
ChatGPT勉強日記(#5) LangChainを使って講義資料のベクターデータをPineconeへ保存する

前回、IDEOのHuman Centered Design (人間中心設計)の資料を元に質問に答えるAIを、OpenAIのEmbeddingsの機能を使って作成した。
Embeddingsで生成したベクターデータをpandaライブラリのDataFrameオブジェクトに保存して、そのデータから質問に一番近いものを取り出し、それをコンテキスト(文脈)として質問に答える仕組みを作った。
DataFrameは非常に便利で、大きくないデータで実験するにはもってこいの方法だが、実際になにかWebサービスでベクターデータを使いたい場合は、DataFrameに一時的に蓄えておくのではなく、半永久的にベクターデータを保存して使用する必要がある。
第3話でつかったSingleStoreはベクターデータもあつかえるSQLデータベースだが、純粋なベクターデータとしてPineconeがより広く使われているようなので、今回はPineconeを使ってデータを保存し、そのデータをつかって質問に解答すAIを作成する、という方法を学ぶことにした。
↓からPineconeのアカウントを作成し、プロジェクト -> Indexの順番で作成する。
Indexというのはひとまずリレーショナル・データベースでいうテーブルと同じ単位だという理解で、先に進んだ(もしかしたら間違っているかもしれない。)
始めは無料枠で、Indexを1つ作り、そこにベクターデータを保存しようとしたが、Pineconeへのリクエストが20秒に1回しか送れないので、それがかなり辛く、
一時的に付き70USDの有料会員になって先に進んだ。
Projectを作った後、Projectを開いて、Create Indexボタンを押すと、下のようなIndex作成画面が出てくる。

リージョンはGCPの日本のインスタンスを選択し、DimentionはEmbeddingで生成されたベクターデータが1536次元のため、1536と入力した。
Metrics(Distance Metrics)はベクターどうしの距離を計算するときに何を使うかを指定する箇所である。
cosine (コサイン類似度), dotproduct(ドット積), euclidean(ユークリッド距離)から選ぶ。
Open AI公式のチュートリアルではcosine (コサイン類似度)を使っていたので、おなじcosineを選択。
各距離計算手法の特性の違いについても後日調べてみようと思う。
Pod Typeはs1, Post Count, Replica Countはそれぞれ1,Pod Sizeはx1とした。おそらく一番低いスペックのつもりで選択したがこのあたりは各オプション、値の特性を詳しくわかってないので、これも後で調べようと思う。
Indexを作成すると、Indexesのメニューの下に下のようにIndexが出来上がる。
このIndexの名前と、リージョンの名前(asia-northeast1-gcp)が後に必要になるのでメモっておく。

また、上のプロジェクト画面のメニューの下に、API Keysというメニューがある、ここをクリックして開くと、API Keyが書いてあるので、これもメモしておく。
ここまでで、Pineconeの設定は終わった。
次にJupyter Notebookでプロジェクトを作る。

