#31 画像生成AIを実際にビジネス利用するためには -LoRA/ControlNet-

Kinkakuという画像生成AIのスタートアップに投資をさせていただいた。Akuma.aiという画像生成サービスを行っているので、ぜひ気になるかた登録して利用をしてみていただければ幸い。プレスリリースは下記の通り。
生成AIスタートアップKinkaku、資金調達を完了し、ゲーム・コンテンツ制作のための画像生成クラウド「Akuma.ai」を正式リリース
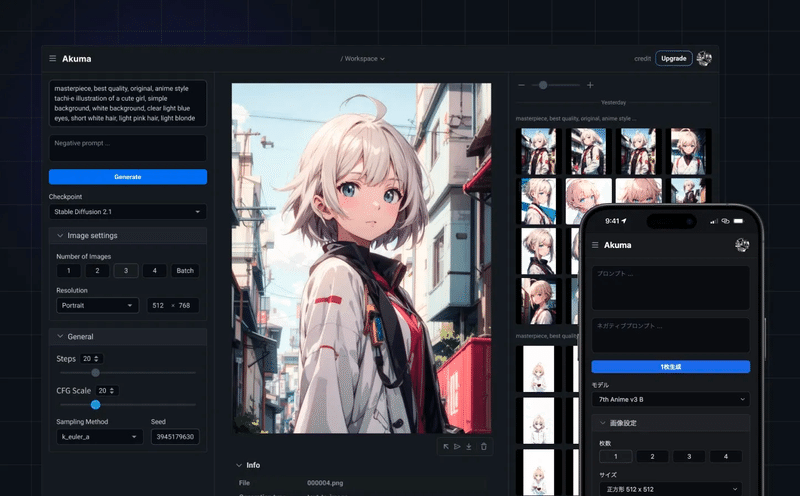
実際にはこの動画を見ていただくか、実際につかってもらうのが一番なのだが、Stable diffusion web UIを実際につかうと環境構築のためにインストールしたり、GPUが高いPCでないとなかなか生成ができなかったりする。そういった環境構築など必要なく利用することができるようになっている。またモデルを学習させることができ、そのモデルをベースに画像生成することができるようになっている。
非常に抽象化すると、実務に耐えうるクオリティの画像生成ができる可能性があるサービスを提供していると認識している。まだまだこれからサービス自体も改善していくが、ぜひ利用していただければ幸い。
-そもそも現状だと画像生成AIはビジネス利用・実利用しずらい?
生成系AIが注目されてから様々なユースケースを皆が探している。書店にいくと”ChatGPTでできる〇〇”といったタイトルの本が多く並んでいるのが現状である。一時期のDAOやWeb3のときに近い流れを感じるし、その当時は自分がビジネスに興味がなかったのでわからないが、iPhoneなどがでてきたときや、インターネットがでたときも同じような現象が起きていたのかもしれない。それぐらい現状はまだ全員がユースケースを探しているタイミングである気がしている。(もしかすると全てのことに使える可能性もあるが)
画像生成の分野に今回は着目を当てるが、いまこれを読んでいる方で、画像生成AIを使って他人の目に見えるものでなにかつくったことはあるだろうか? プロンプトを入れて、画像生成したことがある方はほとんどだと思うが、いわゆるビジネス利用として実需で使った方はどのぐらいいるのだろうか?まだ正直数としては多くはないのではないかと思う。
一番多いのはブログ記事などにおいて画像生成でOGPをつくるといったものはよく利用しているのではないか、自分も唯一今利用しているのはそういった意味での画像生成はよく使っている。
ガラガラポン課題:現状の生成だと理想の画像がでるまでが困難で実運用にはきつい
特にプロンプトの扱いにまだなれてない場合(自分もだが)は生成ごとにおみくじやガチャガチャをひくように毎回違うコンテンツテイストのものが生まれてくるようになる。どんなのがでてくるのがわからないのが面白さではあるものの、ガラガラポンの運用だと一貫性が生まれず実運用はされづらい。
例えばLPの画像利用や、Webページでの商品画像利用になるとデザイナーに依頼する場合、カラーコードに従い、またこれまでの暗黙知・共有知をベースに作成する。それはブランドの思想であったり、CVRがこれまで良かったクリエイティブなどを覚えているからだ。
しかし現状の画像生成AIをそのまま利用するとそのようなものが受け継がれなくなってしまう。なので実運用になかなか乗りづらいのが今の現状ではないだろうか(一方VCとして実務で働いているため、こんな使い方している!というのがあればぜひ連絡してご共有いただければ幸い)
そのため海外のスタートアップを見ると例えばTypefaceやJasperあたりがその課題に挑戦しているように思える。下記画像がTypefaceがトップ画面で出しているが、自分の商品画像を登録すると、ブランドに適した文言や画像を生成してくれる。こういったfine-tuningをしていくことによって、実運用に耐えうる用になるのではないかと思う。
(といっても技術の進歩甚だしいので、数年後この記事を読んで何言ってるんだ?こいつは?となる可能性もある)
画像生成においても上記のような問題を抱えていたことはクリエイターとしてもわかっていたので出てきた技術がLoRAやControlNetというものが登場してきた。
-LoRA/ControlNetなどの技術の登場。しかしまだエンジニア以外は使いづらいのが現状
