
AIを学ぶために、何から始めれば良いか?

はじめに
皆さん、こんにちは。
今回は、AIを学ぶために、何から始めれば良いか?について書いてみたいと思います。
周りの人から、よくこの質問をされるのですが、あまりスパッと答えられた試しが無く…。
この機会に、改めて考えてみようと思い立った次第です。
AIとは?
昨今のAIブームにより、AI導入に前向きな企業が増えてきている昨今。
転じて、AIを学びたい人も増えてきていると感じています。
私の周りにも、AIのキャッチアップに臨む人が多いです。
そんなAIですが、皆さん実態を捉えているでしょうか?
「AIは何か?」という質問をされて、ポンと答えられる人は、割と少ないんじゃないかと思います。
「AIは何か?」については、別の記事にまとめさせてもらっていますので、よければ参照下さい。
記事の内容をかい摘まむと、AIは人間の代替をしてくれる技術、ということの説明になります。
要するに、自動化です。
これまで人間が行ってきた営みを、機械に実施させることで、人間はその労働から開放されることになるのです。
その意味で、AIを始めとする技術実現が第4次産業革命(英語だと、Industry 4.0)と呼ばれています。
ビジネスにおいては、非常にインパクトの強い話題となります。
AIは、機械学習によって生まれる
「AIとは自動化である」という話ですが、これは、AIの適用目的をベースとしたAIの説明になります。
では、AIの構成についてはどうでしょうか?
どうやって、AIは作られているのでしょうか?
結論から言うと、AIは、AI自らが学習することによって作られます。
AIの学習とは、大量のデータの中から、特定の現象が発生する法則性を抽出することを指します。
まるで人間が経験に学ぶかのように、AIは過去の実績から法則性を抽出するのです。
尚、このAI自らが行う学習のことを、機械学習と言います。
気象予測などで考えると分かりやすいかもしれません。
例えば、「低気圧が来ると、雨が降ることが多い」というような法則性です。
AIは、それをデータから見出します。
ただし、科学的根拠や第六感などを頼りに法則性を見出す訳ではなく、パターンとしての法則性を探索します。
現象の意味理解ではなく、パターンの探索です。
そして、一度法則性が見出だせれば、ある種の意思決定は自動化できるようになります。
「低気圧が来ているから、傘を持っていこう」というような形でです。
尚、かつての第3次産業革命の頃、即ち、いわゆるIT革命の頃においては、まだ機械学習は実施されていなかった為、自動化のための法則性は人間によって設計されてきました。
過去のデータ(実績)や経験を基に、人間が頭を使って、自動化の仕組みを設計してきたのです。
ATMにしろ、流通システムにしろ、人事システムにしろです。
つまり、自動化のための法則性を、システム構築するまでの流れは以下です。
(1) 人間がデータや経験を基に、自動化のための法則性を設計する
(2) 設計した法則性を、システムに構築することで自動化を実現する
以上。
一度システムが構築されれば、システムが自動化を実現してくれます。
しかし、このシステムによる自動化については、その法則性を見出したのが人間である為、AIとは呼ばれていません。
ロボットとか、ルールベースのシステムとか、人間の設計通りに動く機械とか、という捉えられ方です。
そして、第4次産業革命においては、自動化のための法則性を、システム搭載するまでの流れは以下となります。
(1) 人間が機械学習を行える形に、データを整理する
(2) 整理されたデータから、機械学習によって、法則性を自動抽出する(3) 抽出された法則性を、システムに搭載することで自動化を実現する
以上。
これまで人間が設計・構築してきた法則性が、機械学習によって自動抽出されています。
それは、機械が人間の知的行動を、つまり、考える行為を代替している形です。
尚、誤解してはいけないのは、あくまで法則性抽出の部分だけが自動化されている点です。
システム構築全体が自動化されている訳ではありません。
あくまで、システム全体の構築を人間が行った上で、意思決定のために必要となる法則性の抽出部分だけについては、機械が代替している形です。
まだ、現状のAIがなせる自動化の範疇は、その範囲なのです。
この仕組みによる恩恵は2つです。
1つは、法則性の設計・構築が自動化されることによる労働力の軽減です。
もう1つは、過去のデータ(実績)さえあれば、法則性の抽出に臨める点です。
特に、後者の恩恵は、AIが最も注目されている理由とも言えます。
と言いますのも、これまでのシステムにおいては、設計しようにも上手く成し得なかった法則性の壁がありました。
例えば、人間の視覚や聴覚、言語理解、ワビサビ、etc...です。
人間は当り前のようにそれらを実践しますが、具体的な実践手順を逐一把握はしていません。
どうやっているかと聞かれても、抽象的にしか、或いは、感覚的にしか答えることができないのです。
もし、システムに搭載しようと考えた場合には、それら人間の実践について、構成挙動を詳細な単位にまで分解し、再構築する必要があります。
要するに、アルゴリズム化して、プログラムに落とし込む、ということです。
機械に指示ができるレベル、或いは、機械が理解レベルにまで、計算手順を具体化させないと、システム実現できないのです。
つまり、それが法則性の設計と構築です。
そして、ある種の人間の実践については、法則性の設計・構築は、従来困難であったのです。
しかし、機械学習であれば、過去のデータ(実績)がありさえすれば、この法則性抽出に臨むことができます。
コンピューターという高速計算機構をフルに活用して、人間の代わりに頑張ってくれるのです。
(※尚、繰り返しになりますが、機械学習とは実際にはパターンの探索です。)
ただし、機械学習による法則性抽出は万能ではありません。
法則性抽出は、コンピューターリソースの許す限り、幾らでもトライすることができますが、法則性が見いだせないことも多々あります。
それは、予測したい結果事象と、同時発生するような事象が発見できない、ということです。
例えば、「雨」降りの予測をしたい場合で、仮に、データ中にある過去実績が、「低気圧」・「高気圧」に依らず、「雨」が降っていたとしましょう。
そうなると、本来的には「低気圧」が「雨」の予兆であるものの、データ中からその傾向は読み取れない訳です。
つまり、法則性が上手く抽出できないのです。
このようなケースは珍しくありません。
データ中に法則性があるはずだ、と当たりを付けたものの、それに到達できないケースです。
データの形式が、法則性を隠蔽してしまっているケースなどもあります。
見方を少し変えれば法則性が見つかるのに、適した形式になっていないが為に、法則性が見つからないケースです。
そういうケースを避けるために、データに関する専門的な知識をベースにしながら、データ形式の調整などもしたりします。
これはデータクリーニングや、データ加工などと呼ばれ、データ分析における最も高負荷な作業を言われていたりします。
つまりは、AI構築はポンとできる訳ではなく、Try&ErrorやR&Dを重ねることで、ようやく辿り着ける、という具合です。
データ内容・データ形式の事前確認も重要です。
必要に応じては、その調整を機械学習実施前に行わなければなりません。
かつて、日経ビッグデータに、「データ分析=宝探し」という記述がありましたが、実に言い得て妙だと思います。
それも、相当泥臭い宝探しですね。
そんな宝探しのような様相を呈する機械学習、及び、AIですので、開発には、必ずPoCというフェーズを設けます。
PoCとは、Proof of Concept(実現性検証)のことです。
「その法則性抽出は、イケんのか?」ってことを、予め検証するのです。
当然、システムへのAI搭載前に、PoCを実施します。
或いは、完全にAIを前提としたシステムであれば、システム開発全作業の着手前に、PoCを実施する必要があります。
そして、PoCによって、「この法則性抽出は、イケそうだぞ!」という見通しが立てば、AIシステム開発へと舵を切るのです。
逆に、PoCを超えられない場合は、AIシステム開発へは踏み出せません。
法則性が見つけられていない、即ち、自動化の実現方法のアテがない訳ですから、当然ですね。
尚、PoCの壁を超えた場合、機械学習によって抽出された法則性は、以下のような概念にて、システムに搭載されます。
(※アメリカでデータ分析に挑んでいる先輩が教えてくれた、素晴らしい図)

