
【AIって何だろう】ニューラルネットワークの逆伝播【5/5】

どうも、G検定攻略ガイド管理人です。
第5回のコラムは、ニューラルネットワークの逆伝播についてのコラムです。
前回の記事では「ニューラルネットワークの順伝播」という内容で、入力層から入れたデータがどのように出力層に辿り着くかを解説しました。
今回は、その出力をもとにモデルをチューニングする逆伝播について解説したいと思います。
前回記事を読んでいない方は、こちらからどうぞ!
【2/5】リンク
【3/5】リンク
【4/5】リンク
出力をもとによりよい出力へ
前回のコラムでは「順伝播」についてお話ししました。これで入力したデータから出力層まで伝播し、何らかの出力を得られているはずです。

ディープラーニングでは、出力データと教師データ(解答)の誤差を数値化して、その数値ができるだけ小さくなるようにモデルをチューニングするという手法をとります。

出力と正解の誤差は「誤差関数」とよばれる関数で定義されます。具体的には上記で示すような式を用いるのですが、ここではまず概念をとらえることにしましょう。
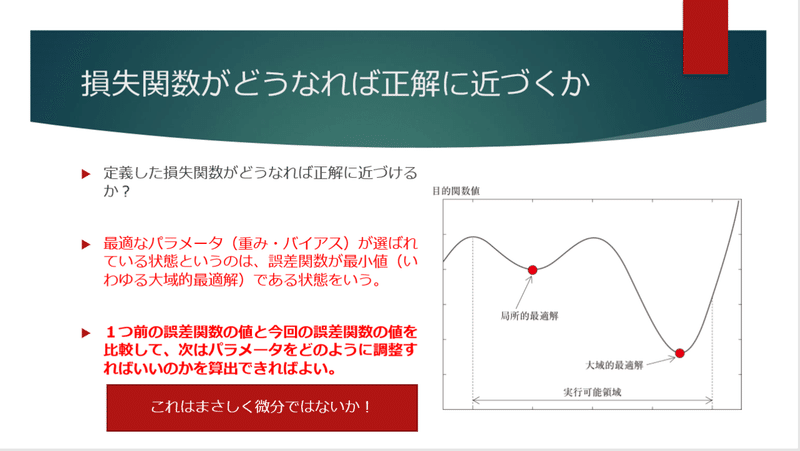
要は「定義した誤差関数が最も小さくなる値を探せばよい」ということになります。
最も小さいということは「大域的最適解」といわれる部分にあたります。ということはこの最小値を常に探し続けるということになるので、関数の傾きに沿って降りていけばいいのですから、数学的には微分という手法が最も適しているということになります。
それでは、具体的にどのようにアプローチするのかを見てみましょう。
「勾配降下法」というアプローチ
まずは損失関数の偏微分を考えます。

勾配を計算することで、最小値を目指すための方向(符号)が見えてきます。
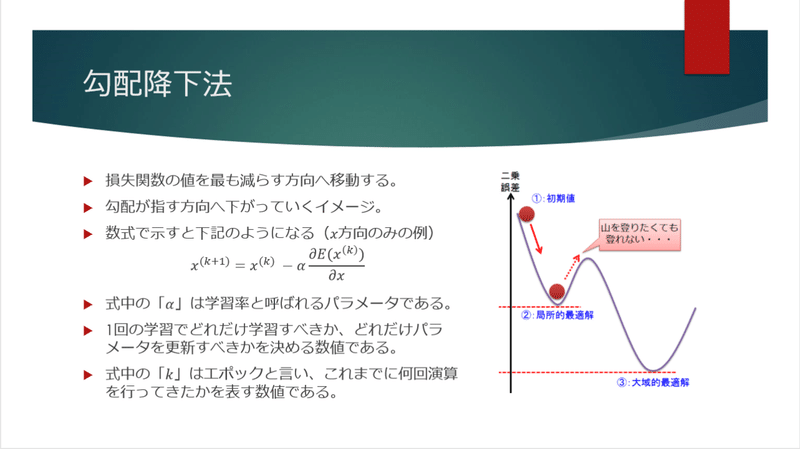
勾配をから導かれた「進むべき方向」に向けて、損失関数の値を減らすように動きます。
ここで間違えてはいけないのは、この操作は1回で完結するものではなく、複数回の演算処理が行われる中で少しづつチューニングされるものだということです。
学習率と呼ばれる「動く大きさ」を決めるパラメータをもとに損失関数を小さくする方向へ複数回演算しながらチューニングを進めていきます。
学習率というのは下記のように決定されます。
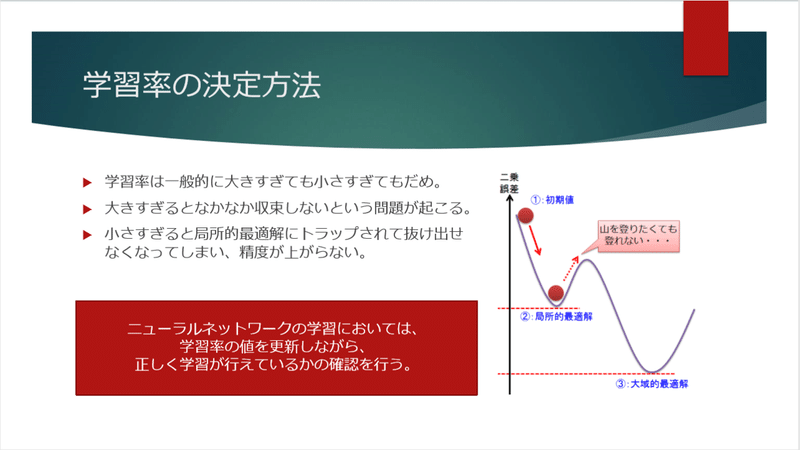
これをニューラルネットワークに適用すると、下記のようなステップとなります。