pdfフォルダの下は前回と同じ用に、IDEOのHuman Centered Designの講義資料を配置。

constants.ipynbに下のように、環境変数をセットする。
%env OPENAI_API_KEY=<OpenAI APIのAPI_Key>
%env PINECONE_API_KEY=<先程メモしたPineconeのAPI_Key>
%env PINECONE_INDEX_REGION=asia-northeast1-gcp
%env PINECONE_INDEX_NAME=hcd-embeddings
%env CHAT_MODEL_NAME=text-davinci-003
data.ipynbの下に、データをPineconeに入れるコードを
search.ipynbの下に、質問に解答するAIのコードを書いていく。
data.ipynb
まず先程のconstants.ipynbとprint_helpers.ipynbを先に実行しておく。(print_helpers.ipynbはただログを見やすく出力する関数なので、内容は割愛します。)
%run constants.ipynb
%run print_helpers.ipynb
次に必要なものをimport
import os
from tqdm.autonotebook import tqdm(tqdmはJupyter Notebookの警告を回避するためだけにimportしています。本質的に必要なライブラリではありません)
次にLangChainをつかって、文字列を指定したトークンサイズに収まるように文章を分割し、文字列のアレイを生成する関数(split)を作成
from langchain.text_splitter import TokenTextSplitter
# Constants
NUMBER_OF_TOKENS=1000
NUMBER_OF_TOKENS_OVERLAP=200
def split(data_string):
text_splitter = TokenTextSplitter(chunk_size=NUMBER_OF_TOKENS, chunk_overlap=NUMBER_OF_TOKENS_OVERLAP)
texts = text_splitter.split_text(data_string)
return textsNUMBER_OF_TOKENはトークンサイズ
NUMBER_OF_TOKENS_OVERLAPはオーバーラップする文字のトークンサイズである。
前回第4話では、原始的なコードで文章を500トークンずつぶつ切りにした。
この作業はLangChainを使えば3行ですんでしまうので非常に楽である。
前回は500トークン分ずつ、ばっさり切っていったが、LangChainにはchunk_overlapという機能(パラメータ)があり、文章を切って、次のチャンクに行くときに、前のチャンクの後ろのほうの文字列も次のチャンクに入れることができる。
これは500や2000トークンの切れ目が必ずしも意味的な文章の切れ目とは限らないので、前回のやり方では、意味のある1つの文章が途中で切られ、2つのトークンに分離する、ということも起きているはずである。
chunk_overlapを使うと、チャンクの後ろの単語が次のチャンクにも入るのでチャンクが意味的な文章の塊を持つ可能性(=チャンクが文章の意味をぶった切ってしまわない可能性)を高める効果があるのだろうと思った。
詳しくはまたLangChainの公式ドキュメントを読んで後で勉強してみようと思う。
次にいよいよ、チャンクをEmbeddingsでベクターデータにし、Pineconeに保存していく処理を書いていくため、pineconeとLangChainのPineconeクラス、OpenAIEmbeddingsクラスをインポートする。
from langchain.vectorstores import Pinecone
from langchain.embeddings.openai import OpenAIEmbeddings
import pineconeつぎに、OpenAIEmbeddingsのインスタンスを作成し、pineconeを初期化する。
# Initialize OpenAI Embedding
embeddings = OpenAIEmbeddings(openai_api_key=os.environ['OPENAI_API_KEY'])