どうでしょうか?
イメージが沸いたでしょうか?
尚、ここで、過去のデータ(過去の気象条件と、降雨結果)は、より多く存在した方が、信憑性の高い法則性が抽出されます。
「10回中8回」よりも、「10,000回中8,000回」の方が、法則性(この場合、80%の確率で雨が降るという法則性)として信憑性が高いことは、直感的に理解が容易いかと思います。
つまりは、データ量が多い程、機械学習によって抽出される法則性の信憑性が高いということです。
その為、AI構築の精度向上のためには、分析対象のデータがビッグデータであることが望ましい、という風によく語られます。
ビッグデータだからこそ見つかる、希少な法則性というものも有り得ます。
ただし、現実には、データ分析文化は過渡期であり、ビッグデータとはいかない小中規模のデータで分析に臨むシーンも多々あるかと思います。
AIの知識は人類の集大成… 深くて広い…
さて、そんなAIですが、それを使いこなすために要する知識が、深く広いのが特徴です。
AIの知識はある種、これまでの人類の知識の集大成と言えるものです。
先ず、数学や統計学などを多用します。
それも、大学以降で習うような高難易度のものを多用します。
もし、より具体的にAI実装を把握したいとすれば、それらの知識をキャッチアップする必要があります。
また、情報系の知識、即ち、コンピューターも多用します。
高度な数学計算を、短時間で大量に行う為です。
仮に、人間が紙とペンで計算をする場合、一生かけても、1つのAIも実現できないでしょう。
囲碁のAIとして有名なGoogleのAlphaGoは、一日で100万局超の対局シミュレーションを行い、それをAIの学習に用いていたそうです。
その位の計算スケールです。
これぞ、正にビッグデータと言えますね。
そんな計算スケールですから、AI実現のための複雑な計算を、現実時間内に終えるために、コンピューターは先ず必須です。
更には、単純にコンピューターを使えば良い話ではなく、高速計算用にコンピューターをチューニングする必要もあります。
その為、ハードウェアの知識も必要です。
また、コンピューターに計算指示を出すためのプログラミングも行わなくてはなりません。
その為、プログラム実装等のソフトウェアの知識も必要です。
つまり、ハードからソフトまで、一気通貫のコンピューター知識が必要となるのです。
或いは、AIによるサービスを搭載・実用化するために、システムやアプリケーションを開発するための知識も必要です。
どういうシステムにどういう載せ方をすると、ユーザーの使い勝手が良いのか、なども考えなくてはなりません。
システムやアプリケーションの上に載って初めて、AIによる自動化が実践される訳ですから、それら開発の知識も必要となるのです。
終いには、何にAIを適用すると良いのか?といったビジネスセンスや、アイデア発想力も必要です。
何を自動化すると、どの位の人を喜ばすことができるのか?
何を自動化すると、どの位の利益を生み出せるのか?
そういったAIを作る目的を、追求できるビジネス力です。
誰も喜ばないAIを作って、研究開発費だけが膨らんでも、悲しいだけです。
これは、システム開発やアプリ開発にも共通する話ですね。
あくまで、AIは手段なのです。
つまり、ザックリまとめると、AIを使いこなすためには、理系の知識と、文系の知識と、情報系の知識をキャッチアップする必要がある形となります。どうでしょう?
「AI=人類の知識の集大成」という感じがしませんでしょうか?
これらの知識の必要性は、日本のデータサイエンス協会が示す、「データサイエンティストに求められるスキルセット」にも示されています。
以下記事です。
記事中に、「データサイエンティストに求められるスキルセット」についての以下のような図示があります。
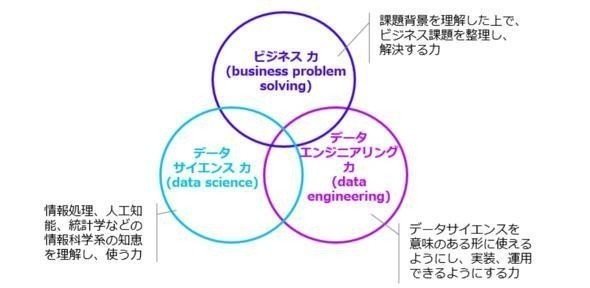
先程のAIの知識の話と同様ですね。
(というか、多分にここから影響を受けています…。)
要するに、データ分析を行うには、または、機械学習・AIを取り扱うには、ビジネス力もデータサイエンス力もデータエンジニアリング力も必要という訳です。
ちなみに、データサイエンティストという職業に馴染みのない方は、以下の記事を参考にしていただけると幸いです。
データサイエンティストとは、データ分析を行う人のことであり、機械学習使い・AI使いという様相を、大いに呈しています。その為、「AIの知識=データサイエンティストに必要とされるスキルセット」と考えて問題ありません。
(※最近、機械学習エンジニアという言葉も生まれてきており、近々もう少し区別されるかもしれません。)
尚、先程の「データサイエンティストに求められるスキルセット」であるビジネス力・データサイエンス力・データエンジニアリング力の3つについてですが、実際には全てを1人でカバーするのは難しく、チームでカバーするのが一般的かと思います。
メンバー1人1人がトライアングルに対して、ポジショニングを取る形です。
例えば、Aさんはビジネス力を、Bさんはデータサイエンス力を、Cさんはデータエンジニアリング力を、という具合にですね。
或いは、Dさんは「ビジネス力:70%・データエンジニア力:10%・データサイエンス力:20%」を、というような中間的にポジショニングも有り得ます。
そうして、チームとして、データサイエンス、及び、AI導入に取り組んでいくのです。
AIを学ぶために、何から始めれば良いか?
さて、ここまでの話を踏まえて、この記事の本題に立ち返ります。
AIを学ぶために、何から始めれば良いか?
結論から言うと、それはAIとの向き合い方によって異なります。
AIの知識は広く深く、1人で全てをキャッチアップするのは至難の業である為です。
ですので、各人におけるAIとの向き合い方、即ち、各人におけるAI知識に対するポジショニングを中心に、キャッチアップをしていくのが一般的です。
そして、AI知識に対するポジショニングとは、先程紹介した「データサイエンティストに求められるスキルセット」に対するポジショニングとなります。
図中のトライアングルは、下記3つの要素からなっています。
(1) ビジネス力
(2) データサイエンス力
(3) データエンジニアリング力
これらに対して、どうポジショニングをするかによって、AIの何をキャッチアップすべきかが変わってくるのです。
尚、AI知識に対するポジショニングは、AI実装を目指すチームにおける、各人の役割とも言えるでしょう。
例えば、AIコンサルタントを実践したい方は、以下のようなポジショニングでしょうか。
AIコンサルタントのポジショニング:
- ビジネス力:55%
- データサイエンス力:15%
- データエンジニアリング力:30%
以上。
AIコンサルタントの場合、AIがどう役に立つのかを、顧客に伝えられることが大事ですよね。
その為、AI知識におけるビジネス力が、最もキャッチアップを要する領域かと思います。
また、実際の問題解決までの絵を描いたり、仮説を立てたりすることも求められるので、一定のデータサイエンス力・データエンジニアリング力も必要でしょう。
そして、どちらかといえば、R&D要素の強いAI適用よりも、実現性の高いAI適用の方が、コンサルティングの真骨頂かと思いますので、データサイエンス力よりもデータエンジニアリング力に重きを置くようなポジショニングになろうかと思います。
勿論、このAIコンサルタントの例はあくまで仮説です。
各人には、得意不得意やスタンスなどもあります。
諸々諸事情に応じた、適切なポジショニングが望ましいでしょう。
先ずは、それに頭をヒネることが大事かもしれません。
AIの知識には、具体と抽象のグラデーションがある
ここで、AI知識について、もう少し掘り下げます。
AI知識とは、以下3つのトライアングルからなるものと、説明をさせていただきました。
(1) ビジネス力
(2) データサイエンス力
(3) データエンジニアリング力
この3つの領域には、AI知識における具体性と抽象性のグラデーションが存在します。
領域1つ1つに着目して、話をさせていただきます。
先ず、AI知識におけるビジネス力。
AIに関して、ビジネス力に長けているとは、AIの適用事例を数多く把握していることや、AIの適用先を新たに創造できることなどが挙げられるかと思います。
AIを売ることが上手かったり、AIによる利益創出に巧みだったり。
つまり、AIビジネスにおける営業力や、コンサルティング力、企画力に長けているということです。
それらビジネス力は、AIそのものの具体的な知識というよりは、AI適用目的を軸とした抽象的な知識です。
「そのAIによって、どんな嬉しさが得られるか?」が、最も重要な関心事であり、「AIがどんな風にして作られているか?」は二の次です。
誤解を恐れずに言えば、それはAIの具体を知らなくても、推し進められないことはありません。
また、企画段階でAIの具体についてキャッチアップすることは、必ずしも得策ではありません。
デザインシンキングや、ロジカルシンキング等々のテクニックの方が、知識としては役に立つのかと思います。
次に、AI知識におけるデータサイエンス力。
これは、データ分析を行い、自動化を実現する法則性抽出を、実際にやり切るための知識のことです。
つまり、「どうデータ分析すれば、良い法則性が抽出できるか?」というような、超具体的な知識となります。
