
APIで取得したOHLCVデータから任意の時間足を作成する

2018/08/10[OHLCVデータ取得関数の実装例の一部を修正2]
以下の2点を修正しましたので本実装例を参考にされている場合、お手数ですが下記の修正をお願い致します。(文末の実装例は修正済み)
①DataFrameのto_datetime関数にてtimestamp(文字列)からdatetimeに変換していますが、タイムゾーンUTC指定が正しく行われていなかったため環境によってズレが発生する問題を修正しました。
修正前)pd.to_datetime(df_ohlcv.index, utc=True)
修正後)df_ohlcv.index = df_ohlcv.index.tz_localize("UTC")
②reverse=False, partial=Trueを指定して取得した場合にデータの並び順が正しくない場合がありましたので修正しました。
(fetch_ohlcv_df関数のresamle後の処理順序を修正)
2018/05/29[OHLCVデータ取得関数の実装例の一部を修正]
読者様より、datetimeからUnix Timeへの変換にて不具合のご指摘いただきましたので修正しました。
[現象]
実行する環境のタイムゾーンがUTCでない場合にUnix Timeがずれてしまい、正しい期間のデータが取得されない
[対応]
datetime⇒Unix Time変換
修正前) int(time.mktime(dt.timetuple()))
修正後) int(dt.timestamp())
本実装例を参考にされている場合、お手数ですが上記の修正をお願い致します。(文末の実装例は修正済み)
BitMEXの公式APIで取得できるOHLCVデータは現在、1m/5m/1h/1dのみとなっていて、botやチャートに利用するには不足しています。
トレードには短期スキャルピングからデイトレード、スイングトレードと様々な時間足でのトレード手法があります。
また、一つのロジックでも長い時間足で大きな流れを確認し、短い時間足でエントリーやイグジットタイミングを計るといったこともあります。
そのような状況において、botロジックを実装するには柔軟に対応した時間足データが必要となります。
本noteではAPIから取得できる基準時間足(1m/5m/1h/1d)を期間毎に集計(マージ)することで、任意の時間足データを作成する方法について解説します。
解説の随所にサンプルコードも示しますので、必要なら実際に動かして理解を深めるのにお役立てください。
また、文末に私が考えたOHLCVデータ取得関数の実装例を示しますので、興味があれば参考にどうぞ。
(本noteのサンプルコードではpandas、jsonを利用していますので動かすにはそれらをインストールする必要があります。)
【BitMEX APIにて基準となるOHLCVデータを取得】
例として5m足のOHLCVデータを1時間前から現在まで取得するコードを以下に示します。
from datetime import datetime
import calendar, requests
# 現在時刻のUTC naiveオブジェクト
now = datetime.utcnow()
# UTC naiveオブジェクト -> Unix time
unixtime = calendar.timegm(now.utctimetuple())
# 60分前のUnixTime
since = unixtime - 60 * 60
# APIリクエスト(1時間前から現在までの5m足OHLCVデータを取得)
param = {"period": 5, "from": since, "to": unixtime}
url = "https://www.bitmex.com/api/udf/history?symbol=XBTUSD&resolution={period}&from={from}&to={to}".format(**param)
res = requests.get(url)
data = res.json()
# レスポンスのjsonデータからOHLCVのDataFrameを作成
df = pd.DataFrame({
"timestamp": data["t"],
"open": data["o"],
"high": data["h"],
"low": data["l"],
"close": data["c"],
"volume": data["v"],
}, columns = ["timestamp","open","high","low","close","volume"])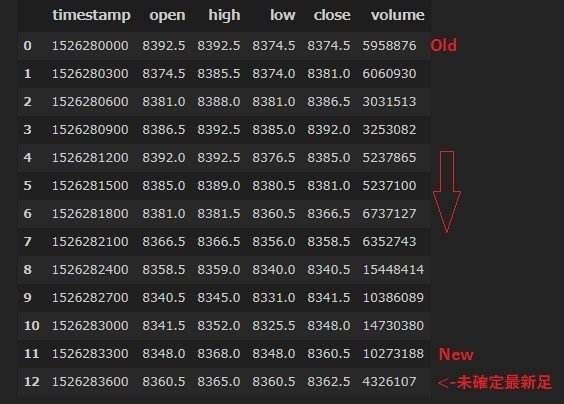
UDF History APIリクエストは
resolusion:「時間足(分) 1m/5m/1h/1d」(1 or 5 or 60 or 1440)
from :「取得開始時刻(UnixTime)」
to :「取得終了時刻(UnixTime)」
を指定することで該当期間のOHLCVデータを取得することができます。
上記例ではresolusion(時間足)を5(分)、fromを1時間前のUnixTime、toを現在時刻のUnixTimeとして1時間前から現在までの5m足OHLCVデータを取得しています。
[参考] UnixTimeとは
