SAM(Segment Anything Model)を用いた画像分析の解説

初めまして、みずぺーといいます。
このnoteを機に初めて私を知った方のために、箇条書きで自己紹介を記述します。
年齢:28歳
出身:長崎
大学:中堅国立大学
専門:河川、河川計画、河道計画、河川環境
転職回数:1回(建設(2年9か月)→IT系年収100万up(現職3か月))
IT系の資格:R5.4基本情報技術者試験合格💮、R5.5G資格
本日はSAMに関して解説します!この一つ前の記事ではZERO-SHOT-DETECTIONを開設しましたが、その延長です。
SAMの概要
上記の記事の内容を話していければなと思っております。
概要を日本語で訳しますと
1100万枚の画像に10億をこえるマスクを使用
既往最大のセク面テーションデータセットを構築
これまでのモデルよりもゼロショットのパフォーマンスと同等かそれ以上の結果を得られた
となってます。
SAM
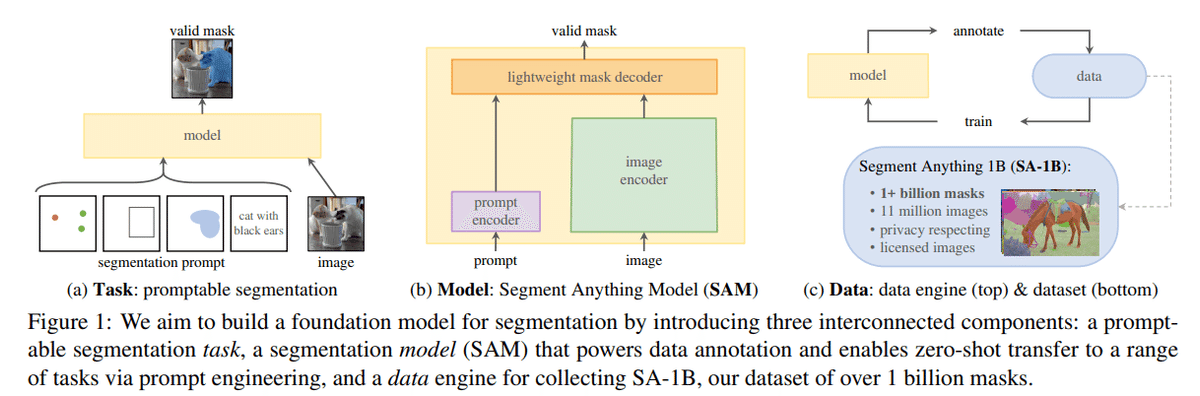
(a)は画像とセグメントしたい種類(点、BBox、インスタンス、文章)
(b)は画像、文章を入力するとエンコードで特徴量を抽出してマスクに戻してくれる
(c)はその繰り返しでdataを入れてmodelにトレーニング。そのセグメント結果を利用して1億のマスクを取得
SAMのゴール
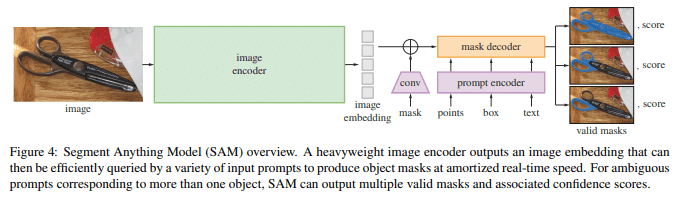
ここは画像から勝手に順番を私が付けております。(間違ってる可能性があるので参考として見ていただけたら)
入力画像から特徴量を抽出
特徴量をベクトル空間に配置
プロンプト(点、bbox、文章)を入力しそこから特徴量を抽出
maskをconv層に入れてmaskするための材料を作成??
mask decoderで画像に戻し、プロンプトと一致したところにマスクを作成
1つでは心細いから3つ作成
特に4は自信ないです。

上記の画像はSAMの出力結果です。
画像上に点を一つだけ打つと、三つの画像が出力されます。
三つ出力される理由は「あいまいなプロンプトへの対応」だそう。
右の画像はZのロゴ、もしくは壁面を指しているかわかりませんからね。