或いは、「結局のところ、自動化はできるのか?できないの?」という問いに対する答えを、精度高く導き出す能力とでも言いましょうか。
尚、データ分析の結果は、抽象的な実現見通しではなく、具体的な実現可能性である必要があります。
例えば、人が行うと正解精度が80%程であるチェック業務があったとします。
仮に、トマトをもぐ作業としましょう。
人が目で見て、ちゃんと熟した甘みのあるトマトをもぐことのできる正解精度が80%です。
この作業の一部自動化、或いは、全自動化を目指す場合、データサイエンティストのGOALは、例えば、正解精度70〜100%の法則性を見つけ出すことです。
データサイエンス力とは、この法則性探索にコミットできる力です。
それは、実現性の高低を多角的に推し量ったみたり、基礎的な手法から先鋭的な手法までを手早く試してみたり、分析結果から経営判断に足る考察を抽出したりすることです。
この試行錯誤が、PoCです。
データサイエンス力とは、このPoCを秀逸に行う力となります。
尚、データ分析が始まった時点で、「もし、○○が自動化できれば、△△だけの利益が創出できるはず」という仮説は、ビジネスサイドが既に立てていることが一般的です。
したがって、データサイエンティストが成すべきことは、「○○を自動化するための法則性抽出」です。
また、どうしても法則性が見つけられないケースもあります。
そうした場合には、どこかで撤退の判断をしなくてはならないのですが、その判断に足る考察を、データサイエンティストがまとめる必要があるでしょう。
「なぜ自動化が実現できないのか?」という問いに、抽象的な回答は適切でないためです。
より具体的な理由を基に、ディスカッションをする必要があるのです。
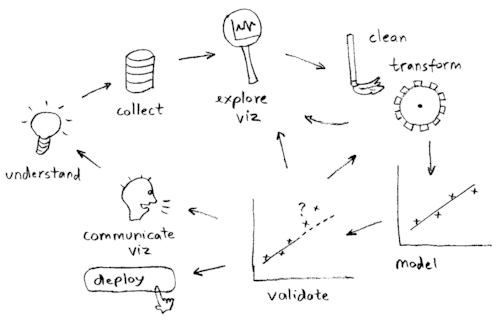
尚、データ分析作業の流れについて、以下のイラストがよくまとまっていた為、拝借しました。
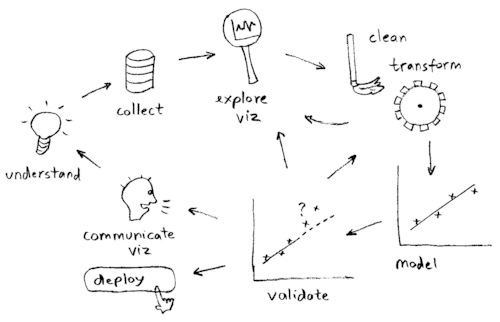
絵の出典は、こちら。
ビジネス力を要するのは、「要件議論(communicate viz)」や「業務理解(understand)」等の、いわゆる上流工程ですね。
そして、データサイエンス力を要するのは、「データ観察(explore viz)」や「データクリーニング(clean)」、「データ加工(data transform)」、「自動化のための法則性抽出(model)」、「精度評価(validate)」等の、いわゆる下流工程です。
「データ収集(collect)」は、いわゆる中流工程です。
ビジネスとデータサイエンスとの間の、中間的な工程ですね。
データ収集の実現方法検討や、費用対効果検討などに関してはビジネス力が必要でしょう。
一方、精度向上というモチベーションで、何のデータをどんな風に集めるべきかという収集仕様考察については、データサイエンス力が必要でしょう。
つまりは、ビジネス力は浅く広い抽象的なAI知識を用して取り組む工程向きで、データサイエンス力は深く狭い具体的なAI知識を用して取り組む工程向きである訳です。
ここには、大きな知識のグラデーションがあります。
さて、AIの知識においては、もう1つデータエンジニアリング力がありました。
それは、ビジネスとデータサイエンスの間に位置するもの、或いは、それらの実現をサポートするもの、という様相のものです。
いわば、AI実現における「縁の下の力持ち」という感じです。
例えば、先程のデータ分析の流れを示す図においては、全てのフローにデータエンジニアリング力が絡みます。
図を再掲します。
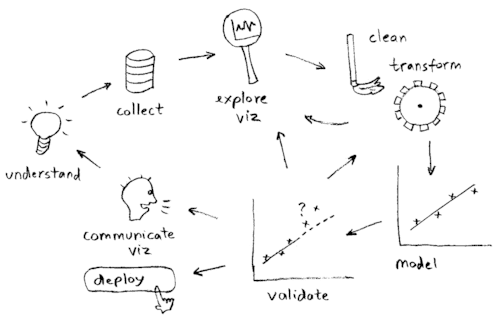
「要件議論(communicate viz)」や「業務理解(understand)」に関しては、当然システム化やアプリケーション化が前提です。
それらインターフェースに乗らなければ、AIによる自動化がスケールし得ないからです。
要するに、AIを使ってもらう為には、システムへの搭載が大前提となるのです。
その為、「要件議論(communicate viz)」や「業務理解(understand)」等の上流工程には、システムの仕様考察に要するデータエンジニアリング力が求められます。
もし、ビジネス力だけで考案されたAIシステムの仕様が、システム的に実現困難なものであったら、スピード感が落ちる為です。
逆に、ビジネス力とデータサイエンス力が上手くマッチして考案されたAIシステムは、スピード感を持ってリリースが可能となり、かつ、使い勝手の良いものとなることでしょう。
「データ収集(collect)」については、実際にデータ収集を実践する際の具体的な仕様考察にデータエンジニアリング力を要します。
センサーからデータを取得したり、既存システムからデータを取り出したり、WEBサービス上からデータ収集を行う仕組みを作ったり。
そして、その収集したデータを格納するディスクや環境を準備・整備したり、管理したり等です。
データサイエンスの実践領域である「データクリーニング(clean)」、「データ加工(data transform)」、「自動化のための法則性抽出(model)」、「精度評価(validate)」等においては、その分析工程にて駆使するコンピューターのパフォーマンス向上に、データエンジニアリング力を要します。
例えば、機械学習による法則性抽出に、1週間かかる場合と、1時間で済む場合とでは、圧倒的に後者の研究効率が高いですね。
研究効率の高さは、データサイエンス力を加速させるものです。
熟練のデータサイエンティストが少ない数のリサーチ結果から導き出す考察と、駆け出しのデータサイエンティストが沢山の数のリサーチ結果から導き出す考察とは、同水準になり得ます。
熟練のデータサイエンティストの経験則を、実測に置き換えてしまえば良いからです。
「百聞は一見にしかず」というか、「百の想像は、一の事実確認にしかず」という感じですね。
コンピューターの計算速度が分析の精度を押し上げるのです。
よって、データエンジニアリング力は、ビジネス力とデータサイエンス力の中間的な知識となります。
それがないと、ビジネスもデータサイエンスも加速せず。
逆に、それがある場合には、ビジネスメンバーやデータサイエンティストが持つスペシャリティを押し上げるよう効果がある。
よって、知識と形態としては、ほどほどに深く・ほどほどに広い形となります。
まとめると、AIの知識のグラデーションとしては…
・ ビジネス力は、広く浅い抽象的な知識
・ データサイエンス力は、深く狭い具体的な知識
・ データエンジニアリング力は、それらの中間。
という感じになります。
最も学習効率が高いのはAI案件に参画すること
ここまでで、AIの知識に対するポジショニングの話と、AIの知識における具体と抽象のグラデーションの話をしました。
次には、具体的に何の媒体を用いて、AIの知識をキャッチアップするのか、について話をしようと思います。
基本的には、学業やスポーツや仕事と同様、練習と実践から学んでいくのが最も学習効率が良いかと思います。
実際にAI案件やAI研究に参画し、必要な知識を随時キャッチアップしつつ、その実践を試すことを繰り返す。
そんなサイクルの中、成功と失敗を繰り返すことで、AI何たるかが身に付いていくことでしょう。
しかし、AI案件は、世の中にそう沢山ある訳ではありません。
そして、AI案件に参画したいと思っている人は、昨今増加傾向かと思います。
すると、どうしても、AIの有識者が優先的に、AI案件に参画していく構図になってしまいます。
その為、ある程度の知識は、いきなりAI案件に参画することになっても対応できるように、予めキャッチアップしている必要があります。
そうでないと、そもそもAI案件への参画が実現されづらいからです。
この人にならお願いしても良いかな、と思った人からAI案件に参画していくのです。
非常に、ニワトリ卵な感じですね。
この手の話は、AIに限った話ではないかと思います。
頑張った人に、優先的にチャンスが与えられる、という話ですよね。
(勿論、運もあります…。私は、圧倒的に運が良かったクチです…。今でも感謝を忘れることはありません…。)
という訳で、AI案件に参画するために、AI知識のキャッチアップを頑張りましょう、という話です。
それでは、どう頑張ったら良いのか。
何を頑張ったら良いのか。
AIのキャッチアップの仕方は、沢山あるから悩みますよね。
私のオススメとしては、先ず、AI知識におけるビジネス力を鍛えるべく、広く浅い抽象的な知識のキャッチアップから始めることです。
営業やコンサルタント、マネジメント、企画といったビジネスサイドの方達は勿論のこと、エンジニアからデータサイエンティストになろうと考えている人なども、先ずはビジネス力の研鑽から始めるのです。
AI案件に参画するために、ビジネス力の研鑽から始める
AIのキャッチアップは、ビジネス力の研鑽から始めるべきです。
その理由は、AI案件においては、各プレイヤーが自走を求められるからです。
各プレイヤーに自走が求められる、というAI案件の特徴は、いわゆる古典的なシステム開発には無かった特徴です。
古典的なシステム開発においては、いわゆるウォーターフォールモデルという後戻りの無い開発工程が採用されていました。
以下図のような形です。