「協定世界時 (UTC) の時刻に基づき、1970年1月1日午前0時0分0秒(UNIXエポック)からの経過秒数」(wikipediaより)
【5m足から15m足のOHLCVを作成】
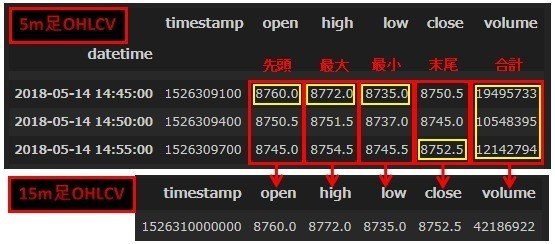
15m足は5m足データを3期間毎に集計することで作成できます。

上図ロウソクチャートからイメージできるように5m足を3期間で15m足1期間となります。
これをOHLCVデータで確認してみます。

上図から分かるようにAPIリクエストで取得した5m足のOHLCVデータを3期間毎に纏めることで15m足のOHLCVが作成できます。
5m足の3期間をまとめる方法は以下になります。
OHLCVデータはその期間における以下の値を示します。
open :期間開始時の価格(first)
high :期間内の最高値(max)
low :期間内の最安値(min)
close :期間終了時の価格(last)
volume:期間内の出来高合計(sum)
5m足の3期間から各項目別に上記の集計を行うことで15m足を作成します。
【pandas DataFrameによるリサンプリング】
pandas DataFrameにはリサンプリング機能があり、任意の間隔に集計単位を変えることができます。
[参考] DataFrameの時系列データのリサンプリング
この機能を利用して5m⇒15mの作成を行います。
まず、APIより取得した5mのOHLCVデータから作成したDataFrameに集計keyとなるdatetime型インデックスを設定します。
# "datetime"列を"timestamp"列のUnixTimeより作成
df["datetime"] = pd.to_datetime(df["timestamp"], unit="s")
# "datetime"列をDataFrameのインデックスに設定
df = df.set_index("datetime")
pd.to_datetime(df.index, utc=True)そして、設定したインデックスのdatetimeを基に15m単位("15T")でにリサンプリングを行います。
# 15m単位にリサンプリング
df = df.resample("15T").agg({
"timestamp": "first", # 先頭
"open": "first", # 先頭
"high": "max", # 最大
"low": "min", # 最小
"close": "last", # 末尾
"volume": "sum", # 合計
})先ほど図で解説した集計がDataFrameのリサンプリングを使用すると、これだけでできてしまいます。
例えば、30m足のOHLCVデータであれば、上記の"15T"を"30T"にすることで対応できます。
4h足を作成したいなら、APIリクエストで1h足のOHLCVデータを取得し、同様の方法で"4H"でリサンプリングすれば作成できます。
ここまでのコードを以下にまとめておきます。
from datetime import datetime
import calendar, requests
# 現在時刻のUTC naiveオブジェクト
now = datetime.utcnow()
# UTC naiveオブジェクト -> Unix time
unixtime = calendar.timegm(now.utctimetuple())
# 60分前のUnixTime
since = unixtime - 60 * 60
# APIリクエスト(1時間前から現在までの5m足OHLCVデータを取得)
param = {"period": 5, "from": since, "to": unixtime}
url = "https://www.bitmex.com/api/udf/history?symbol=XBTUSD&resolution={period}&from={from}&to={to}".format(**param)
res = requests.get(url)
data = res.json()
# レスポンスのjsonデータからOHLCVのDataFrameを作成
df = pd.DataFrame({
"timestamp": data["t"],
"open": data["o"],
"high": data["h"],
"low": data["l"],
"close": data["c"],
"volume": data["v"],
}, columns = ["timestamp","open","high","low","close","volume"])
# "datetime"列を"timestamp"列のUnixTimeより作成
df["datetime"] = pd.to_datetime(df["timestamp"], unit="s")
# "datetime"列をDataFrameのインデックスに設定
df = df.set_index("datetime")
pd.to_datetime(df.index, utc=True)
# 15m単位にリサンプリング
df = df.resample("15T").agg({
"timestamp": "first", # 先頭
"open": "first", # 先頭
"high": "max", # 最大
"low": "min", # 最小
"close": "last", # 末尾
