
【文系が理解するAI】ディープラーニング(1) 〜ただの機械学習とディープラーニングの違い〜

ディープラーニングではないただの機械学習と、画期的とされるディープラーニングの違いについて記載します。
機械学習(教師あり)の用途の代表的なものに、分類と回帰があります。
ここでは、ただの機械学習(ディープラーニングではないという意味)と、ディープラーニングの違いを、回帰を用いて説明したいと思います。
回帰とは、ひらたく言えば"予測"のことで、一例を挙げると、"ある人物の体重を、体重以外のデータから予測する"といった具合に、未知のデータを予測することに活用します。
ちなみに、予測するとは、"精度の高い予測ができる関数(計算式)を導く"ことを指します。さらにひらたくいうと、"よく当たるいい感じの関数(計算式)を探す"ということです。
「探す」と表現をしているのは、例として体重を予測する関数(計算式)を求めたい場合、当然ながら予測の精度が100%完全な式など存在せず、まあ割とうまく当てはまっている関数(計算式)"を実際のデータを用いて探っていく必要があるためです。
先に"両者の違い"の答えを言うと、ディープラーニングではないただの機械学習は、この関数に用いる変数(一般的にx,y,zとおくようなもの)を私たちが明確に定義する必要がありますが、ディープラーニングでは関数に用いる変数は"学習"という工程により勝手に定めてくれます。
この回帰にも、ディープラーニングによるものと、ディープラーニングではないただの機械学習によるものとがあります。
一般的な回帰分析(ディープラーニングではない機械学習の例)
まず、ただの機械学習に当てはまる一般的な回帰分析を例にします。
この回帰分析は機械学習の分類(教師あり学習,教師なし学習,強化学習)では、正解となるデータセットありきで分析を行うので、教師あり学習に分類されると言えます。
一例として、たとえば身長から体重を予測する関数を求めたい場合、まずは体重をY、身長をXと置きます。
一般的に予測したい目的の変数であるY(この場合は体重)は目的変数と言い、予測に用いたい変数X(この場合は身長)は説明変数と言います。
次に、Y = a X + bという一般的な一次式を置き、用意した体重(Y)と身長(X)の統計データから、そのデータによく当てはまる(相関関係を説明できる)aとbの値を求めることにより、体重(Y)を予測する式を求めるのが回帰分析です。
この場合、Yを説明する変数がXのみなので単回帰分析と言いますが、もし本人の身長(X)以外にも、父親の身長(仮にZとする)など他の変数を予測の材料(説明変数)として用いる場合など、複数の説明変数による回帰分析を重回帰分析と言います。

この図のように、データをうまく説明できる直線の傾き(a)と切片(b)を求めることにより、直線の式(aとbに具体的な値が入ったもの)を求めるわけです。
aとbの値の求め方は、一般的に最小二乗法という手法を用います。
最小二乗法とは、各データポイントでの、予測データ(Y = aX + bにおけるX,Y)と実際のデータ(上記図の緑の点)との間の誤差の二乗の和を最小にするようなパラメータ(今回は傾きaと切片b)を求める手法です。
誤差を二乗する理由は、データポイントごとに誤差が+の場合もあれば-の場合もあり、単なる誤差の和だと+-が相殺されてしまい、適切なパラメーター(今回はaとb)が求まらないためです。(二乗することで誤差は必ず+の値になります)
誤差を最小化するパラメーター(a,b)を求めると、直線の式が一つに定まり、実際のデータを説明するための関数が完成するというわけです。
この例のように、ディープラーニングではない機械学習の場合、予測に用いたい変数(今回は身長、あるいは父親の身長)を私たちが明確に指定する必要があります。
よって、分析者が不適切な変数を用いてしまったり、余計な変数を加えてしまう可能性もあります。例えば、体重を予測の関数に用いる変数に"視力"を選んだ場合、"良い関数"にならないことはイメージがつくかと思います。
ディープラーニングの場合
一方、ディープラーニングでは、前述のように、予測に用いる変数の選択や、それらの変数を組み合わせる方法は"学習"という工程により自動的に決定します。つまり、与えられたデータからパターンを見つけ出し、それを基に目標を適切に予測する関数を生成することができます。
例えば、先ほどのように体重を予測する場合でも、ディープラーニングでは体重をうまく予測できそうなデータ(本人の身長や親の身長など)を指定しなくとも、年齢、性別、活動量、食事内容、遺伝的な要素など、あらゆるデータを"学習"と呼ばれる工程を経ることのできる量さえ与えれば、それらを自動的に考慮して最適な関数を生成します。どのデータをどれだけ重要視するかを学習により決めてくれるのです。
ディープラーニングの関数の例は複雑なので、図として表されることが多いですが、以下は計算を表す図の例です。