先ず、ビジネスサイドが、「要件定義(Business Requirements)」と「機能設計(Technical Design)」を順番に固めて、それに従ってエンジニアが「プログラム実装とテスト(Coding & Testing)」を行って、最後は「納入検証とサービス導入(Client OK & Launch)」という締めのフェーズに移っていく、という流れです。
上記は、第3次産業革命、いわゆる、IT革命と呼ばれる時代の大規模システム開発などによく見られた開発工程です。
特徴は、先程説明したように、工程に戻りが無いことです。
その頃のシステム開発は、この開発手順で上手くいっていました。
なぜならば、自動化の仕様設計が、人間によって設計可能なもののみを、システム化してきた為です。
例えば、銀行や、流通などの原理は、複雑なようで1つ1つの判断要素は非常に単純です。
数字が、左から右に流れていっているに過ぎないからです。
その為、「要件定義(Business Requirements)」さえ固まってしまえば、それ以降のフェーズにて、「自動化が無理」と判断されることは殆ど無かったのです。
勿論、ウォーターフォールモデルにおいても、1人1人に自走が求められるシーンが無かった訳ではありません。
しかし、そのシーンの頻度は、AI案件に比べれば、少なかったかと思います。
では、AI案件はどんな異なる様相を見せるのか。
先程も説明させてもらったように、AI案件には、Try&ErrorやR&Dが求められます。
つまり、案件内で何度も試行錯誤を行う、ということです。
試行錯誤無しに、AI案件が完了することは100%ありません。
また、工程の途中で、「自動化が無理」と判断され、撤退を余儀なくされるケースも十分に有り得ます。
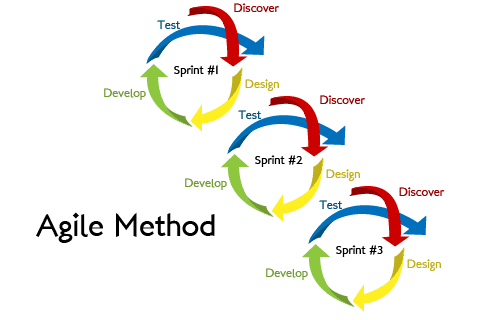
尚、試行錯誤をしながらのシステム開発のことを、アジャイルモデルと言います。
以下図のようなイメージです。
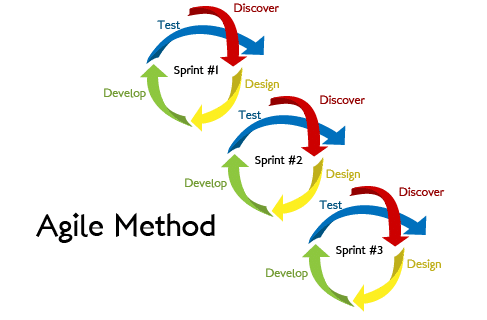
そして、AI開発おいては、試行錯誤を繰り返す中で、想定外の事象が多々発生します。
予想外の分析結果がポッと出てきたり、前提を確認しないと分析が先に進められないような事態に遭遇したり。
その都度、各プレイヤーには、その新しい結果に対して、柔軟に考察を加え、新しいアクションに繋げることが求められます。
高速な試行錯誤のサイクルの中で、都度相談をして解決をしようとすると、モタつくことこの上ないからです。
或いは、単独の結果だけでは何も判断できないような分析結果もあったりします。
複数の結果を見て、初めて判断に足るという分析結果です。
よって、AI案件における相談は、ある程度多数の試行錯誤を行った上で行うことが一般的というか、理想的です。
これは、ビジネスサイド、エンジニア、データサイエンティストに依らず、案件参画メンバー全員に求められる思考プロセスです。
つまりは、各自が自走を求められる、或いは、小規模な単位での意思決定を求められる、ということになります。
その意思決定に際して軸となるのは、AI開発の目的です。
つまり、AIで何を実現するか、何を自動化するか、です。
そこがブレていなければ、大きく間違った意思決定はされづらいからです。
そして、AI案件の目的を上手く捉える力は、ビジネス力です。
「このAIによって、どんな嬉しさが得られるか?」や、「このAIで実現したい世界は、どんなものか?」ということを考える力です。
これを、備えておくことで、仮にデータサイエンス力が未熟なデータサイエンティストであったとしても、少なくとも前に進むことはできる訳です。
逆に、データサイエンス力がどれだけ凄くても、間違った方針で分析していては、GOALには辿り着けません。
そうならないためにも、先ずは一定のビジネス力から身に付けておくべきだと思います。
何よりも、そうすることで、自分が苦労せずに済むかと思います。
チームメンバーからの信頼感も着実に積み上げることができます。
逆に、やった分析が的外れで評価されないなんて、これほど悲しいスレ違いは無いですよね。