"volume": "sum", # 合計
})
【取得したOHLCVデータの実用性を考慮】
上記にてBitMEXの基準時間足(1m/5m/1h/1d)から任意の時間足OHLCVデータを作成することができるようになりました。
ここで、取得したOHLCVデータを利用する場合を考慮してみます。
例えばbotであればOHLCVデータを取得し、様々なインジケータやオシレータを算出する計算に使用することになるでしょう。
インジケータ等はものによっては前期間で計算した結果を使って値を算出するものもよくあります。(例えばEMAなど)
そうなると、計算するヒストリカルデータ数が少ないと正しい結果(に収束した値)を算出できない可能性があります。
上記のAPIデータ取得では取得開始時刻と終了時刻を指定してデータを取得しています。
これは時間足によって取得されるヒストリカルデータ数が変わってきます。
例えば5mを1時間分なら12期間ですが、15mなら4期間になります。
実際にはもっと長い期間を指定してデータ取得を行うとは思いますが、長期の時間足になるほど取得できるヒストリカルデータ数は減少します。
以下の図は取得期間を3日間に指定した場合の各時間足毎の取得されるヒストリカルデータ件数になります。
5mでは864件取得できても1hは72件にしかなりません。
(Google Spreadsheetで複数時間足OHLCVデータを一括取得するツールより)

botにおいて長期の時間足と短期の時間足を組み合わせてエントリーやイグジットの判定を行う場合、長期の時間足でもある程度の数量のヒストリカルデータが必要になります。
上記のような時刻指定では取得する時間足によってどのくらいの期間が必要でその時刻がいつになるかを考慮しなければなりません。
そこで、OHLCVデータ取得において取得期間の時刻指定ではなく、OHLCVデータ件数を指定して取得できるようにすることで使い勝手が向上すると考えます。
指定した時間足OHLCVデータを現在から何件取得するかという指定を可能にしてみます。
APIリクエストは取得する時間足と期間の開始時刻、終了時刻で指定する必要があります。
現在の最新足から何期間という指定を行うので終了時刻は現在時刻となります。
それに対して開始時刻は「現在時刻 - 1期間あたりの秒数 × 期間数」にて逆算することで、求める期間数のOHLCVデータが取得されます。
resolusion:「時間足(分) 1m/5m/1h/1d」(1 or 5 or 60 or 1440)
from :「現在時刻UnixTime - 時間足(分) × 60(秒) × 取得期間数」
to :「現在時刻UnixTime」
BitMEX APIで提供されている基準時間足(1m/5m/1h/1d)であれば上記指定で問題ありませんが、リサンプリングで算出する任意の時間足は基準時間足を集計するため、取得したい期間数でAPIリクエストすると集計した分だけ結果が減ってしまいます。
そのため、任意の時間足を取得する際には使用する基準時間足ベースで必要期間を計算しなければなりません。
15mであれば基準時間足5mを3期間集計するため、取得したい期間数の3倍を指定します。
例えば、15m足100期間分は5m足を100 × 3期間にて取得します。
from :
「現在時刻UnixTime - 基準時間足(分) × 集計期間数 × 60(秒) × 取得期間数」
上記の取得にて考慮しなければならない点が、
① タイミングによっては最も古いOHLCVデータが正しく集計できない
② 1回のAPIリクエストで取得できる上限件数
があります。
① タイミングによっては最も古いOHLCVデータが正しく集計できない
任意の時間足を集計して取得する場合にタイミングによっては最も古いOHLCVデータが正しく集計できない場合があります。

15m足であれば5m足を3期間単位に集計していきますが、取得開始タイミングによって最後の時間足を集計する5m足が足りない状況になります。
この状況を回避するため、取得したい件数 + α 分の基準時間足を取得し、集計後に件数以上の不要なデータを除去する方法をとります。
from :
「現在時刻UnixTime -
基準時間足(分) × 集計期間数 × 60(秒) × (取得期間数 + α)」
② 1回のAPIリクエストで取得できる上限件数
UDF History APIリクエストは1回のリクエストで最大10080件まで取得することができるようです。(最大:1m × 60分 × 24時間 × 7日間 = 10080(分))
取得件数が上記の上限を超える場合、APIリクエストを分割してOHLCVデータの取得を行う必要があります。
通常のbot稼働の中では上限を超えるような取得はなかなか行わないかもしれませんが、短い時間足(1m)を長い期間分取得したり、バックテストなどで一度に大量のOHLCVデータが必要な場合などに考慮する必要がでてきます。
そのため、基準時間足の取得件数が1万件を超えた場合は1万件毎にAPIリクエストを分割して複数回の呼び出し結果からOHLCVデータを結合して取得する方法をとります。
例えば、取得件数が25000件の場合
リクエスト1:0~9999件目までのOHLCVデータ
リクエスト2:10000~19999件目までのOHLCVデータ
リクエスト3:20000~24999件目までのOHLCVデータ
求めるOHLCVデータ = リクエスト1 + リクエスト2 + リクエスト3