左のx1、x2、x3から関数に対してのデータ入力が始まり、掛け算と足し算を何度も行い、最終の的に右側の出力を行う複雑な関数です。
x1、x2、x3、y1、y2などが変数に該当しますが、x1は"年齢"、x2は"活動量"など対応関係は明確にする必要はあるものの、どの変数をどれだけ重要視するかは与えられたデータから学習という工程により導き、最終的にうまく予測できる関数を導いていきます。
この図は、w1-11,w1-12など"w"という変数が登場していますが、これはweight(重み)と呼ばれ、どの変数をどれだけ重要視するかを決めるパラメーターです。イメージとしては、体重を予測する関数を作るのに ”本人の身長は重要視するので重みは大きいが、父親の身長は本人の身長ほど重要視しない(つまり本人の身長の方が重みが大きい)”といった使い方です。
さらにディープラーニングでは、先ほどの回帰分析の例のように、単純な直線ではうまく予測できない、非線形で複雑な予測の関数の表現が得意です。
(※ディープラーニングでなくとも非線形で複雑な予測を行う関数はつくれますが、ディープラーニングはよりそれが得意です)
どの変数をどれだけ重要視するかを学習という工程により調整してくれるのがディープラーニングなので、イメージとしては以下のような直線でもなくシンプルな二次関数でもない複雑な関数を表現することが可能になります。
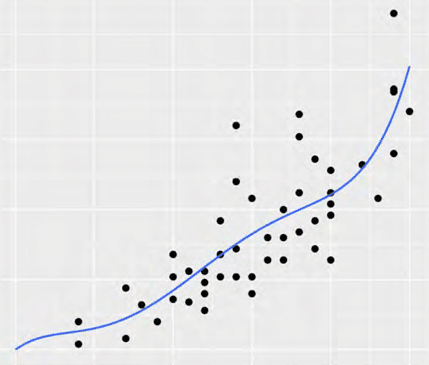
このように、ディープラーニングは回帰の例で言うと目標をうまく予測できるようになるために、より意味のありそうなデータを自動的に選択・重みの調整をして、予測する関数を作っていくわけですが、これは人間が日々の生活の中であらゆる情報をインプットし、答えを出したいものへの答えの精度を向上させていく過程によく似ています。
ディープラーニングは何がメリットなのか?
ではディープラーニングがこの「学習により勝手に良い感じの関数を作れる」ことがなぜ良いのかというと以下のメリットがあるからです。
1. 何によりもまず複雑な関係性を扱えるので予測の精度が高くなる
ここでいう関係性とは予測の関数のことで、先ほどの例で言うと直線で表した回帰分析の式は単純ですが、単純ゆえ実際のデータとの当てはまり度合いには限界があります。
しかし、ディープラーニングでは単なる直線ではない複雑な非線形の関数を作れるため、複雑なデータの予測も精度高く行うことができます。(※「予測」だけでなく「分類」の場合でも同じです)
2. 人間が変数を選ぶ手間を省ける
人間がデータ分析を行う際、適切な変数を選ぶのは非常に難しいタスクであり、それが分析結果の質に大きな影響を及ぼします。ディープラーニングは、自動的に良い変数を選択・調整する能力を持っているため、人間がそれらの作業を行う必要がなくなります。
一方、ディープラーニングは変数を人間が明確に指定しないがゆえ、「ブラックボックス」のような性質も持っています。
なぜある結果が出力されたのかを解釈することが困難な場合がしばしばあります。この点は、今後のAI技術の発展における重要な課題とされています。
(例えば、ある事件の犯人をディープラーニングを用いて予測した際、特定の人物が犯人であると判断した理由がわからないと行ったケースがありうる)
以上、一般的な機械学習とディープラーニングの違いについて説明しました。
次回以降は、ディープラーニングがなぜ自動的に変数を定めたり、精度の高い答えを導くことのできる複雑な関数を作れるのか、その仕組みについていくつかに分けて説明したいと思います。
この記事が気に入ったらサポートをしてみませんか?