
【Python】Webページから表を抜き出して、Excelファイルにする

Webページに貼り付けてある表をExcelに取り込みたいとき、以前はいちいちコピペするか、選択してExcelに貼り付けたあと、書式を整える手間が必要だった。最近のExcelは、単純なコピペでも表組みを正しく理解して貼り付けることが可能だし、Webクエリを使うと、表が大きくても問題ない。
ただ、MacではWebクエリを使えなさそうなので、Macユーザーはちょっと面倒だ。そこで、Pythonで動作するスクリプトを生成AI(今回はClaude 3.5 Sonnet)に作ってもらった。
まずは動作を紹介する。読み込むのは、Wikipediaに掲載されているGoogle Pixelの各機種の表だ。
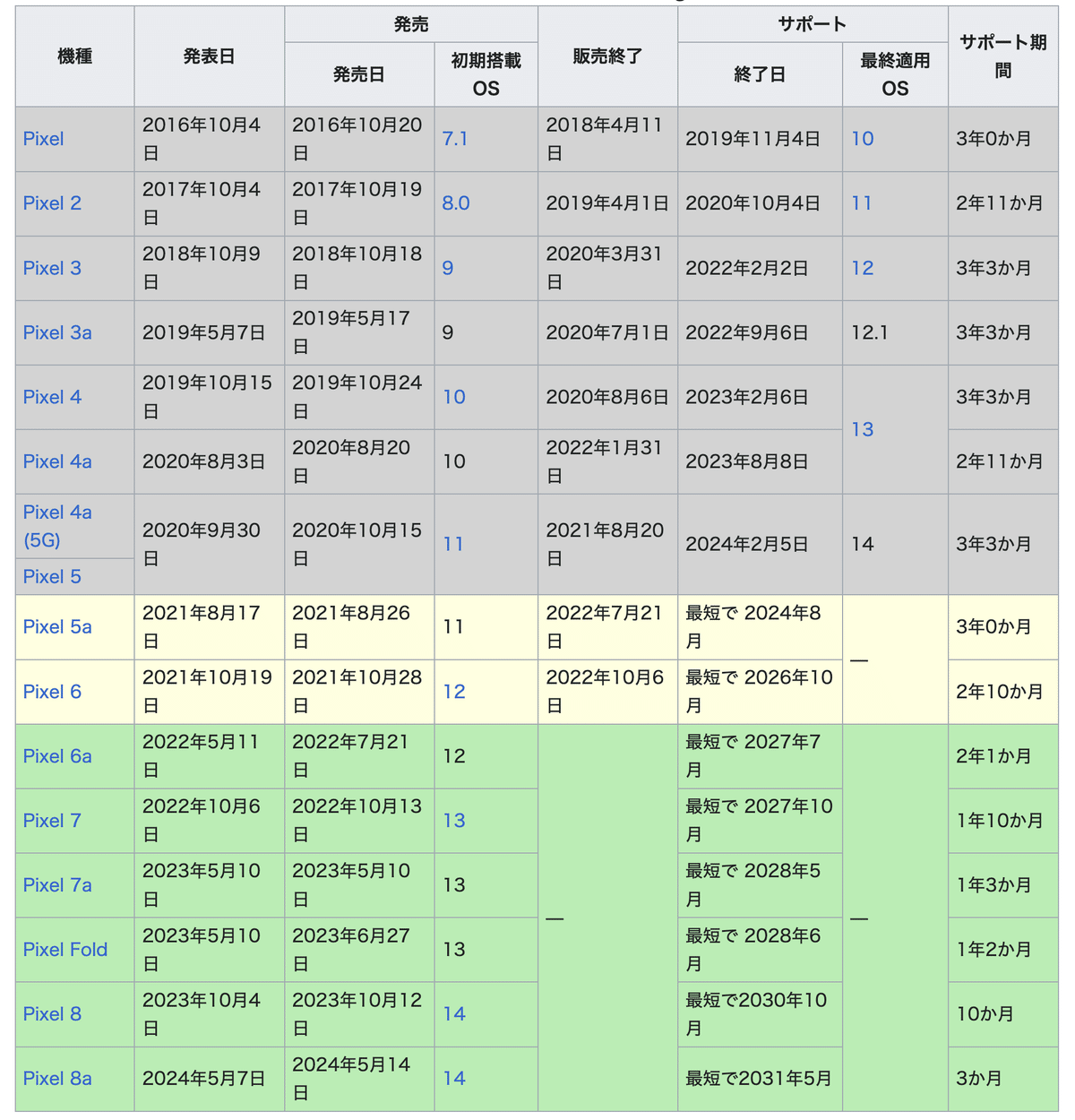
なお、この表自体は、コピペでExcelに貼り付けできるので、もしこの表を読み込みたいだけなら、Pythonを使う必要はない。
さて、スクリプトが出力したExcelファイルを開くと、以下のようになっている。
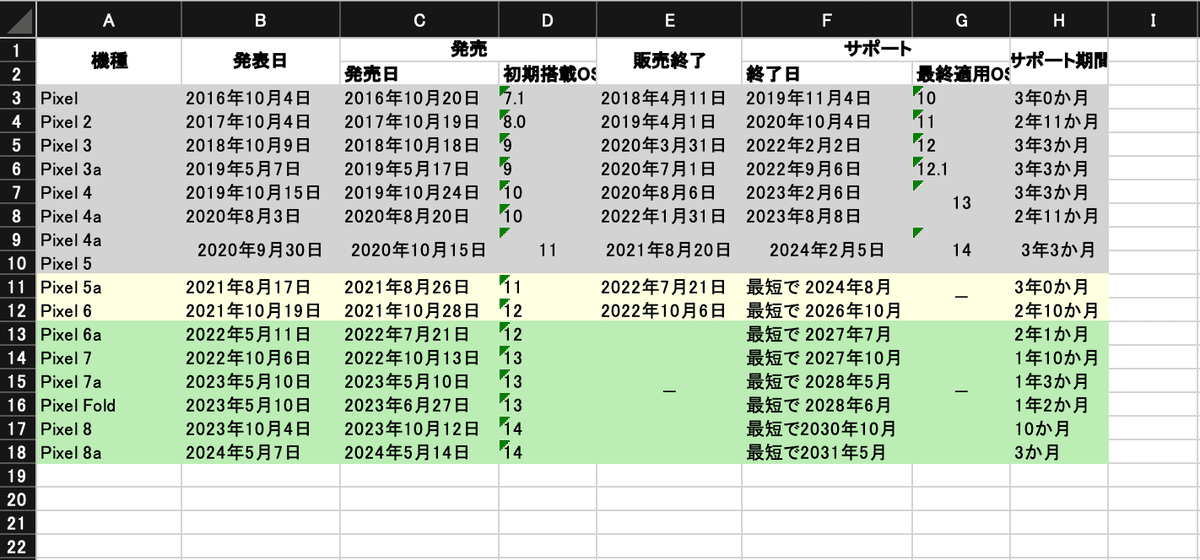
スクリプトの動作は、①スクリプト実行後にまず読み込み先のURLを入力する。URL入力後、ページ上の表組みの先頭部分のHTMLをずらっと並べてくれるので、そこから②目的の表を番号で選択する。あとは、③背景色を反映するかどうかを選択し(背景色を反映しない選択も可能)、④出力ファイルの名前を指定すればよい。
スクリプト本文は以下のとおり。
import requests
from bs4 import BeautifulSoup
import openpyxl
from openpyxl.utils import get_column_letter
from openpyxl.styles import Alignment, PatternFill
import re
import webcolors
def fetch_tables_from_url(url):
response = requests.get(url)
soup = BeautifulSoup(response.content, 'html.parser')
tables = soup.find_all('table')
if not tables:
raise ValueError("指定されたURLに表が見つかりませんでした。")
return tables
def clean_text(text):
text = re.sub(r'\[.*?\]', '', text)
text = re.sub(r'\d{19}♠', '', text)
text = re.sub(r'\s*\(.*?\)\s*$', '', text)
return text.strip()
def extract_background_color(cell):
# style属性から背景色を抽出
style = cell.get('style', '')
bg_color = re.search(r'background(-color)?:\s*(.*?)(;|$)', style)
if bg_color:
return bg_color.group(2).strip()
# bgcolor属性から背景色を抽出
bgcolor = cell.get('bgcolor')
if bgcolor:
return bgcolor
# tr要素のstyle属性から背景色を抽出
parent_tr = cell.find_parent('tr')
if parent_tr:
tr_style = parent_tr.get('style', '')
tr_bg_color = re.search(r'background(-color)?:\s*(.*?)(;|$)', tr_style)
if tr_bg_color:
return tr_bg_color.group(2).strip()
return None
def extract_table_data(table, include_background_color):
data = []
rows = table.find_all('tr')