Stable diffusionはオープンソースでもあるため直近でも様々な技術が開発されている。いわゆるAIにおける追加学習としてのAdaptorの開発が進んでいる。Adaptorとは、事前学習済みのモデルに追加される小さなネットワークやモジュールのことで、事前学習済みのモデルを特定のタスクやデータセットに適応させるために使用される。なので簡単にうとDLCみたいな概念で、Add-onで自分の好みにカスタマイズしやすくなるものというものだ。(かといってエンジニアではないので理解間違ってたらすみません)このような技術によって、前述したガチャガチャのような、プロンプトを何度も繰り返して生成しないと理想の画像に近づけない課題(ガラガラポン問題)を解決しつつある。
LoRA
現状で有名なところでいうとLoRA(Low-Rank Adaptation)というものが今は様々な画像生成サービスにも実装がされ始めている。これは、少なくて数枚から25枚からでも特徴を学習することができ、その追加学習によりその特徴を踏まえた画像生成が可能になるというものだ。
なので例えばなのだけれども、自分の写真が数十枚(25枚ほどと記載が多かった)あればその特徴を踏まえた画像生成ができやすくなってしまうのである(そんな自分の顔など生成したくないが)これまでだと例えば自分の場合だと、プロンプトでは”日本人、男性、30代、髪少し長め、一重・・・・”みたいなことを書いていき、似ている人を生成していく必要があったが、そういったものがショートカットできるようになる(繰り返しだがそんな生成したくないが)
これはガラガラポン問題を解決できうるようになるものである。CivitAIなどに多くのLoRAがダウンロード可能なのでぜひ見てほしいが、一方著作権であり肖像権などの問題はあるので利用は慎重に考えてもらいたい。前述したように、そんな莫大な数の画像がなくとも学習できてしまうので侵害にあたる可能性が多くでてきてしまう。
ただ例えば自社のブランドやキャラクターや商品などを様々な方法で見せるための画像生成などを今後考えると、ビジネス上の実運用も期待できるのではないかと思う。(もちろんその更に学習データを考えると著作権・法律上の問題があるのでだから使えるほど容易なものではないが)
ControlNet

(こちらの記事からの画像引用)
こちらも同様に注目されている方法の1つで、事前に訓練されたモデルに新しい制約を与えて画像生成をより自由に制御する技術。ハンドルネームlllyasviel、チャン・リュミンさんという研究者が発表した方法。
制約条件を与えることでより自分の理想に近い画像生成ができるようになるものであり、例えば棒人形でポーズを先に決めることで、そのポーズをした画像生成がされたり、スケッチからそのスケッチを元に画像生成したりなど、まずプロンプト以外で制約を与えることによって、ガラガラポン問題を解決しようとしている。詳しくは下記記事などわかりやすいのでぜひ
【Stable Diffusion】拡張機能ControlNetの使い方を解説!
ControlNet用のポーズを簡単に作れる「Openpose Editor」の使い方【Stable Diffusion web UI】
このような技術発展が著しく、今後もより数年の間にモデル自体の精度もあがるし、こういった追加学習のような技術も発展していくと思うが、今日においてはまだエンジニアの方以外が実装していくのには少し手間もお金もかかるのが現状である。だからこそこの間を埋めるものとして、Kinkakuに投資を今回させていただいた。
-技術の民主化:Kinkaku(Akuma.ai)に期待すること
よりシード期なのでどうなるかは正直まだ未知数なところは多いが、この画像生成を実利用できる時間軸を短くしていき、社会実装できるような存在になってほしいと思い投資を行った。
現状はコンテンツ企業・ゲーム会社などのクリエイティブ生成と相性が良いのではと考えているため、そのような企業の方々で興味がある方はぜひ問い合わせしていただけると幸い。下記PRリリースに掲載の連絡先からぜひ。
https://prtimes.jp/main/html/rd/p/000000002.000121979.html
まだまだこの分野については自分もキャッチアップを続けないと行けないなと思っているが、そういった最先端のテクノロジーのど真ん中で勝負するより、それを実務に落とし込む存在というのは必要なはずで、そこを担う企業になっていくことを期待している。
読んだ本やおまけは、下記メルマガで配信しているのでぜひご登録いただければ幸いです!
この記事が気に入ったらサポートをしてみませんか?