# Initialize Pinecone
pinecone.init(api_key=os.environ['PINECONE_API_KEY'], environment=os.environ['PINECONE_INDEX_REGION'])ここで、さきほどconstants.ipynbに設定したOpenAIやPineconeのAPI_KEY、REGIONを使う。
次に、先程作ったチャンク(文字列のアレイ)ともとのPDFのファイル名を渡すと、チャンクのデータからベクターデータを生成してPineconeに保存する関数、SaveVectorToPinecone()を作成した。
def SaveVectorToPinecone(texts, filename):
Pinecone.from_texts(texts, embeddings, metadatas=[{'chunk': index, 'file': filename} for index, _ in enumerate(texts)], index_name=os.environ['PINECONE_INDEX_NAME'])LangChainのPineconeクラスのfrom_texts()メソッドを呼ぶだけでこれだけの作業をしてくれるのが驚きである。
このメソッドには4つのパラメータを渡している。
1つめは、textsで、先程Langchainで作った文字列のアレイ、
2つ目は先程つくったLangChainのOpenAIEmbeddingsのインスタンスであるembeddings、
3つめはPineconeに渡すメタデータ。
metadatas=[{'chunk': index, 'file': filename} for index, _ in enumerate(texts)]今回各ベクターデータと一緒に元の文章のファイル名と、チャンク番号(何個目のチャンクか)を保存することにした。
4つ目のパラメータは、index_name、つまりPoneconeのIndex名である。
index_name=os.environ['PINECONE_INDEX_NAME']これで必要な関数はすべて揃ったので、pdfフォルダの下のファイルを1つずつ読み込んで、テキストデータを取り出し、それを、SaveVectorToPinecone関数に渡すコードを書いて実行した。
import PyPDF2
import os
pdf_dir = 'pdf'
# Iterate over every file in the pdf directory
for filename in os.listdir(pdf_dir):
if filename.endswith('.pdf'):
with open(os.path.join(pdf_dir, filename), 'rb') as file:
pdf_reader = PyPDF2.PdfReader(file)
content = ''
number_of_pages = len(pdf_reader.pages)
for page_num in range(number_of_pages):
content += pdf_reader.pages[page_num].extract_text()
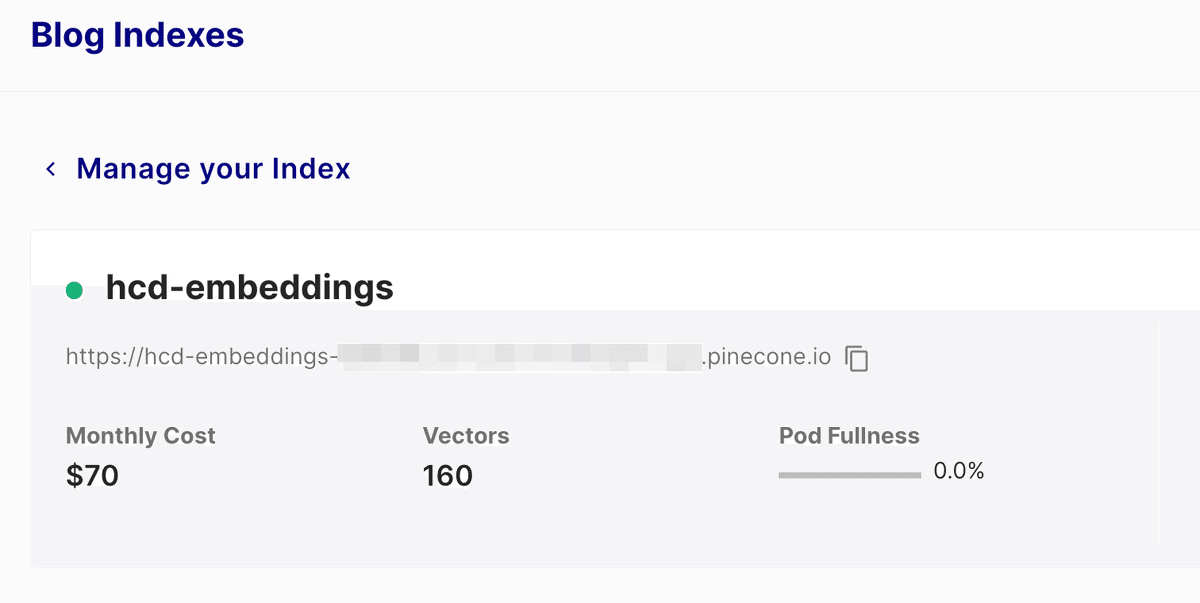
SaveVectorToPinecone(split(content), filename) 実行後、Pineconeのコンソールで、hcd-embeddingsインデックスを開くと、160個のベクターが保存されたことが確認できた。
前回と比べてほぼ同じ目的の処理がLangchainを使うことでこんなにも簡単に書けてしまうことが驚きだった。最初Langchainなんて必要なのかなと思ったけど使われている意味が良くわかった。
これでベクターデータベースができたので、次回はこのデータベースをつかって質問に近いコンテキストを取り出し、そのコンテキストをもとにChatGPTのモデルに質問に答えさせる部分を作って行きたいと思う。
続く
このブログに関する質問や、OpenAI APIをつかったWebサービス、Android・iOSアプリの開発の相談はこちら↓↓↓からお願いします!
@mizutory
mizutori@goldrushcomputing.com
次回は↓↓↓
この記事が気に入ったらサポートをしてみませんか?