max_cols = max(sum(int(cell.get('colspan', 1)) for cell in row.find_all(['th', 'td'])) for row in rows)
for row in rows:
cells = row.find_all(['th', 'td'])
row_data = []
for cell in cells:
colspan = int(cell.get('colspan', 1))
rowspan = int(cell.get('rowspan', 1))
value = clean_text(cell.text)
background_color = None
if include_background_color:
background_color = extract_background_color(cell)
row_data.append({
'value': value,
'colspan': colspan,
'rowspan': rowspan,
'is_header': cell.name == 'th',
'background_color': background_color
})
data.append(row_data)
return data, max_cols
def get_openpyxl_color(color):
if color is None:
return None
color = color.lower()
# 既知の色名をRGBに変換
color_map = {
'lightgrey': 'D3D3D3',
'lightgray': 'D3D3D3',
'd3d3d3': 'D3D3D3',
'lightyellow': 'FFFFE0',
'ffffe0': 'FFFFE0',
'lightgreen': '90EE90',
'#bbedb5': 'BBEDB5'
}
if color in color_map:
return color_map[color]
try:
# 色名をRGBに変換
rgb = webcolors.name_to_rgb(color)
return f'{rgb.red:02X}{rgb.green:02X}{rgb.blue:02X}'
except ValueError:
pass
# 16進数の色コードを処理
if color.startswith('#'):
color = color[1:]
# 3桁の16進数を6桁に拡張
if len(color) == 3:
color = ''.join([c*2 for c in color])
# 6桁の16進数を確認
if len(color) == 6 and all(c in '0123456789abcdef' for c in color):
return color.upper()
print(f"警告: 無効な色コード '{color}' が見つかりました。この色は無視されます。")
return None
def save_to_excel_with_merges(data, max_cols, output_file, include_background_color):
if not data:
raise ValueError("データが空です。")
wb = openpyxl.Workbook()
ws = wb.active
merged_cells = [[False for _ in range(max_cols)] for _ in range(len(data))]
for i, row in enumerate(data, 1):
col = 1
for cell_data in row:
value = cell_data['value']
colspan = cell_data['colspan']
rowspan = cell_data['rowspan']
is_header = cell_data['is_header']
background_color = cell_data['background_color']
while col <= max_cols and merged_cells[i-1][col-1]:
col += 1
if col > max_cols:
break
cell = ws.cell(row=i, column=col, value=value)
if is_header:
cell.font = openpyxl.styles.Font(bold=True)
if include_background_color and background_color:
fill_color = get_openpyxl_color(background_color)
if fill_color:
cell.fill = PatternFill(start_color=fill_color, end_color=fill_color, fill_type="solid")
if colspan > 1 or rowspan > 1:
ws.merge_cells(
start_row=i,
start_column=col,
end_row=i + rowspan - 1,
end_column=col + colspan - 1
)
cell.alignment = Alignment(horizontal='center', vertical='center')
for r in range(rowspan):
for c in range(colspan):
if i-1+r < len(merged_cells) and col-1+c < len(merged_cells[0]):
merged_cells[i-1+r][col-1+c] = True
col += colspan
for col in range(1, max_cols + 1):
max_length = 0
column_letter = get_column_letter(col)
for cell in ws[column_letter]:
try:
if len(str(cell.value)) > max_length:
max_length = len(cell.value)
except:
pass
adjusted_width = (max_length + 2) * 1.2
ws.column_dimensions[column_letter].width = adjusted_width
wb.save(output_file)
def main():
url = input("WebページのURLを入力してください: ")
try:
tables = fetch_tables_from_url(url)
print(f"{len(tables)}個の表が見つかりました。")
for i, table in enumerate(tables, 1):
print(f"表 {i}:")
print(table.prettify()[:200] + "...\n")
table_index = int(input("抽出したい表の番号を入力してください(1から始まる): ")) - 1
selected_table = tables[table_index]
include_background_color = input("背景色を反映しますか? (y/n): ").lower() == 'y'
table_data, max_cols = extract_table_data(selected_table, include_background_color)
output_file = input("出力するExcelファイルの名前を入力してください(例: output.xlsx): ")
save_to_excel_with_merges(table_data, max_cols, output_file, include_background_color)
print(f"表のデータが{output_file}に正常に保存されました。")
except Exception as e:
print(f"エラーが発生しました: {str(e)}")
if __name__ == "__main__":
main()もっと改造すれば、文字に貼られたリンクを反映したり、文字色を反映したりもできるだろう。