ここまでに解説した現在からの件数ベースでのOHLCVデータ取得のサンプルコードを以下に示します。
from datetime import datetime
import calendar, requests
"""
5m足を基準として15m足のOHLCVデータを現在から5000件分取得する
"""
# 取得したい15m期間数
count_15m = 5000
# APIリクエストする5m期間数(+αを1とする)
# (取得期間数 + α) × 集計期間数
count_5m = (count_15m + 1) * 3 # 5mを15003期間取得
#------------------------------------------------------------------
# 取得開始/終了時刻のUnixTimeを計算
#------------------------------------------------------------------
# 現在時刻のUTC datetime
now = datetime.utcnow()
# datetime -> UnixTime
unixtime = calendar.timegm(now.utctimetuple())
# 取得終了時刻(from)
# 現在時刻UnixTime - 5m期間数 × 5(分) × 60(秒)
from_time = unixtime - count_5m * 5 * 60
# 取得終了時刻(to)
to_time = unixtime
#------------------------------------------------------------------
# リクエスト件数が1万件を超えているか判定してAPIリクエスト
#------------------------------------------------------------------
if count_5m < 10000:
# リクエスト件数が1万件未満のため、1リクエストでOHLCVデータ取得
param = {"period": 5, "from": from_time, "to": to_time}
url = "https://www.bitmex.com/api/udf/history?symbol=XBTUSD&resolution={period}&from={from}&to={to}".format(**param)
res = requests.get(url)
data = res.json()
df = pd.DataFrame({
"timestamp": data["t"],
"open": data["o"],
"high": data["h"],
"low": data["l"],
"close": data["c"],
"volume": data["v"],
}, columns = ["timestamp","open","high","low","close","volume"])
else:
# リクエスト件数が1万件以上のため、分割してOHLCVデータ取得
ohlcv_list = []
# 分割リクエスト開始(start)/終了時刻(end)
start = from_time
end = from_time + 5 * 60 * 10000
# 分割リクエスト開始時刻が現在時刻より過去の間はループ
while start <= to_time:
param = {"period": 5, "from": start, "to": end}
url = "https://www.bitmex.com/api/udf/history?symbol=XBTUSD&resolution={period}&from={from}&to={to}".format(**param)
res = requests.get(url)
data = res.json()
# リクエストで取得したOHLCVデータをリストで結合
ohlcv_list += [list(ohlcv) for ohlcv in zip(data["t"], data["o"], data["h"], data["l"], data["c"], data["v"])]
# 次の分割期間の開始/終了時刻を設定
start = end + 5 * 60
end = start + 5 * 60 * 10000
# 終了時刻が現在時刻より未来になったら、現在時刻にする
if end > to_time:
end = to_time
# 分割リクエストが完了したら、DataFrame作成
df = pd.DataFrame(ohlcv_list,
columns=["timestamp", "open", "high", "low", "close", "volume"])
#------------------------------------------------------------------
# 5m OHLCV DataFrameをリサンプリングして15m OHLCVを作成
#------------------------------------------------------------------
# "datetime"列を"timestamp"列のUnixTimeより作成
df["datetime"] = pd.to_datetime(df["timestamp"], unit="s")