AIビジネス力と、一般的なビジネス力は異なる
尚、AI知識におけるビジネス力と、従来の一般的なビジネス力とは、様相が異なります。
基本的な知識は重なるのですが、前者には、AIビジネス特有の知識というものが存在します。
そして、その特有の知識部分は、従来のビジネス力では応用が効かない面が大きいです。
これは、現代と従来とで、システム開発に必要となるスキルセットが異なる点から説明していくと、分かりやすいかと思います。
AI導入なども見越した第4次産業革命に突入している現代においては、開発に必要となるスキルセットは以下となります。

AI時代には、ビジネス力とエンジニアリング力とデータサイエンス力を全て駆使して、開発に取り組んでいく必要があります。
これから、色々なものにどんどんAIが搭載されていくでしょうし、逆に、AIが搭載されないシステムは駆逐されていくことでしょう。
というのも、ある種の課題については、機械学習によって解決した方が、圧倒的にスピード感があるからです。
機械学習は、これまで人間が頭を絞って創出してきたシステム仕様の一部を、機会が代わって自動創出してくれる、という技術です。
それもデータに基づき、公正、かつ、客観的に執り行うために、ミスも少ないです。
そこは機械に変わってもらった方が間違いがなさそうですよね。
私が聞いた話ですと、某大手SIerは既に、AIが絡まないシステムの開発受注を縮小する方針としたそうです。
そういう風潮が加速してくると、尚更、ビジネス力・エンジニアリング力・データサイエンス力が、全て求められる形になっていくでしょう。
そして、それらはどれも欠かせないし、どれも高いレベルを求められる、という形になります。
さて、一方で、一昔前の第3次産業革命においてはどうだったかというと…。その頃は、求められるスキルセットは以下のような形でした。

先程の図と比べて、大分バランスが悪い感じでした。
その理由について、1つ1つ掘り下げていきます。
かつては、蚊帳の外だったデータサイエンス力
データサイエンスやAIといった分野は、第3次産業革命当時はまだ「蚊帳の外」と捉えられていたのが、一般的だったかと思います。
データサイエンス力は、知っててマイナスではないが、プラスにもなりづらい、とい位のものでした。
AIの権威である東京大学の松尾教授などは、この時代のことを氷河期と呼んでいますね。
今でこそ大衆にとって実現可能となったデータサイエンスやAIですが、当時は、コンピューターの計算速度を筆頭として、AI実践のための諸条件が十分に満たされておらず、「AIは机上の空論」と捉えられる傾向が強かったのです。
或いは、IT技術というもの自体が新しい技術であった当時において、そのIT技術を駆使して機械学習を実践するということ自体のハードルも高かったかと思います。
乗りなれていないバイクで、いきなりウィリー走行をするようなものです。
更に、第3次産業革命当時のシステム開発は、昨今のAIシステム開発に実施されるようなR&Dを要することが、殆ど無かったかと思います。
人間がペンと紙で情報処理してきたものを、コンピューターに置き換えようとするものが主流でした。
そういった、自動化・高速化の実現です。
AIを用いる必要のない、シンプルなアルゴリズムにて自動化すべき課題が、市場にたんまりと存在したのです。
尚、シンプルなアルゴリズムとは、例えば、数字を左から右に受け流したり、簡単な四則演算だけを行うものだったり、単純な条件分岐などで処理を制御したり等、人間の頭で少し考えれば、99%正しく組めてしまうアルゴリズムのことです。
要するに、時代のニーズは、まだAIを必要とはしていなかった訳です。
かつて、最も猛威を奮っていたビジネス力
第3次産業革命当時、最も猛威を奮っていたのは、ビジネス力です。
正に、世紀末覇者でした。笑
論理的思考力や、マネジメント力、コミュニケーション能力、営業力、折衝力、企画力、営業力等々…。
これらのビジネス力を持ち合わせている人達が、大変重宝され大活躍していました。
例えば、私が新卒で就職をした2004年頃には、コンサルタントが花形でした。
コンサルタントとは、複雑な課題を紐解き、その解決にコミットする職業です。
これは、当時のIT業界のニーズに、物凄くマッチしていた職業でした。
というのも、当時主流であったシステム開発において、そのシステムの構築の大半を担っていたのがコンサルタントであったからです。
当時主流であったシステム開発は、基本的にシンプルなアルゴリズムを適用を積み上げていくようなものでした。
既に、紙とペンで実践していた商流を、電子化するという形ですから、想像に容易いかと思います。
繰り返しになりますが、要するに、電子化による自動化・高速化でした。
そのようなシステム開発においては、「システムをどう作り上げれば良いか?」というシステムの要件を固める作業、即ち、要件定義の段階で、ほぼシステムの全容が固まると言っても過言ではありませんでした。
7〜8割固まると言っても良いでしょう。
そして、その作業を担っていたのがコンサルタントです。
非常に時代の潮流にマッチした職業であった、という訳です。
彼らは、機械学習を用いる必要は全くありませんでした。
機械学習で解く必要があるような、抽象的な判断基準の自動化ではなかったのです。
機械学習が必要ない為、アルゴリズム構築に失敗するということも有り得ませんでした。
その頃に、ウォーターフォールモデルによるシステム開発が主流であり、現在は、アジャイルモデルが主流なのも、そういう背景からです。
仮に、工程の戻りがあるとしても小さな戻りだけであり、マイルストンとしては大きく一方通行で切ってしまう方が実態に近い、かつ、プロジェクト管理の上で都合が良かったのです。
或いは、要件定義の次には、プロジェクトマネージャーによる設計のフェーズが控えています。
プロジェクトマネージャーとは、システム開発の管理監督を行う職業です。
彼らによる設計フェーズを経ると、システムの全容は9〜10割固まります。
要件定義にて、若干柔らかく定義されていた部分が、設計によってガッチリ固められるからです。
例えるならば、要件定義や設計を経た状態は、プラモデルやパズルのピースをほぼ過不足無く用意された状態と同様です。
その後、残されている工程といえば、組み立て作業のみです。
つまり、第3次産業革命当時のシステム開発においては、ほぼ全ての工程がビジネス力によって完結してしまっていたと言えなくはなかったのです。
勿論、実際にプラモデルやパズルを組み立てる作業は楽ではありません。
しかし、いつの世も評価されるのは、クリエイティブな実績です。
その為、当時は、ビジネス力が特に高く評価されていたのです。
営業力や、企画力についてもそうです。
システムの仕様がシンプルだったので、それを直感的に理解することが容易かった、或いは、理解レベルが抽象的理解でも十分に通用した為、売ること・生み出すことが、ビジネス力でほぼ完結して実践できたのです。
かつて、日の目を見なかったエンジニア
そんな猛威を奮っていたビジネス力に対して、第3次産業革命当時、日の目を見なかったのがエンジニア力です。
なぜならば、先程の例えでいえば、プラモデルやパズルのピースを揃えるのがビジネス力、そして、それをただ組み立てるのがエンジニア力だったからです。
勿論、技術力が頭一つ抜けているエンジニアの方達は話は別です。
システムというものは、基盤の立ち上げが重要です。
その基盤を構築・管理・メンテナンスできる程に深いIT知識を持っている人は、昔も今も大変重宝されているかと思います。
日の目を見なかったのは、そうではないエンジニアの方達の大半です。
皆さんは、IT土方という言葉をご存知でしょうか?
世の中のIT化に伴って、初期的には大変重宝されたエンジニアでしたが、その数が増えすぎたことと、技術の普遍化が進んだことを背景に、薄給で高稼働を強いられるようになり、そう呼ばれるに至ってしまったのです。
現代で言えば、IT技術が発展し、システムで実現できることの幅が広くなってきている為、上流工程がビジネス力だけで突破できなくなってきています。
エンジニア力がないと、手段選択が最適でないケースが起こり得るためです。
しかし、第3次産業革命当時のシステム仕様は、言ってしまえば原始的であった為、「抽象的な理解 ≒ 具体的な仕様」でありました。
システムについて詳しいエンジニアの想定が、コンサルタントやプロジェクトマネージャーの想定を超えることが無かったのです。
つまり、エンジニアを頼らざるを得ないシーンが、殆ど無かったのです。
AI知識におけるビジネス力とは
そんな訳で、ここまでの話をまとめると、以下2点です。
(1) AIを学ぶためには、AI案件に参画するために、ビジネス力の研鑽から始めた方が良い
(2) 従来のビジネス力だけでは、AIシステム開発には通用しない
以上。
つまり、この記事のタイトルでもあるAIを学ぶために、何から始めれば良いか?という問いに対しては、現在のスキルセットや役割に依らず、先ずビジネス力を磨くことから始めるべき、というのが私の考えです。
誰だろうが、AI知識における、或いは、AIシステム開発におけるビジネス力の研鑽から始めるべきです。
では、AI知識におけるビジネス力とはどんなものでしょうか?
それは、以下3つだと思います。
(1) AIの特性を捉えて、提案から、システム設計までが行える力
(2) アジャイル開発の特性を捉えて、システム開発を推し進められる力
(3) 意思決定をトップダウンにせずに、フラットに知識を共有できる力
以上。
尚、私がデータサイエンティストとして働く中で、よく言われるのが「売るものがあったら、提案が楽なんだけどなぁ…」というビジネスサイドの方の意見です。
この意見は全くその通りだと思うのですが、売るものがある状況でAIシステムを提案する力は、AI知識におけるビジネス力ではありません。
それは、もうAIでできることがハッキリしている段階での営業力や折衝力ですので、従来のビジネス力に含まれるものです。
AI知識におけるビジネス力は、その売るものを設計できる力です。
或いは、その売るものを作り上げるまでの過程をマネジメントできる力です。
要するに、AI知識におけるビジネス力とは、より柔らかいものを、色々なものをコントロールしながら、作り上げていく力です。
以降、1つ1つ解説していきます。
AI知識におけるビジネス力 : (1)AIの特性を捉えて、提案から、システム設計までが行える力
例えば、自社製品開発の場合、ヒットするAIシステムをいかに企画できるかがポイントになりますが、ポイントはそれがR&Dを始めてみないと、実現性が分からないことです。
その上で、自分たちがAIで一旗揚げようとしている以上、他のプレイヤーも同じことを考えているはずですので、以下のようなトレードオフも発生します。
・ 実現性が高そうなAIは、開発の成功率が高いが、レッドオーシャン
・ 実現性が低そうなAIは、ブルーオーシャンだが、開発の成功率が低い
尚、実現性の高さはどう推し量るかというと、既に論文発表等で基礎研究結果が出ているか否か、で推し量るのが一般的です。
例えば、AIにおける顔認識の分野は、早い段階から基礎研究のテーマとして加熱していた分野でした。
その為、既に沢山の論文が投稿されています。
即ち、どうやって機械学習を実行すれば上手く識別が行えるか、その実現方法が無料で参照できるのです。
結果として、顔認証を用いたAIシステムは、既に多くのものがリリースがされています。
つまり、レッドオーシャンです。
仮に、このレッドオーシャンに飛び込んでいくとしたら、以下2つの切り口で勝負するしかありません。
・ 多くのプレイヤーの中から、頭一つ抜けた技術力を発揮する
・ 技術的には横並びなものの、秀逸な適用アイデアを創出する
以上。
前者は、相当な技術力が無い限り、リスクが高く。
後者は、想像は発想力が無い限り、リスクが高く。
レッドオーシャンに飛び込むということは、そういうことですね。
また、実現性の低そうなAIとは、主に前例のないAIを指します。
全てを1から作り上げていくものです。
例えば、「学習速度が他社よりも100倍高速なDeep Learningアルゴリズムを作る」等でしょうか。
実現すれば、売れること間違い無しですが、その実現は相当に茨の道かと思われます。
仮に、開発できなかった場合、開発コストは全て無駄になってしまうかもしれません。
だから、ブルーオーシャンなのか…、という具合ですね。
或いは、中間的な、既出の技術を応用させて、全くの別モノに適用する、というAI適用もあります。
レッドとブルーの中間で、パープルオーシャンという感じですね。
「顔が識別できるなら、XXも識別できるんじゃないか?」というような発想ですね。
「(1)AIの特性を捉えて、提案から、システム設計までが行える力」は、そういったバランス感覚が取れる力です。
アイデアの新規性と、技術の実現性のバランスです。
或いは、開発速度感覚も重要です。
既出の技術であれば、実現に要する時間は短く、新規の技術であれば、実現に要する時間は長く、その中間もあります。
速度間隔が、自社と、世の中とマッチするか否か。
その辺りの判断を秀逸に下せることも、その力に含まれます。
特に、開発(エンジニア・データサイエンス)サイドは、「時間さえあればできるはず」と熱狂しがちですので、そこはビジネスサイドが、冷静にマイルストンを設定してあげることが重要です。
また、受託開発請負の場合も有り得ます。
SIer企業などにおいては、その場合が主流でしょう。
その場合についても、基本的な考え方は自社開発の場合と同様で、トレードオフと付き合い方を伝えてあげることが肝要です。
或いは、以下観点に沿って、現実界を導き出してあげることが大事かと思います。
・ AI適用アイデアからコンサルティングしてあげる必要があるか?
・ そのAI適用アイデアは、実施する価値があるか?
・ AI適用に当たって、データ収集の仕組みからケアする必要があるか?
・ AI適用に当たって、その実現性は高いのか、低いのか?
・ 顧客にとって最適なマイルストンは何か?(主に、中止判断)
・ 実運用することになった際には、どういった配慮が必要か?
・ etc…
以上。
要するに、AIという新規性の高い技術のリードをしてあげながら、従来のシステム開発と異なる研究要素の強さを、如何に織り込んで差し上げるかが重要です。
それを考える際には、以前にも掲載した以下図において、どの工程で何をするか、ということを極力ハッキリさせておくことが大事かと思います。
尚、従来のシステム開発と比較すると、成果へのコミット性が非常にグレーである為、委託に関しても「成果物保証」ではなく、「開発工数保証」としている会社が多いかと思います。
「一括請負」でなく、「準委任契約」や「派遣契約」ですね。
AI知識におけるビジネス力 : (2) アジャイル開発の特性を捉えて、システム開発を推し進められる力
これは、マネジメント力に関連した力です。
AIシステムの開発は、必ずR&Dを含みます。
そのResearch(研究)の部分について、以下に柔軟に秀逸にコントロールを加えられるかが重要となります。
開発工程としては、簡易な要検定義・設計にて研究に走り出すアジャイルモデルとなります。
要件や設計は、都度上がってくる研究結果によって、調整を加えていきます。
詳細化したり、軌道修正をしたりです。
或いは、「Go or No Go」の判断も、重要なキーとになります。
途中で、開発プロジェクトをCloseする判断も有り得ます。
その為、「いつまでに○○をトライしてみる」というマイルストンを、適切なタイミングに置きます。
マイルストンとは、システム開発においては、節目や、チェックポイントという意味です。
本来は、1マイル毎に道路脇に置かれた標石のことを指す言葉だそうです。
アジャイルモデルの開発においては、一定の間隔でマイルストンを置くこともありますし、不定期にマイルストンを置くこともあります。
都度適切な期間を調整するようなイメージです。
マイルストンは、長すぎてもいけませんし、短すぎてもいけません。
結果として無駄に終わる研究に長く時間をかけてしまったり、頻度の高いマイルストンが研究速度の低下要因となったりするからです。
或いは、マイルストン毎の報告方法や粒度は、研究実施者、つまり、データサイエンティストに、負荷が極力かからない様に設計することも理想です。
報告負荷が低ければ、マイルストンを細かく設定しても、研究速度が下がりづらいからです。
サッカー選手のメッシは、細かいボールタッチであるにも関わらず、スピードが落ちない為に、華麗にディフェンスを抜き去ることができますが、理想的なアジャイルも正にそのイメージですね。
チーム全体が、メッシの如くGOALに向かっていくよう、コントロールしてあげるマネジメント力が重要です。
AI知識におけるビジネス力 : (3) 意思決定をトップダウンにせずに、フラットに知識を共有できる力
AIシステムの開発においては、実はコミュニケーション能力が、とても重要だったりします。
繰り返しになりますが、一昔前、第3次産業革命頃には、基本的にビジネス力があれば、システム開発を推し進めることができました。
シンプルなアルゴリズムの積み上げで、システム要件やシステム仕様を組んだ時点で、システムの9〜10割が完成していると言っても過言ではなかったからです。