上記の画像はSAMモデルでエッジ検出を行っている様子です。
何も学習してなくても、エッジ検出を可能な様子が伝わってくるかと思います。
SAMを触ってみた
前準備
colabへのマウント
from google.colab import drive
drive.mount('/content/drive')
%cd /content/drive/MyDrive/ColabNotebooks/segmentation_anythingファイルをインストール
!git clone https://github.com/facebookresearch/segment-anything.git
%cd segment-anythingライブラリのインストール
!pip install -e .
!pip install opencv-python pycocotools matplotlib onnxruntime onnxサンプル画像のインストールのためのフォルダ作り
import os
os.makedirs("/content/drive/MyDrive/ColabNotebooks/segmentation_anything/segment-anything/checkpoint", exist_ok=True)
os.makedirs("/content/drive/MyDrive/ColabNotebooks/segmentation_anything/segment-anything/images", exist_ok=True)サンプル画像のインストール
!wget -P images https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/truck.jpg
!wget -P images https://raw.githubusercontent.com/facebookresearch/segment-anything/main/notebooks/images/groceries.jpg
!wget -P checkpoint https://dl.fbaipublicfiles.com/segment_anything/sam_vit_h_4b8939.pth実装
関数の定義
import numpy as np
import torch
import matplotlib.pyplot as plt
import cv2
def show_mask(mask, ax, random_color=False):
if random_color:
color = np.concatenate([np.random.random(3), np.array([0.6])], axis=0)
else:
color = np.array([30/255, 144/255, 255/255, 0.6])
h, w = mask.shape[-2:]
mask_image = mask.reshape(h, w, 1) * color.reshape(1, 1, -1)
ax.imshow(mask_image)
def show_points(coords, labels, ax, marker_size=375):
pos_points = coords[labels==1]
neg_points = coords[labels==0]
ax.scatter(pos_points[:, 0], pos_points[:, 1], color='green', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
ax.scatter(neg_points[:, 0], neg_points[:, 1], color='red', marker='*', s=marker_size, edgecolor='white', linewidth=1.25)
def show_box(box, ax):
x0, y0 = box[0], box[1]
w, h = box[2] - box[0], box[3] - box[1]
ax.add_patch(plt.Rectangle((x0, y0), w, h, edgecolor='green', facecolor=(0,0,0,0), lw=2))サンプル画像の読み込み及び表示
以下のコードを入れて表示します。
image = cv2.imread('images/truck.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
plt.figure(figsize=(10,10))
plt.imshow(image)
plt.axis('on')
plt.show()
SAMを使ってオブジェクトを選択する
import sys
from segment_anything import sam_model_registry, SamPredictor
sam_checkpoint = "checkpoint/sam_vit_h_4b8939.pth"
model_type = "vit_h"
device = "cuda"
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
predictor = SamPredictor(sam)SamPredictor.set_imageを呼び出して画像を処理し、画像埋め込みを生成します。
SamPredictorはこの埋め込みを記憶しており、その後のマスク予測に使用します。
predictor.set_image(image)トラックを選択するにはトラック上の点を選択します。
ここではラベルは1(前景点)または0(背景点)です。
今回は一つの点を選択してみましょう。
input_point = np.array([[500, 375]])
input_label = np.array([1])plt.figure(figsize=(10,10))
plt.imshow(image)
show_points(input_point, input_label, plt.gca())
plt.axis('on')
plt.show() 
マスク画像の選択
multimask_output=Trueを選択することでSAMは3つのマスクを出力することができます。
masks, scores, logits = predictor.predict(
point_coords=input_point,
point_labels=input_label,
multimask_output=True,
)次の下記のコードを入力すると
masks.shape # (number_of_masks) x H x W(3, 1200, 1800)
上記の結果が返ってきました。
結果の出力
for i, (mask, score) in enumerate(zip(masks, scores)):
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(mask, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.title(f"Mask {i+1}, Score: {score:.3f}", fontsize=18)
plt.axis('off')
plt.show()結果が以下の画像になります。



特定のオブジェクトを追加の点で指定する
input_point = np.array([[500, 375], [1125, 625]])
input_label = np.array([1, 1])
mask_input = logits[np.argmax(scores), :, :] # Choose the model's best maskmasks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
mask_input=mask_input[None, :, :],
multimask_output=False,
)masks.shapeこの結果、
(1, 1200, 1800)
が返ってきます。最初の1のところは今回のセグメンテーションを行った画像を1つしかないことを表しています。
plt.figure(figsize=(10,10))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()このように二つの点を指定することによって画像をセグメントすることができました。

追加の点を別のものとして識別させる
input_point = np.array([[500, 375], [1125, 625]])
input_label = np.array([1, 0])
mask_input = logits[np.argmax(scores), :, :] # Choose the model's best mask
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
mask_input=mask_input[None, :, :],
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()この結果違う種類の点が出てきたため、車はセグメンテーションされていません。

ボックスを使用した特定のオブジェクトの指定
input_box = np.array([425, 600, 700, 875])
masks, _, _ = predictor.predict(
point_coords=None,
point_labels=None,
box=input_box[None, :],
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
plt.axis('off')
plt.show()ボックスを用いてセグメンテーションを行うことも可能です。

ボックスと点を指定したセグメンテーション
input_box = np.array([425, 600, 700, 875])
input_point = np.array([[575, 750]])
input_label = np.array([0])
masks, _, _ = predictor.predict(
point_coords=input_point,
point_labels=input_label,
box=input_box,
multimask_output=False,
)
plt.figure(figsize=(10, 10))
plt.imshow(image)
show_mask(masks[0], plt.gca())
show_box(input_box, plt.gca())
show_points(input_point, input_label, plt.gca())
plt.axis('off')
plt.show()上記のコードを作成することで車のタイヤの中のホイールとそうでない部分もセグメントを細かく分けることが可能です。

SAMの根幹であるCLIP
今回はセグメンテーションの一つであるSAMを解説するとともに、実装も行いました。
現在はSAMの技術の根幹となっているCLIPの記事のを投稿しております。
今後も画像解析や画像生成に関わるAI技術を発信していきます。
もし参考になったと言う方がいましたら、私の記事執筆の励みになりますのでスキボタンと登録よろしくお願いいたします。
この記事が気に入ったらサポートをしてみませんか?