# "datetime"列をDataFrameのインデックスに設定
df = df.set_index("datetime")
pd.to_datetime(df.index, utc=True)
# 15m単位にリサンプリング
df = df.resample("15T").agg({
"timestamp": "first", # 先頭
"open": "first", # 先頭
"high": "max", # 最大
"low": "min", # 最小
"close": "last", # 末尾
"volume": "sum", # 合計
})
# マージした結果、余分に取得している場合、古い足から除去
if len(df) > count_15m:
df = df.iloc[len(df)-count_15m:]
【さらに利便性を向上させて関数化する】
ここまでは具体的なデータ取得を例にして解説やサンプルコードを示してきましたが、実際にコード内で使用する場合には様々な時間足や件数、その他条件でOHLCVデータを取得できる必要があります。
そのため、これまでに解説したOHLCV取得の実装を関数化し、その引数に応じたデータ取得ができるようにします。
関数の引数では指定したい条件を含めていくことになります。
period :取得する時間足
count :現在から取得するOHLCVデータ件数
上記はこれまでに解説してきた指定条件です。
この他に指定できると便利なものとして
partial :未確定の最新時間足を含めるか否か
(確定足しか必要ない場合に除外できる)
reverse:データの並び順を反転するか否か
(基本は古→新だけど、新→古順にできる)
などがあります。
また、OHLCVデータにはtimestampがありますがこれはデータ取得するリクエストや関数によって表記方法やデータ型が様々なパターンとなっています。
そのため、それらの形式に対応できるよういくつかのパターンから選択できるようにしておくと良いです。
これらを加味して私が考えた関数は以下です。

関数を2パターン用意しているのはOHLCVデータをList(2次元) / DataFrameどちらで取得するか選択できるようにしているためです。
以下にサンプルコードを示します。
複雑そうに見える部分もあるかもしれませんが、骨子はこれまでに解説してきた内容になります。
また、サンプルコードではいくつかの補助関数("__"から始まる関数名)を使っていますが、実際にOHLCVデータ取得を行うために呼び出す関数は上記のみになります。
# coding: utf-8
from datetime import datetime, timedelta
import time, calendar, pytz, requests
import pandas as pd
ALLOWED_PERIOD = {
"1m": ["1m", 1, 1], "3m": ["1m", 3, 3],
"5m": ["5m", 1, 5], "15m": ["5m", 3, 15], "30m": ["5m", 6, 30],
"1h": ["1h", 1, 60], "2h": ["1h", 2, 120],
"3h": ["1h", 3, 180], "4h": ["1h", 4, 240],
"6h": ["1h", 6, 360], "12h": ["1h", 12, 720],
"1d": ["1d", 1, 1440],
# not support yet '3d', '1w', '2w', '1m'
}
#---------------------------------------------------------------------
# メイン処理
#---------------------------------------------------------------------
def main():
# DataFrameにてOHLCV取得
df_ohlcv = fetch_ohlcv_df(period="1m", count=10, reverse=False, partial=True, tstype="UTMS")
print(df_ohlcv)
# ListにてOHLCV取得
lst_ohlcv = fetch_ohlcv_lst(period="1m", count=10, reverse=False, partial=True, tstype="UTMS")
print(lst_ohlcv)
#---------------------------------------------------------------------
# 指定された時間足のOHLCVデータをBitMEX REST APIより取得
#---------------------------------------------------------------------