この場合、必要となるコミュニケーションは、ビジネスメンバーからトップダウンの指示が主でした。
「こうこうこういう風に、システムを作ってね」という指示です。
ビジネスメンバーの抽象的な構想が、システムの具体的な仕様と、同等であった為、そうした方が都合が良かったのです。
しかし、そこから現代に向けて技術が発展し、システムで実現できることが増えてくると、徐々にビジネス力だけでは立ち行かなくなってきました。
つまり、抽象的な理解と、具体的な仕様が同等でなくなってきて、リンクしづらくなってきたのです。
その為、エンジニアリング力も無いと、システムの企画や提案が難しくなってきました。
そうなると、企画・提案の時点で、ビジネスメンバーは、エンジニアの知恵も借りる必要が出てきます。
また、第4次産業革命に差し掛かった現代においては、そこにAI・データサイエンスも加わり、よりシステムの仕様は複雑になってきました。
ビジネスメンバー、エンジニア、データサイエンティストが知識を共有しないと、企画・提案が難しくなってきました。

それぞれのメンバーがスペシャリティを持っているという状況は、公平なようでいて、ある種、不安定な状態とも言えます。
全てを把握しているメンバーがいないとも言える状況だからです。
そこで重要となってくるのは、当然ながらコミュニケーションです。
各々が持つ知識を、共有することが重要です。
ただ、知識共有のために頻度高く打合せをしていては、そのコストによって、開発効率が下がってしまいます。
それは、良いコミュニケーションとは言えないでしょう。
その為、コミュニケーション能力がとても重要となります。
相手が望む情報を提供したり、悩みを聞き出したり、雑談をして話しやすい雰囲気を作ったり、等々。
そうすることによって、AIシステムの企画・提案の品質が向上するのです。
AI案件に活きるビジネス力を磨くための書籍
さて、AI知識におけるビジネス力を研鑽するためには、どんなコンテンツを用いると良いかについて話をしたいと思います。
正直、ビジネス力は私の本懐ではないので、大変恐縮なのですが、オススメの書籍などを紹介していきたいと思います。
(1)具体と抽象
この本は、物事の捉え方や考え方について、深く書かれている本です。
特に、物事を具体化に捉えたり、抽象化に捉えたりすることの効果や意義についての解説がされています。
AIについても、相手やテーマによって、抽象的に話す必要があったり、具体的に話したりする必要があったりします。
そのグラデーションの推移は、少し意識しながら話をするだけで、とても伝わりやすくなります。
逆に、抽象的な話から、急に具体的な話に切り替わったりすると、聞き手はとても混乱するのです。
そんな、基礎的なディスカッションノウハウ・プレゼンテーションノウハウが、この本には詰まっています。
(2)ビジネスパーソンのための人工知能
この書籍は、私の師匠の内の1人である巣籠さんが書いた本です。
AI何たるか、先ず抽象的に把握するのに、とても良い本だと思います。
AI導入本は、世の中に沢山ありますが、中でも特に読みやすい本かと思います。
タイトルの通り、ビジネスパーソンに丁度良い抽象度にて、上手く説明がされています。
(3)人工知能システムのプロジェクトが分かる本
AIシステム開発の方法論を、従来のシステム開発の方法論と比較しながら、説明してくれています。
AIシステムはどう開発すれば良いのか、ということを知るために、とても良い本だと思います。
ビジネスパーソンにとっては、企画・要件定義・プロジェクトマネジメントなどの部分が、特に参考になるかと思います。
(4)アジャイルサムライ
アジャイルモデルによるシステム開発なんたるかが書かれている本です。
基礎となるアジャイルの意義などにも触れられており、とても学びが多いです。
特に、流動的な開発に対する心意気の部分は、AIシステムの開発において、とても重要となります。
アジャイルでR&Dを行うので、不測の事態は数多く発生します。
それをどう受け止め、どう対処するか。
或いは、どう想定しておくか。
そういった考え方を学ぶのに、とてもオススメです。
また、ところどころに散りばめられているジョークは、システム開発経験者ならばクスッと笑ってしまうことでしょう。
(5)会話が苦手な人のためのすごい伝え方
コミュニケーションに関して、方法論でなく、気持ちの面から改善せんとする本です。
特に、コミュニケーションにおいて、やってはいけないこととして、「否定してはいけない」「勝ってはいけない」「好かれようとしてはいけない」などを上げている点は、とても参考になりました。
ラグビーじゃないですが、様々なスペシャリティを持ったメンバーがOne Teamにならないと、良いシステムは作れません。
そうなるための基本的な考え方として、上記書籍のエッセンスは必要となるものかと思います。
(6)なんのために勝つのか。
ラグビー元日本代表のキャプテンだった方が書いたチーム論の話です。
特に、大義にコミットすることを重要視する考え方が、AIシステム開発に非常に馴染むと思いました。
AIシステム開発をしていて、よく陥りがちになってしまう勘違いは、如何に高い技術力でそれを実現するかにこだわってしまうことです。
しかし、大事なのはAIを適用する目的であって、方法論ではありません。
これはTED動画で有名な、サイモン・シネックさんも提唱している論理です。
「HOW(どうやるか)や、WHAT(何をするか)は置いておいて、WHY(なぜやるか)から始めよ」いう主張です。
参考になるので、動画も是非どうぞ。
AI知識におけるビジネス力を身に付けた後は、プログラミングを始めよう
ここまで、「先ずは、AI知識におけるビジネス力を身に付けるべき」と説明させていただきました。
さて、そこから先はどうするべきでしょうか?
尚、ビジネス力の収集に関しては、あまり頭でっかちになりすぎることは、得策でないと思います。
ある程度、実践してからでないとピンと来ない理論もあろうかと思います。
逆に、実践を経ると、一気に血肉となるような理論もあろうかと思います。
ですので、ビジネス力はある程度備わったら、次のステップに移るべきです。
その次のステップとしてオススメなのは、プログラミングの学習です。
プログラミングは、データサイエンスとエンジニアリングの両方の基礎知識となります。
つまりは、ビジネス力の次は、データサイエンス力、或いは、エンジニアリング力の何れかをキャッチアップすべきだと、私は思います。
尚、プログラミングの学習をオススメするのは、データサイエンティストやエンジニアリングの役割の方だけでなく、ビジネスサイドの役割の方も同様です。
オススメの理由として、最も大きいのは、より具体的な世界観に慣れ親しむ為です。
例えば、ビジネスメンバーが担当する作業は主に、抽象的なものが多いかと思います。
よくあるのが、「要は、○○」で説明できれば理解ができている、という考え方です。
或いは、自分の言葉で説明ができたら理解ができている、という考え方です。
しかし、それは正確には抽象的な理解であることが多いかと思います。
具体的な理解まで至っているかというと、何とも言えません。
例えば、「会社の社員出入り口に、顔認証システムを搭載したい」という顧客からの要望があったとしましょう。
そして、「うちの会社にはデータサイエンティストとエンジニアが在籍しているし、世の中には既に同様の研究成果やビジネス事例も幾つか出ているし、多分できると思います。」と言って、会社に持ち帰るビジネスメンバーがいたとします。
この対応はどうでしょうか?
良い対応でしょうか?
悪い対応でしょうか?
もし、私が同じ話を持ち帰られたら、基本的には「スゴい!」と思うのですが、欲を言えば「惜しいなぁ…」と思ってしまいます。
先ず、顧客と面会することができて、AI導入の話を持ちかけられている時点で、このビジネスメンバーはとても優秀な方だと思います。
巧妙なアプローチによって、そういった要望を勝ち取っているのです。
それは、高いビジネス力があったからこそ実現できたことでしょう。
しかし、欲を言えば、もう少し具体的な要望を掘り下げてきて欲しかったなぁ、と思います。
そうしないと、顧客に対するヒヤリング回数が増えてしまうからです。
或いは、それによって、受注是否の判断が遅れるからです。
例えば、具体的な要望の掘り下げとしては、以下等です。
「カメラはどんなカメラを使用するのでしょうか?」
「識別に要する時間は、何秒くらいのイメージでしょうか?」
「識別の精度は、100%ミス無しをご所望ですよね?」
「顔画像データは、既に集まっていますか?」
言われれば、「ああ、そんなもんか…。」というレベルの他愛ない質問だと思いますが、瞬発的にこの発想が湧くかどうかが大事です。
本当の理想を言えば、AIシステムの要件を決めるに足る情報を、その場で収集してしまうのが理想的です。
そうすると、次に顧客に会う際に、提案ができるからです。
しかし、流石にそこまでは、データサイエンティストやエンジニアなどが同行していないと難しいかと思います。
ただ、同行無しでも、できるだけその状況に近づけるよう心掛けることで、有効なヒヤリングを行うことは可能かと思います。
そうなってくると、学ぶべきは具体の世界なのです。
そして、より具体的に物事を掘り下げるエクササイズとして、適切なのがプログラミングだと思います。
なぜなら、何れにせよ最終的には、システム実現するからです。
プログラミング実装するからです。
考え方の方向性としても、親和性が高いのです。
或いは、データサイエンティストやエンジニアの気持ちを知る、という意味でも効果が高いのです。
実際、昨今では、ベンチャー企業におけるプログラミング未経験の経営層などが、データサイエンティストやエンジニアの気持ちを知るために、プログラミングを後天的に学習するケースが、増えてきているそうです。
或いは、会社としてサービスをシステム実装するのだから、経営層もその具体の世界を把握しておく必要がある、というモチベーションです。
尚、データサイエンティストやエンジニアを目指す人は、当然のことながら、プログラミングは必須です。
プログラミング言語は、Pythonを学ぶべき
それでは、そのプログラミングはどう学ぶべきでしょうか?
プログラミングを学ぶと一口に言っても、色々なことを配慮しなくてはなりません。
先ず、どのプログラミング言語を学ぶべきかです。
プログラムとは、コンピューターに計算指示を送るための、一連の命令を連ねたもの、即ち、指示書類のようなものなのですが、書き方に種類があります。
その書き方の種類が、プログラミング言語です。
どのプログラミング言語で、指示書類を書くか、という選択肢があるのです。
尚、プログラミング言語間にどんな違いがあるかというと、主に以下2つです。
・ プログラムの搭載先による違い(搭載ハード別に、向き不向きがある)
・ 文法が細かく小回りが効くか、文法が簡単で大雑把な制御かの違い
前者は、例えば、スマートフォンに載せるのか、WEBページに載せるのか、或いは、大規模なシステムに載せるのか、というような違いです。
載せるハード別に、それに適した言語というものが存在します。
尚、その適性とは、裏を返せば、過去のサンプルが多いものとも言えます。
後者は、プログラミング言語の構成の話ですが、大まかに言えば、プログラムの挙動制御の細かさと、プログラムの複雑さとにトレードオフの関係性がある形です。
シンプルな言語が好まれるものの、細かく制御しないと実現できないようなタスクには、少し複雑な言語を用いる必要がある、という感じです。
しかし、どの言語も概念は概ね一緒であり、何から勉強しても良いかと思います。
完全に初心者の方は、チームメンバーのデータサイエンティストやエンジニアにヒヤリングをして、自分と関連の深い言語を選択すると良いでしょう。
個人的にオススメなのは、データサイエンティストが、必ず用いているであろうプログラミング言語であるPythonです。
とても分かりやすい言語構成ですし、学習のコストも低めかと思います。
プログラミングの学習方法は、覚悟とお財布事情とかける時間による
続いて、プログラミングの学習方法についてです。
幾つか選択肢はあると思いますが、ポイントは以下トレードオフかと思います。
・ 如何に、短い期間で学習するか
・ 如何に、お金をかけずに学習するか
要するに、「お金で時間を買うか否か」という話です。
近道にはお金がかかる、ということですね。
「お金を掛けてでも、学習効率を高めたい!」という覚悟のある方にオススメなのは、講師を付けることでしょう。
また、講師を付ける場合にも、通学かオンライン受講という2つの選択肢があります。
例えば、通学とオンライン受講の2つがあり、有名なのは「TECH::EXPERT」などですね。
コンテンツが確立されているようですね。
或いは、オンライン受講では、「侍エンジニア塾」なども有名です。
ここは、受講者の要望によって、カリキュラムをカスタマイズできるのが、面白いポイントかと思います。
講師が、専属マンツーマンという特徴もあるようです。
これらのメリットは、筋トレのパーソナルトレーニング同様、短期集中でコミット確率が高い、ということですね。
経験者の講師が付くので、学習速度も安定的に高速であるでしょう。
デメリットがあるとしたら、価格が高いことです。
お財布事情が厳しい方は、なかなか難しいかもしれません。
そこで、もう少し安価にプログラムを学べるコンテンツとして、講師不在のオンライン学習コンテンツなどがあります。
私が使ってみて良かったのは、以下2つです。
前者、Progateは、様々な言語を学習することのできるオンラインコンテンツです。
講師が付かない分、比較的安価となります。
内容も充実しており、かつ、分かりやすい造りとなっています。
後者、PyQは、Pythonに特化した、オンライン学習コンテンツです。
学習対象を、Pythonに絞っている分、学習できる内容が深いです。
Pythonを学習したいと考えている人には、オススメです。
更に安価に学習したい、或いは、自分のペースでじっくり学習をしたい、という方は、書籍で学習するのが良いでしょう。
例えば、私は以下の書籍などが、分かりやすいと思いました。
上記は、Pythonの解説書ですが、同シリーズで他言語の解説書もあります。
イラスト付きで、ほんわか和みながら学習することができます。
尚、Pythonを学習するに当たっては、以下の記事なども参考にしてもらえればと思います。
Pythonのプログラムを実行する環境としては、AnacondaのJupyter Notebookがオススメですが、そのインストール方法や使い方などについて書いてある記事です。
また、最近の流行りとしては、Udemyで動画コンテンツを購入することもオススメです。
例えば、Udemy上で「Python」と検索した結果のリンクが以下です。
講師を付けるには、ちょっとお金が厳しい…。
しかし、字面だけで学習すると、どうにも眠くなってしまう…。
そんな方にオススメなのが、Udemyの動画コンテンツです。
尚、Udemyは、たまにセールをやっているので、セール中に購入すると、よりお得になります。
大急ぎでない場合には、セールを待った方が良いかもしれませんね。
プログラミングを身に付けた後には、ついに機械学習のキャッチアップに取り掛かろう
さて、AI知識におけるビジネス力を身に付けて、プログラミングもできるようになったら、次にはいよいよ機械学習のキャッチアップを行いましょう。
機械学習のキャッチアップは、割とハードワークになるかと思います。
解くに数学アレルギーの方などは、結構しんどいかと思います。笑

