?mod=mw_quote_tab
⑥ Current stock price(現在の株価)
Googleのスプレッドシートの関数を用いて、株価を取得します。便利です。

①〜⑤のスクレイピングにはPythonでやりますが、いつものように「Jupyter Notebook」を使います。とても便利です。
使ったことがない方はこちらの無料部分をお読みください。
1社試しにやってみる
試しに1社やってみます。GOOGの情報を取得します。
使用するライブラリのimport
#基本的なデータ処理のため
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
#スクレイピングをするために必要
import requests
from bs4 import BeautifulSoup
from io import StringIO
import requests
import time
#必須ではありませんが一応
import datetime①を取得する
#URLのセット
url="https://www.marketwatch.com/investing/stock/goog/financials?mod=mw_quote_tab"
#request
test_url = requests.get(url)
#BeautifulSoup
test_soup = BeautifulSoup(test_url.text,"html.parser")
#数値が入っているtdタグだけを取得
test_information = test_soup.find_all("td", class_="overflow__cell")
#確認
test_information
このようにhtml情報が取得できたらOKです。この中から、今回欲しい数値(つまり、GrossIncomeとSG&A Expence)を探します。
下記で取得できます。
#該当する要素を取得
#Gross Incomeの抽出
gross_income = test_information[57:62]
#SG&A Expenseの抽出
sga_expense = test_information[78:83]
print("●Gross Income")
print(gross_income)
print("")
print("●SG&A Expense")
print(sga_expense)
無事取得できてるようですが、不要な英字が入ってるのでこれを消します。
不要な文字列を削除する用の関数
あとで使いまわせるように関数にしておきます。
#不要な文字列の削除
def delete_words(x):
x = str(x).replace("""<td class="overflow__cell"><div class="cell__content"><span class="">""","").replace("</div>","").replace("</span>","").replace("</td>","").replace("""<td class="valueCell">""","").replace("</p>","").replace("""<p class="data lastcolumn">""","").replace("'","").replace("""<li class="kv__item">""","").replace("""<small class="label">Shares Outstanding</small>""","").replace("""<span class="primary">""","").replace("""<span class="secondary no-value">""","").replace("""</li>""","")
x = str(x).replace(""" ""","").replace("\n","").replace("""<tdclass="overflow__cell"><divclass="cell__content">""","").replace("""<spanclass="negative">""","").replace("""<smallclass="label">Open</small>""","").replace("""<spanclass="primaryis-na">""","")
return x#Gross IncomeとSG&A Expenceの抽出
print(delete_words(gross_income))
print(delete_words(sga_expense))
無事取得できました。↓の部分がしっかりスクレイピングされてます。
※本書では3期分と書かれてましたがここでは5期分取得してみてます。

このように他の数値もスクレイピングしていきます。
②〜④の取得
#URLのセット
url_bs="https://www.marketwatch.com/investing/stock/goog/financials/balance-sheet"
#request
test_url_bs = requests.get(url_bs)
#BeautifulSoup
test_soup_bs = BeautifulSoup(test_url_bs.text,"html.parser")
#数値が入っているtdタグだけを取得
test_information_bs = test_soup_bs.find_all("td", class_="overflow__cell")
#確認
test_information_bs
#Total Current Assetsの抽出
total_current_assets = test_information_bs[134:139]
#Total Current Liabilitiesの抽出
total_current_liabilities = test_information_bs[323:328]
#Total Investments and Advancesの抽出
total_investments_and_advances = test_information_bs[190:195]
#Long-Term Debtの抽出
long_term_debt = test_information_bs[330:335]
#Provision for Risks & Chargesの抽出
provision_for_risks_and_charges = test_information_bs[365:370]
#不要な文字列を削除して表示
print("Total Current Assets")
print(delete_words(total_current_assets))
print("")
print("Total Current Liabilities")
print(delete_words(total_current_liabilities))
print("")
print("Total Investments and Advances")
print(delete_words(total_investments_and_advances))
print("")
print("Long-Term Debt")
print(delete_words(long_term_debt))
print("")
print("Provision for Risks & Charges")
print(delete_words(provision_for_risks_and_charges))
・⑤の取得
#発行済株式数(SHARES OUTSTANDING)を抽出する
#URLのセット
url_shares = "https://www.marketwatch.com/investing/stock/goog?mod=mw_quote_tab"
#request
test_url_shares = requests.get(url_shares)
#BeautifulSoup
test_soup_shares = BeautifulSoup(test_url_shares.text,"html.parser")
#数値が入っているliタグだけを取得
test_information_shares = test_soup_shares.find_all("li", class_="kv__item")
#確認
test_information_shares※欲しい数値が入っているタグが、tdからliに変わってます。

#発行済株式数(SHARES OUTSTANDING)を抽出する
shares_outstanding = test_information_shares[4]
print("Shares Outstanding")
print(delete_words(shares_outstanding))
これで、GOOGの①〜⑤までの情報を取得できました。
print("①のために必要な情報")
print("Gross Income")
print(delete_words(gross_income))
print("")
print("SG&A Expense")
print(delete_words(sga_expense))
print("")
print("②〜④")
print("Total Current Assets")
print(delete_words(total_current_assets))
print("")
print("Total Current Liabilities")
print(delete_words(total_current_liabilities))
print("")
print("Total Investments and Advances")
print(delete_words(total_investments_and_advances))
print("")
print("Long-Term Debt")
print(delete_words(long_term_debt))
print("")
print("Provision for Risks & Charges")
print(delete_words(provision_for_risks_and_charges))
print("")
print("⑤")
print("Shares Outstanding")
print(delete_words(shares_outstanding))
⑥の取得
Googleスプレッドシート上で下記で株価を取得します。
=googlefinance("GOOG","price")
以上で、「割安株」かどうかを判定する企業の情報が整いました。
これをあとは繰り返しやり続ければいいわけですが、そんなことをやってたら元号が令和から歯姫に変わってしまいます。
って事で退屈なことはPythonにやってもらいます。
数千社に一気にやってみる
●取得したい企業のティッカーリストを用意します
SBI証券を使用しているため、SBI証券で取扱のある銘柄を対象にします。コチラからSBIで取り扱いのある米国株をズラーっとコピペします。
コピーしたものを、一度エクセルかスプレッドシートにペーストした上で、csv形式でダウンロードして下記のようなファイルを用意します。
●取得したい企業のティッカーリストを読み込みます
あなたのディレクトリをセットしてcsvファイルを取り込んでください。
#データの読み込み
companies_list = pd.read_csv("/Users/[あなたのディレクトリ]/company_list_210103")
companies_list.head()
●NASDAQだけ切り出す
#NASDAQのみを抽出して格納
companies_list_NASDAQ = companies_list[companies_list.market == "NASDAQ"]
#何社あるか確認
len(companies_list_NASDAQ)こちらで確認したところ、2,116社ありました。
●スクレイピング結果を格納するようのデータフレームを先に作ります

貴重なお時間で読んでいただいてありがとうございます。 感謝の気持ちで、いっPython💕