# [@param]
# period ="1m" 時間足(1m, 3m, 5m, 15m, 30m, 1h, 2h, 3h, 4h, 6h, 12h, 1d)
# symbol ="XBTUSD" 通貨ペア
# count =1000 取得期間 ※
# reverse =True 並び順(True:新->古, False:古->新)
# partial =False 最新未確定足を取得するか(True:含む, False:含まない)
# tstype ="UTMS" 時刻形式(以下の5パターン)
# "UTMS":UnixTime(ミリ秒), "UTS":UnixTime(秒), "DT":datetime,
# "STMS":日付文字列(%Y-%m-%dT%H:%M:%S.%fZ), "STS":日付文字列(%Y-%m-%dT%H:%M:%S)
# [return]
# DataFrame : [[timestamp, open, high, low, close, volume], ・・・]
# List : [[timestamp, open, high, low, close, volume], ・・・]
# ※戻り値データ型 (List or DataFrame) によって取得関数を2パターンに分けてある
#---------------------------------------------------------------------
# ※ 1m, 5m, 1h, 1dを基準にmergeしているため、それ以外を取得する場合は件数に注意
# (3m : 1m * 3期間より、3mを10期間取得するなら、APIでは 10 * 3 = 30件になる)
# APIは1回でMAX10000件までの取得としている
# 30mや4h、6h、12hなどを取得する場合、件数を大きくするとAPI制限にかかる可能性がある
#---------------------------------------------------------------------
# [usage] lst_ohlcv = fetch_ohlcv_lst(period="15m", count=1000, tstype="DT")
# df_ohlcv = fetch_ohlcv_df(period="5m", count=1000, partial=True)
#---------------------------------------------------------------------
# ListでOHLCVを取得
def fetch_ohlcv_lst(period="1m", symbol="XBTUSD", count=1000, reverse=True, partial=False, tstype="UTMS"):
df = fetch_ohlcv_df(period, symbol, count, reverse, partial, tstype)
if df is None:
return None
return [[int(x[0]) if tstype=="UTS" or tstype=="UTMS" else x[0], x[1], x[2], x[3], x[4], int(x[5])] for x in df.values.tolist()]
# DataFrameでOHLCVを取得
def fetch_ohlcv_df(period="1m", symbol="XBTUSD", count=1000, reverse=True, partial=False, tstype="UTMS"):
if period not in ALLOWED_PERIOD:
return None
period_params = ALLOWED_PERIOD[period]
need_count = (count + 1) * period_params[1] # マージ状況により、不足が発生する可能性があるため、多めに取得
# REST APIリクエストでOHLCVデータ取得
df_ohlcv = __get_ohlcv_paged(symbol=symbol, period=period_params[0], count=need_count)
# DataFrame化して指定時間にリサンプリング
if period_params[1] > 1:
minutes = ALLOWED_PERIOD[period][2]
offset = str(minutes) + "T"
if 60 <= minutes < 1440:
offset = str(minutes / 60) + "H"
elif 1440 <= minutes:
offset = str(minutes / 1440) + "D"
df_ohlcv = df_ohlcv.resample(offset).agg({
"timestamp": "first",
"open": "first",
"high": "max",
"low": "min",
"close": "last",
"volume": "sum",
})
# 未確定の最新足を除去
if partial == False:
df_ohlcv = df_ohlcv.iloc[:-1]
# マージした結果、余分に取得している場合、古い足から除去
if len(df_ohlcv) > count:
df_ohlcv = df_ohlcv.iloc[len(df_ohlcv)-count:]
# index解除
df_ohlcv.reset_index(inplace=True)
# timestampを期間終わり時刻にするため、datetimeをシフト
df_ohlcv["datetime"] += timedelta(minutes=ALLOWED_PERIOD[period][2])