しかし、個人的には、順調に学習が捗れば、半年程でキャッチアップすることも可能かと思います。
「半年…!?」と思う方もいるかもしれません。
勿論、機械学習領域全般のキャッチアップを指している訳ではありません。
ジュニアのデータサイエンティストとして走り出せるくらいのキャッチアップレベルを指しています。
例えば、簡単なAI案件であれば、1人でも何とか分析ができる。
難しいAI案件であっても、シニアのデータサイエンティストの配下で、一部分析作業を担当できる。
そのような、機械学習の基礎のキャッチアップまでに半年です。
尚、ジュニアのデータサイエンティストとして、走り出すことさえできれば、データサイエンティストが不足していると言われる昨今においては、AI案件に参画することは、決して難しくないことかと思います。
勿論、参画できるかどうかは、運もあります。
アピールの必要もあるでしょう。
(そこで、やはり活きるのはビジネス力かと思います。)
ちなみに、私がジュニアのデータサイエンティストほどに、機械学習の基礎をキャッチアップしたのも、半年程だったかと思います。
1年経った頃には、基本的な機械学習手法について、自らスクラッチで実装できるレベルになっていました。
(当時はライブラリも少なく、逆に、そういったスクラッチ実装のスキルが、現在に比べて重要だった、という背景もあります。)
ただし、私の場合、キャッチアップが早期実現できたのは、完全に周りに教えてくれる人が沢山いたお陰でした。
超好条件下における半年です。
そこに関しては、少し後ろめたい思いがある程です…。
(その為、その当時、私に機械学習を教えて下さった全ての方に、感謝の気持ちを忘れることはありません…。😭)
また、私が一緒に仕事をした中で、機械学習の基礎を半年以内にキャッチアップした方は、何人かいらっしゃいました。
特に、若い人は、とてもキャッチアップが早いですね。
小さい頃から、インターネットに触れてきているので、情報収集の仕方も秀逸です。
或いは、20代前半で、高卒で、文系クラスで、携帯ショップの販売スタッフだった経歴から、一念発起してエンジニアになり、3ヶ月の社内プログラミング研修の後、機械学習のキャッチアップを始めてから、半年で機械学習の基礎をキャッチアップしたという方もいらっしゃいました。
その方が見せたキャッチアップ感は凄まじいものでした。
とまあ、そんな感じで、色々見てきた中から、私がオススメする機械学習基礎のキャッチアップ手順は以下です。
(1) 円周率を、初歩的な機械学習ロジックで求めてみる
(2) 数独の解読を、初歩的な機械学習ロジックで求めてみる
(3) 回帰分析を、原理からしっかり学び、スクラッチ実装してみる
(4) 決定木を、原理からしっかり学び、スクラッチ実装してみる
(5) データクリーニングを学ぶ
以降で、1つ1つ説明をしていきます。
(1) 円周率を、初歩的な機械学習ロジックで求めてみる
それでは、機械学習のキャッチアップを進めていきましょう。
先ず、やってもらいたいのは、円周率の計算です。
皆さん、円周率はご存知かと思います。
円周率:π=3.141592...というやつです。
半径×半径×円周率で、円の面積が求まることは、小学校で学びますよね。
その円周率については、実は、初歩的な機械学習の実践にて、導出することができます。
その求め方は、以下の考え方に沿ったものです。

あなたが、正方形の的にダーツを投げるとします。
この時、ダーツは、的上に偏りなく刺さるものとします。
真ん中に偏ることもなく、端に偏ることもなくです。
的については、その一辺の長さを 1 とします。

すると、正方形の的全体の面積は、1 × 1 = 1 となりますね。
また、円の内側を当たりとした場合、半径は 0.5 ですから、当たりの円の面積は、0.5 × 0.5 × 3.141592… = 0.785398… となりますね。
つまり、的全体の面積に対して、約79%が当たりの円部分という訳です。
さて、この的に対して、偏り無くダーツは刺さる前提ですので、当たり部分にささるダーツは、100本中の約79本、1,000本中の約785本、10,000本中の約7,854本となります。
面積の比率が、そのまま当たりに刺さる本数に反映される訳です。
ここで、仮に、円周率が幾つかを知らなかったとしましょう。
その場合、当たり部分の円の面積は、0.5 × 0.5 × ? となります。
円周率を p と置くと、当たり部分の円の面積は、0.5 × 0.5 × p = 0.25p となります。
この 0.25p は、的全体の正方形の面積に対する、当たりの円部分の面積の比率でした。
円部分が、正方形の何%を締めているか?という割合です。
そして、ダーツは偏り無く的に刺さるために、この面積比率がそのままダーツの当たり本数に反映されます。
ここから、少し頭を捻ると、的全体の正方形の面積と、当たり部分の円の面積と、投げたダーツの本数と、当たりに刺さったダーツの本数との間には、以下の関係性があることに気が付きます。

そして、比率の式は、以下のように変換することができます。

外側同士を掛けたものと、内側同士を掛けたものが等しくなるという法則です。
ここで、正方形の面積は既知の値です。
1 × 1 = 1 です。
円の面積は、円周率が未知だとして、0.5 × 0.5 × p = 0.25p です。
投げたダーツの総本数と、当たりに刺さったダーツの本数は、投げてしまえば既知の値となります。
例えば、「総本数:10,000本に対して、当たり本数:7,900本であった」等です。
尚、「投げてしまえば」というのは、「シミュレーションをしてしまえば」という意味です。
後ほど、そのシミュレーションプログラムについては、解説をします。
例えば、上記のような結果であった場合、以下の式…

…は、「1 × 7900 = 0.25p × 10000」となります。
この方程式を「p = …」の形に変形すると、「p = 3.16」となります。
真の正解である円周率:π = 3.141592… から少し外れているのは、シミュレーション結果の「当たり本数:7,900本」というのが、ちょっと偏った結果であったからですね。
もし、「当たり本数:7,854本」であれば、「p = 3.1416」という真の正解に近い値に辿り着くことができていました。
とまあ、このようにシミュレーションを用いて、円周率を求める訳です。
上記例のような真値とのズレは、シミュレーションにおいて不確定要素が存在するためです。
これは、しょうがないことです。
しかし、シミュレーション回数を増やすことで、確率を収束させること、つまり、その不確定要素を抑えることはできます。
どうでしょうか?
なんとなく、原理はつかめたでしょうか?
それでは、円周率を求めるためのシミュレーションを、Pythonを用いて実施してみましょう。
そのプログラムは以下となります。
# numpyのインポート
import numpy as np
# シミュレーション回数(投げるダーツの総本数)を設定
shoot_num = 1000000
# 当たりに刺さった数をカウントするための変数を定義
hit_num = 0
# シミュレーションループ
for i in range(shoot_num):
# 投げたダーツが、正方形の的上のどこに刺さったかを、
# 偏りのないRandom値にて決める
x = np.random.rand(1) - 0.5 # x座標(-0.5〜0.5)
y = np.random.rand(1) - 0.5 # y座標(-0.5〜0.5)
# 中心座標からの距離を計算
d = np.sqrt(x**2 + y**2)
# 中心座標からの距離が、半径0.5以内かどうかを判定
# (ダーツが当たりに刺さったかどうかを判定)
if (d <= 0.5):
#
hit_num += 1
# 円周率を計算する
p = hit_num / (shoot_num / 4)
# 出力
print('p = %.10f' % p)恐らく、一般的なPCをお使いの方で、10秒前後で結果が帰ってくるかと思います。
私の環境で、プログラムを何度か動かしてみたところ、以下の結果が帰ってきました。
(1回目)p = 3.1440200000
(2回目)p = 3.1415120000
(3回目)p = 3.1392200000
(4回目)p = 3.1394360000
(5回目)p = 3.1426280000
まあまあ、真に迫った結果が出てきていると思います。
尚、シミュレーション回数は、1,000,000回実施しています。
もっと、シミュレーション回数を増やせば、更に真に迫る値が、取得できるかと思います。
確率のブレが、数をこなすと収束してくるためです。
これが、機械学習の基本的な考え方である、コンピューターの計算力を駆使して答えを求める、という感覚です。
人間の代わりに機械が考えてくれている、というと聞こえは良いですが、実際にはこのように、愚直に探索を行ってくれている形です。
また、ダーツのシミュレーションに関しては、乱数発生器がプログラムの標準機能として備わっている為に、実現できるものです。
その辺りは、Python開発者、そして、numpy開発者様々という感じです。
尚、プログラムは、是非、上のプログラムをコピペするだけでなく、自らコードで書いてみて、計算してみて下さい。
その方が断然、理解が腑に落ちるかと思います。
ちなみに、こうしてシミュレーションを通じて、何かの値を求めることを、モンテカルロ法と言います。
モンテカルロ法は、強化学習と呼ばれる機械学習手法の内の、最も基本的な解法となります。
(2) 数独の解読を、初歩的な機械学習ロジックで求めてみる
さあ、次の機械学習のキャッチアップです。
次は、数独の読解を、先程と同じモンテカルロ法も交えながら、解いていくということに挑戦しましょう。
皆さん、数独はご存知でしょうか?
縦横9マスの盤面に、1から9までの数字を埋めていくというゲームです。
尚、ルールとして、縦1列・横1列・特定の3×3ブロック内にて、同じ数字が存在してはいけない、という縛りがあり、そのルールをかいくぐる必要があります。
上手く数字を埋めきれれば、ゲームクリアです。
数独について、詳しくは以下を参照下さい。
さて、この数独を、プログラムを用いて解いていきます。
数独自体は、ルールが分かれば、取り組みやすい課題かと思います。
しかし、やってみるとなかなかどうして、結構手こずります。
特に、上級者向けの問題などは、一筋縄には行きません。
一般的に、人間が取り組んで難しい課題というものは、プログラムで解こうとした時も難しくなるものです。
プログラムで表現するアルゴリズムが複雑になってくるためです。
数独に関しても、その該当かと思います。
WEB上に上がっている各種数独の解説を読みながら、アルゴリズムを組んでいこうとした時に、プログラムへの落とし方に悩む考え方が幾つもあるかと思います。
一方で、機械学習との関連についてですが、この数独読解についても、円周率の時同様、モンテカルロ法を適用することができます。
例えば、以下のような問題があったとします。