さらに誤差逆伝播法というアプローチ
勾配降下法で誤差を計算してチューニングすると、その手前の隠れ層にもチューニングの結果を伝達しなくてはなりません。
そもそも、求めたい解答とずれているのは隠れ層が原因なのですから。
ということで、それを伝えていく方法は「誤差逆伝播法」と呼ばれています。
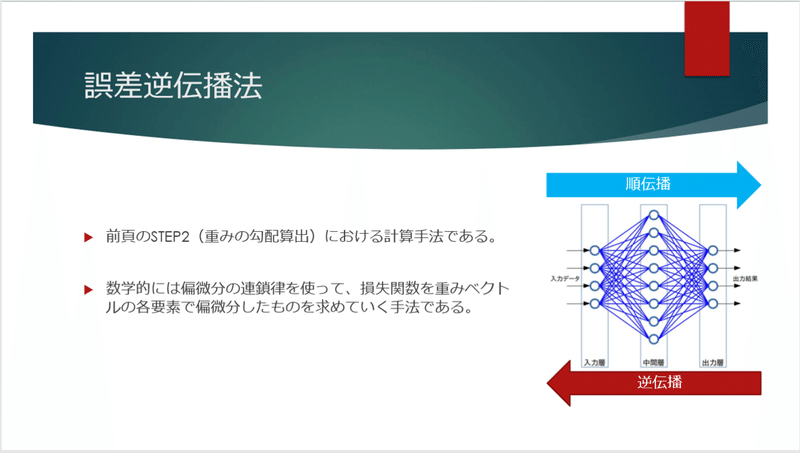
ここに関しては、イメージだけをお伝えしようと思います。数学的には偏微分しながらネットワークを遡っていき、重みを調整するという作業をしています。
ここで、実は根が深い重大な問題があるのです。
それが「勾配消失問題」という問題でした。

実は「活性化関数」はこれを大きく改善するための手法だったのですね。
これまでは何のために使っているかうまく説明できていなかった活性化関数ですが、実は逆伝播の際に誤差をきちんと伝達するために一役買っていたのです。
こうしてきちんと誤差を伝えて調整しても、実は局所最適解にハマるパターンがあります。
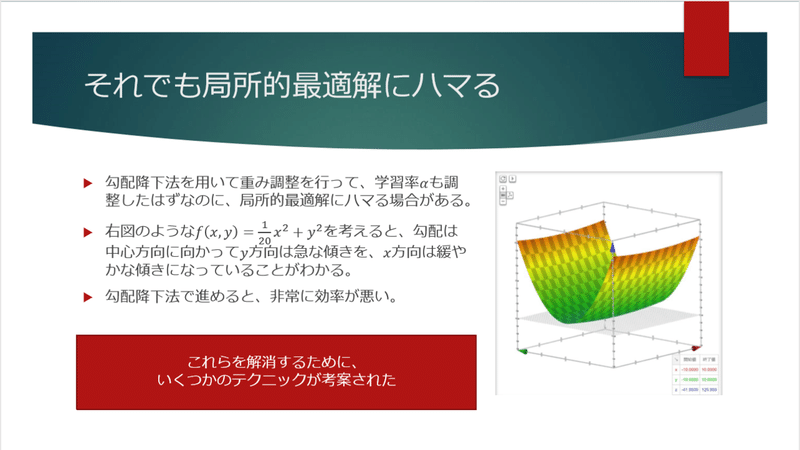
こういうような誤差関数だった場合は、どうしても局所最適解にトラップされる可能性が高くなってしまいます。
それを解消するために、いくつかのテクニックが考案されています。

