
いろいろなcloud watchアラームの使い方(1) - オートスケール

autoscale
まあやっぱりオートスケールやろ、今はタスクを手動で3つ4つに増やしたりして結果を見ていたが、これをアラームに応じて増やしてみよう。
現状

cpuが20%overになったら発動ってことにしてるんだけど、今実験が終わってサービスのタスクを0に落としているのでデーター不足になっている。まずタスクを1つupしていく


まだ自動スケーリング(要するにオートスケール)は何も設定していない。タスクの数を0→1にするので、そのうちデーターが貯まるはずだ。
その間に自動スケールの設定を眺めてみよう

このように最小と最大の入力ができる。もちろん最大はかなりの数を取る事もできるが、その分だけ課金はn倍になっていくだろう。
ターゲット追跡かステップスケーリングか
ここでは「アラーム」を基準にしているので、まずステップスケーリングにしてみよう。ターゲット追跡も余裕があれば記事にしたい。

そうすると、既存のアラームで先程作成しておいたcpu20overが選択できる。ポリシー名は適当につけよう。こおではcpu20overScaleとかした。

cpuが20%以上になるとタスクが1つ増える。しかしまだ20%を越えてる場合、どんどん増やす。

この「クールダウン」はタスクを増やす仕事をした後に待つ秒数でここでは60秒(1分)待つということにした。
アラームに戻る
さて、設定をしてる間にある程度データーが蓄積されたようだ

現状cpu負荷は5%いくかいかねえかって感じだな。

アクションも狙った感じになっているようだ。
locustを打ってみる
既に全開の計測においてとりあえずこのアプリは2ユーザーまでは20%いかないで耐えちゃうことがわかってるので今回は最初から3にする。



まちょっとラグがあるんだけど、このようにアラーム状態になった

すると、このように自動的にタスクが起動してくる
この後しばらく負荷をかけつづけてalermの状態を見てみると
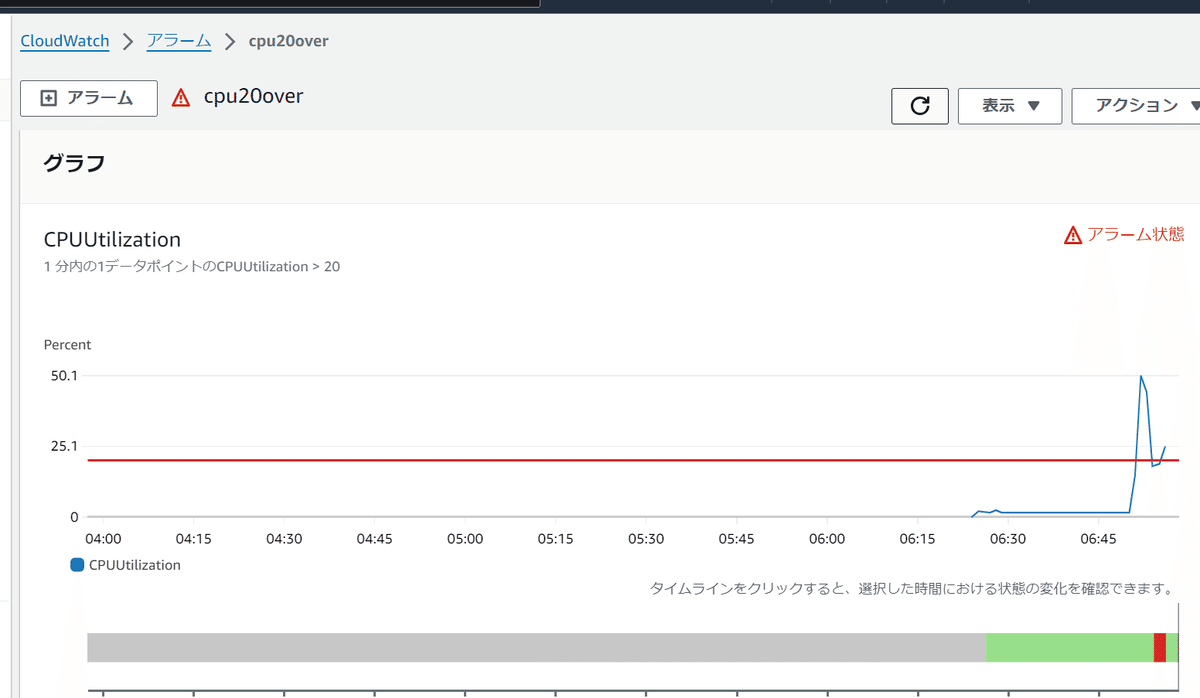
2つになったことでちょっと耐えたのだが、またアラームになっちゃった。そうすると…