# timestamp変換
__convert_timestamp(df_ohlcv, tstype)
# datetime列を削除
df_ohlcv.drop("datetime", axis=1, inplace=True)
# 並び順を反転
if reverse == True:
df_ohlcv = df_ohlcv.iloc[::-1]
# indexリセット
df_ohlcv.reset_index(inplace=True, drop=True)
return df_ohlcv
# private
def __convert_timestamp(df_ohlcv, timestamp="UTMS"):
if timestamp == "UTS":
df_ohlcv["timestamp"] = pd.Series([int(dt.timestamp()) for dt in df_ohlcv["datetime"]])
elif timestamp == "UTMS":
df_ohlcv["timestamp"] = pd.Series([int(dt.timestamp()) * 1000 for dt in df_ohlcv["datetime"]])
elif timestamp == "DT":
df_ohlcv["timestamp"] = df_ohlcv["datetime"]
elif timestamp == "STS":
df_ohlcv["timestamp"] = pd.Series([dt.strftime("%Y-%m-%dT%H:%M:%S") for dt in df_ohlcv["datetime"]])
elif timestamp == "STMS":
df_ohlcv["timestamp"] = pd.Series([dt.strftime("%Y-%m-%dT%H:%M:%S.%fZ") for dt in df_ohlcv["datetime"]])
else:
df_ohlcv["timestamp"] = df_ohlcv["datetime"]
def __get_ohlcv_paged(symbol="XBTUSD", period="1m", count=1000):
ohlcv_list = []
utc_now = datetime.now(pytz.utc)
to_time = int(utc_now.timestamp())
#to_time = int(time.mktime(utc_now.timetuple()))
from_time = to_time - ALLOWED_PERIOD[period][2] * 60 * count
start = from_time
end = to_time
if count > 10000:
end = from_time + ALLOWED_PERIOD[period][2] * 60 * 10000
while start <= to_time:
ohlcv_list += __fetch_ohlcv_list(symbol=symbol, period=period, start=start, end=end)
start = end + ALLOWED_PERIOD[period][2] * 60
end = start + ALLOWED_PERIOD[period][2] * 60 * 10000
if end > to_time:
end = to_time
df_ohlcv = pd.DataFrame(ohlcv_list,
columns=["timestamp", "open", "high", "low", "close", "volume"])
df_ohlcv["datetime"] = pd.to_datetime(df_ohlcv["timestamp"], unit="s")
df_ohlcv = df_ohlcv.set_index("datetime")
df_ohlcv.index = df_ohlcv.index.tz_localize("UTC")
return df_ohlcv
def __fetch_ohlcv_list(symbol="XBTUSD", period="1m", start=0, end=0):
param = {"period": ALLOWED_PERIOD[period][2], "from": start, "to": end}
url = "https://www.bitmex.com/api/udf/history?symbol=XBTUSD&resolution={period}&from={from}&to={to}".format(**param)
res = requests.get(url)
data = res.json()
return [list(ohlcv) for ohlcv in zip(data["t"], data["o"], data["h"], data["l"], data["c"], data["v"])]
if __name__ == "__main__":
main()
このサンプルコードは一例になります。
それぞれで用途や使い勝手は様々だと思いますので、本noteがコーディングの一助になれば幸いです。
この記事が気に入ったらサポートをしてみませんか?