こういった手法を用いることで、学習率の更新を工夫していきます。そして効率的に学習を進めることができるようになっていくので、より正解を導くことのできる精度の高いディープラーニングが実現可能となっているのです。
ディープラーニングにおける学習まとめ
ここまで見てきたディープラーニングの学習(逆伝播)ですが、簡単にまとめると次のようになるでしょう。

ディープラーニングの応用あれこれ
ディープラーニングの応用について、いろいろなものが出てきていますので、ざっくりですがまとめたものを付しておきます。
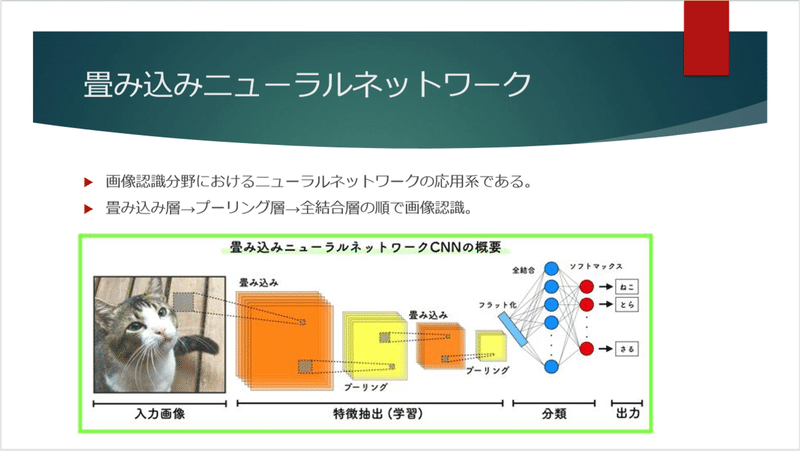
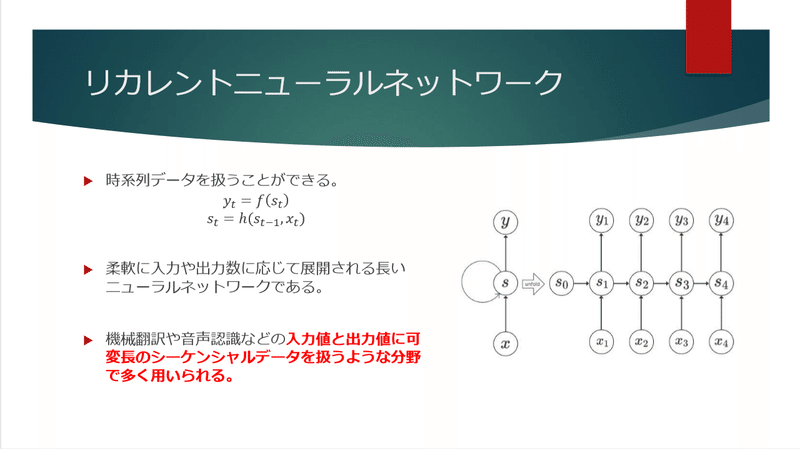
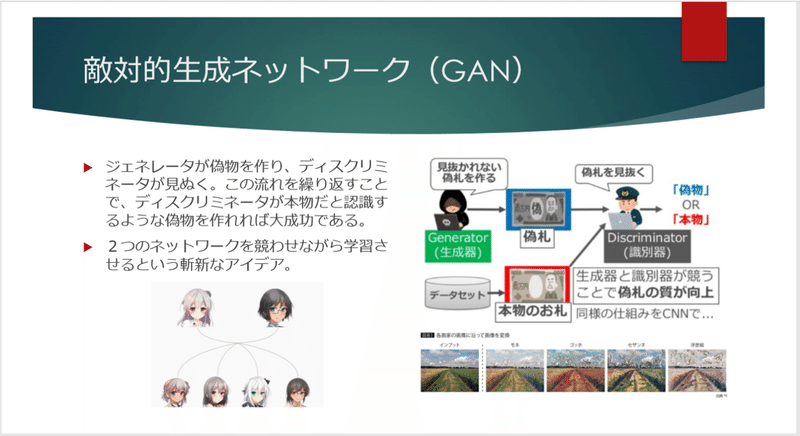

特に「敵対的生成ネットワーク」や「BERT」は、非常に多くの研究がなされ、近年劇的に進化していますので、気になる方は調べてみても面白いでしょう。
さいごに
これで全5回のコラムは終了となります。
なかなかこういった解説を書くことになれていないので、まだまだ説明不足で分かりづらい部分もたくさんあったかと思います。
もし第1回から最後まで読んでいただけた方が1人でもいらっしゃったら、それは大変うれしいことです。
今後も定期的にテーマを見つけたら書いていきたいと思いますので、どうぞよろしくお願いいたします。
ここまで読んでいただき、ありがとうございました。
よろしければサポートをお願いいたします。 記事・コンテンツ作成のモチベーションになります。