クールタイムがあるから即座には起動しないのだが、タスクが3つになった。
これは予定通りの動作である。まあ暫く放置しておこう(放置しっぱなしてはいかんが…)

タスクが3つになったところで大体安定感が出てきたので停止した


スケールインしない問題

このようにlocustを停止したにもかかわらず

スケールイン(タスク減少)用のアラーム
何かヘンな感じといえばヘンな感じなんだけどスケールインイベントも用意しておかないとこれがうまいこと減らないんだな。まあ作ってみましょう。


これをcpu10lowとする

非常にアルアルな状態だけどcpu10%以下でアラームという事にしてるので常にどっちかのアラームが鳴ってるような状態になる。これはもうそういうもんなんだよね。

再度、テスト開始
タスクが2つになるのを何分か待つ。まあ今回は無事減るかどうかなので3つ4つってのはどうでもいい話だから2つに増えたらテストを終了しよう。

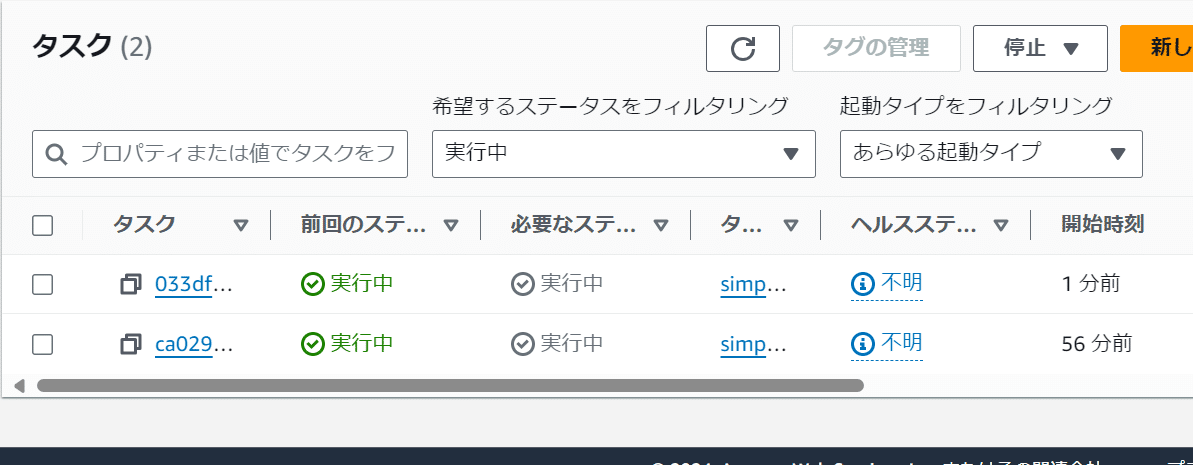
この辺でテストを中止し、しばらく待つ。

さて、このようになったらタスクの数を確認する

まあこれ基本的に最小タスクで設定したところまで落としていく事になるね。
次回は
lambdaでも書いてみますか。まあよくあるのはslack通知とか
この記事が気に入ったらサポートをしてみませんか?