この問題は、Wikipediaの「数独」ページから拝借したものです。
与えられた問題に対して、埋めるべきは空白のマスです。
空白マスに適切な 1〜9 の数字を埋めきればGOALです。
その空白のマスに対して、モンテカルロ法を適用するのです。
1〜9 の数字をランダムに生成しては、空白マスにハメ込んでみて、ゲームのクリア条件を満たしていたらシミュレーション終了。
設定した数字が、ゲームのクリア条件を満たしていなかったら(縦1列に同じ数字がセットされている等)、もう一度シミュレーションを行う。
そういった処理を繰り返すプログラムを書くのです。
もはや、数独の楽しみはフッ飛んでしまっていますが、計算力が凄まじければ、その方法で解けないことはありません。
人間が考える代わりに、コンピューターの答えを導出する。
機械学習の醍醐味ど真ん中です。
しかし、そうした力任せの方法で解こうとした場合、ブチ当たるのは計算速度の壁です。
コンピューターの計算速度が早いとはいえ、ちょっとムチャな計算回数となってしまうからです。
現実時間内に、解答に辿り着けないのです。
例えば、先程の問題の例ですと、空白マスが51マス存在しました。
数独の答えは、唯一の組み合わせ解が用意されていることが一般的なので、51マスには特定の数字ワンパターンが設定されるとすると、その解を発見できる確率は、「1 ÷ 9⁵¹」となります。
「9の51乗」分の1です。
何回シミュレーションしても引き当てられなそうな確率ですね。
その為、数独を解くプログラムを書く場合には、幾らか候補の数字を絞ってあげた上で、モンテカルロ法を適用する必要があります。
そうすれば、シミュレーションによって解に辿り着ける確率が高くなります。
その時、その候補を絞る処理のプログラミングと、モンテカルロ法で解に辿り着ける確率との間には、幾つかのトレードオフが発生します。
例えば、処理時間と作業負荷のトレードオフです。
モンテカルロ法の適用前に、対象がしっかり絞れていれば、シミュレーション回数が減って、数独の読解にかかる時間は短くなります。
一方で、モンテカルロ法で試す対象を絞るために、プログラミング(仕様考察も含む)を頑張っていると、そこに作業負荷が発生します。
人間の考える範疇が広くなって、機械学習の適用範囲が狭まるためです。
数独に限らず、機械学習で解く問題全般に、このトレードオフはもれなく発生します。
数独の場合、読解にかかる時間がトレードオフの対象ですが、他の問題であれば、例えば、識別精度などでそのトレードオフが発生します。
機械学習も万能ではないので、できるだけ分かりやすい形に加工されているデータの方が、識別精度は高くなりやすいです。
例えば、スマホのベルトコンベアー上に流れてくる製品について、不良品を検知するシステムを作りたい場合、カメラ撮影における被写体の映り込み方は、ある程度一定である方が識別精度は出しやすくなります。
毎回、寸分たがわぬ向き・角度で、製品が流れてくるイメージです。
その場合、機械学習側は、特定の映り込み方にだけ集中して、法則性の抽出を行えば良くなる為、タスクとして非常にシンプルです。
逆に、あらゆる向き・角度を想定して、法則性を抽出しようとした場合、学習に必要なデータは沢山必要となりますし、解こうとする問題が複雑になるために、識別精度が出づらくなるのです。
機械学習側に、解く問題をシンプルに提供しようとする場合、人間側の工夫が必要となります。
どうすれば、数独におけるモンテカルロ法のシミュレーション回数を減らせるか?
どうすれば、ベルトコンベアー上の製品の向き・角度を統一できるか?
等々。
まだまだ、この部分は、人間とAIとで、手を取り合っていかなければいけない部分です。

尚、このようなトレードオフが発生してしまうのは、現在のテクノロジーの頭打ちとも言えます。
仮に、データが無限に収集できて、コンピューターの計算も無限の速さで実現できる場合、このようなトレードオフは発生しません。
ともかく、沢山のデータを見せて、沢山の学習をさせれば良いからです。
しかし、テクノロジーで超えられない壁は、まだまだあります。
そこをどう折衷していくか。
このポイントは、現在の機械学習における、ある種の腕の見せどころと言えます。
尚、その感覚を掴むに当たっては、数独のプログラム解読は、非常に有意義です。
恐らく、突き詰めれば、モンテカルロ法を使わずとも解くことはできるでしょう。
しかし、その仕様設計は、複雑さを極めることが想像できます。
かといって、全てをモンテカルロ法で解決しようとするのは、現在のコンピューター速度では難しい。
そこで折衷案を探る形になっていきます。
そんな数独のプログラムに関しては、以前、ExcelのVBAで書いたものがあるので、それを載せます。
若い頃に書いた汚いコードで、結構恥ずかしいのですが……。
コードの汚さはともかく、割と良い感じにスピード感をもって、数独問題を解いてくれると思います。
Pythonのプログラムは、時間ができたら、実装してUPしようと思います。
ちなみに、本当はC++などで実装するのが、スピード的には良いと思います。
Pythonで、for文を多用すると、パフォーマンスがあからさまに落ちるので。
(3) 回帰分析を、原理からしっかり学び、スクラッチ実装してみる
数独まで実装できたら、あなたのデータサイエンス力やエンジニア力は、結構高いレベルになっているかと思います。
数独の読解プログラムは、一線で活躍しているエンジニアにおいても、なかなか手を焼く問題です。
勿論、この手の実装をできることが、現場での活躍に直結するかというと、そうも言い切れないところはあります。
ですが、少なくとも基礎素養として、骨太なものが身に付いていることは、間違いありません。
そこは是非、自信を持っていただきたいと思います。
特に、機械学習の理論や実装を学ぶための素養は、数独のプログラム実装を経たことで身に付いています。
なぜなら、機械学習全般が、円周率を求める問題や、数独を読解する問題と、大きくは変わらないからです。
機械学習の基本的な考え方は、コンピューターの計算速度を利用して、愚直な探索をすることです。
その感覚が身に付いていれば、機械学習の原理理解は比較的スムーズに進められるかと思います。
ただし、先程の数独の読解と同様に、問題によっては愚直に解こうとすると、コンピューターの計算速度を用いたとしても、現実時間内に計算を終えられないものが存在します。
現実時間内に、解に辿り着けないのです。
そこで、機械学習のアルゴリズムは、全般的に数学を用いた高速化の工夫が用いられています。
考え方は、数独で探索対象を絞るのと同じ感覚です。
古来より培われてきた数学の知識を導入することで、機械学習で求めたい解の探索における、探索範囲の絞り込みを実現するのです。
特に、機械学習の「基本のき」である回帰分析は、その考え方を学ぶのにうってつけのアルゴリズムです。
現在、流行しているDeep Learningの基礎アルゴリズムでもあります。
回帰分析に毛がボーボーに生えたのが、Deep Learningです。
その為、回帰分析を理解すれば、Deep Learningの基礎が理解できたといって、過言ではありません。
基礎的な考え方の上に、上級アルゴリズムが成っているのです。
また、回帰分析の実践方法は幾つか考えられるのですが、一般的には最小二乗法という数学的な考え方が用いられます。
最小二乗法という考え方を用いると、探索範囲を狭めるどころか、探索すら必要とせず、一度の計算で解を求めることができるためです。
さて、抽象的な話が続いてしまいました。
具体的な回帰分析の内容説明や、アルゴリズムの解説についてですが、結構長い話になります。
そして、実は現在、私はその解説書籍を執筆中です。
その書籍が晴れて発売されましたら、ここで紹介させていただきたいと思います。
ネット上で探したところでは、以下の解説記事が分かりやすいかと思いました。
また、導入本としては、以下の書籍などがオススメです。
マンガなので、挫折することなく読み進めることができるかと思います。
現状、この記事における内容が薄くて申し訳ないのですが、回帰分析に関する内容は以上となります。
いずれ、内容を補強したいと思います。
(4) 決定木を、原理からしっかり学び、スクラッチ実装してみる
回帰分析が学べたら、次には、決定木を学ぶと良いかと思います。
機械学習の流派としては、大きく2つの流れがあり、1つは回帰分析をベースとしたもの、もう1つは決定木をベースとしたものです。
手法の名前だけ上げると、回帰分析をベースとしたアルゴリズムとしては、Deep Learning や、Support Vector Machine などが有名です。
決定木をベースとしたアルゴリズムとしては、Random Forest や Gradient Boost などが有名です。
どれも、Kaggleなどで、頻繁に用いられる高性能な機械学習アルゴリズムになります。
そんな背景から、回帰分析に加えて、決定木のアルゴリズムを原理から習得すれば、機械学習全般の基礎が、概ね把握できている形となります。
機械学習を実践していく上で、基礎を抑えていることは非常に大事です。
是非、2大基礎アルゴリズムである回帰分析と、決定木を、原理からしっかり学んで欲しいと思います。
また、決定木に関しても、回帰分析と同様、機械学習の基本である、コンピューターの計算速度を活かした愚直な探索を行うのに加え、数学的な考え方を用いて、その探索範囲を狭めるような工夫が行われています。
そして、こちらについても、具体的な解説はまだ書けておりません。
回帰分析の執筆が終わった後に、決定木の解説についても記事なり書籍なりで書けたらと思っています。
尚、ネット上に上がっている情報ですと、以下の記事などはとても分かりやすいです。
或いは、以下、私の手前味噌記事ですが、基本的な決定木のアルゴリズムに触れながら、精度向上のためのオプションについて解説しているものです。
こちらも、現状、この記事における内容が薄くて申し訳ないのですが、決定木に関する内容は以上となります。
いずれ、内容を補強したいと思います。
(5) データクリーニングを学ぶ
機械学習の基礎キャッチアップの最後に、データクリーニングを学ぶことをオススメします。
データクリーニングとは、データを分かりやすい形に加工してあげることです。
前処理や、データプリパレーション、データクレンジングなどと呼ばれることもあります。

繰り返しになりますが、機械学習はまだまだ万能ではなく、データを極力分かりやすい形に加工してあげた方が、法則性の導出にかかる時間が短かったり、導出した法則性の精度が高くなったりします。
「データクリーニングが、精度の8割を決める」という風に言われたりします。
私も同意見で、決して大袈裟な表現ではないと思います。
或いは、データクリーニングをしないと、ある種の機械学習手法は適用が難しかったりします。
機械学習の適用を幅広く行うためにも、重要な技術という訳です。
尚、データクリーニングは、機械学習の前座というような、脇役的なイメージが強かったりするものですが、実際にはデータ分析の大半の時間は、データクリーニングに費やすのが一般的です。
「データクリーニングが、分析作業負荷の8割を占める」という風に言われたりします。
私の経験からも、概ねその通りかと思います。
そんなデータクリーニングの、具体的な内容ですが、大いに Data by Data です。
データの種類が変われば、データクリーニングの方針もガラッと変わります。
幾つかの汎用的なデータクリーニング方法については、以下の記事などを参考にすると良いかと思います。
とても分かりやすい記事です。
もう少し原理原則的な話は、いずれ体系立てて、記事にしたいと思います。
おわりに
以上で、AIを学ぶために、何から始めれば良いか?についての記事を終えます。
書き始めたら、随分と長くなってしまいました…。
ここまで読んでくださった方、本当にありがとうございます🙇
オススメのキャッチアップ手順をまとめると…。
先ず、AI・機械学習・データ分析の取扱で迷子にならないように、AI知識におけるビジネス力を付ける。
次に、具体を考える力を付けるため、或いは、データサイエンティストやエンジニアの気持ちを知るために、プログラミングを学ぶ。
最後に、機械学習の基礎キャッチアップとして、以下を実施する。
(1) 円周率を、初歩的な機械学習ロジックで求めてみる
(2) 数独の解読を、初歩的な機械学習ロジックで求めてみる
(3) 回帰分析を、原理からしっかり学び、スクラッチ実装してみる
(4) 決定木を、原理からしっかり学び、スクラッチ実装してみる
(5) データクリーニングを学ぶ
という感じです。
参考にしてもらえましたら、幸いです。
この記事が気に入ったらサポートをしてみませんか?