
【2/25-3/3】生成AIツール/研究-Weeklyまとめ

今週のAIに関するツールや研究情報をまとめた記事です。
ツール
・AIアプリ制作者用に、信頼性を検証し向上させるツール、Critique
・チャット検索のNeevaAIが、マルチパースペクティブAIなるものを紹介
色んなソースと観点から結果を確認でき、好みに合わせて特定のトピックをより把握できるとのこと。Bias Buster スライダーを動かすと、AI の回答を変更できる。
https://neeva.com/blog/neevaai-bias-buster
With multi-perspective AI, you'll be able to see results from a variety of sources and perspectives, providing a more complete picture of any given topic custom to your preferences.
— sridhar (@RamaswmySridhar) February 24, 2023
Now, when you move our Bias Buster slider, the AI answer changes.
Here's an example ⤵️ pic.twitter.com/pzspBE1KbL
・Landbot AI ノーコードでGPTチャットボットをWhatsApp、Web、または Messengerに構築できる
リードの生成、プロセスの自動化、キャンペーンの開始、質の高いカスタマー サービスの提供が可能 lineがline公式チャットの機能の一つとしてやってきそう
https://landbot.io/ai


・@aivtuber_zero さんが誰でもキャラクターAIが作れるサービスを開発
属性・声などをテキスト入力するだけで、誰もが簡単にオリジナルのキャラAIを生成可能。
誰でもキャラクターAIが作れるサービスを開発しました。
— キカイ / AITuber 生成研究所 (@aivtuber_zero) February 26, 2023
属性・声などをテキスト入力するだけで、誰もが簡単にオリジナルのキャラAIを生成できます。#AIart #AIVtuber #AItuber pic.twitter.com/6hQCAV1HmZ
・GPTなどを利用したAppleショートカットマーケットプレイス
スプレッドシート自動補完や文章整形など様々なGPTショートカットを売買できる コミュニティも運営していくとのことで、この場所であらゆるプロンプトツールを集約させていこうとしてそう
http://promptplays.ai
・GPT3 とコンピューター ビジョンを使用した Chrome のRPA
CRM 統合、請求書の提出、電子メールへの返信、会議メモの要約などなど https://getlassoai.com

・Kraftful: ユーザーからのフィードバックをAIで分析
https://kraftful.com
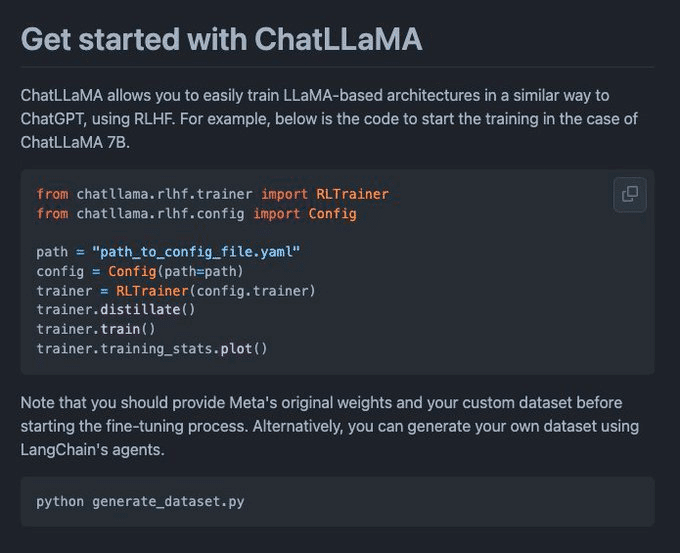
・ChatLLaMA - RLHF をベースにした LLaMA のオープンソース実装
ChatGPTより15倍速い学習プロセスを主張している。また、ChatLLaMAのアシスタントをカスタマイズすることができる。
https://github.com/nebuly-ai/nebullvm/tree/main/apps%2Faccelerate%2Fchatllama…
・QuoraのPoeをリバースエンジニアリングしたAPIだそう
AnthropicのClaudeにターミナルでアクセスしてる
http://github.com/vaibhavk97/Poe

・Snapchat が AI チャットボットのMyAIをリリース
https://theverge.com/2023/2/27/23614959/snapchat-my-ai-chatbot-chatgpt-openai-plus-subscription…
🚨BREAKING: Snapchat is joining the AI chatbot frenzy.
— Rowan Cheung (@rowancheung) February 27, 2023
Snapchat released their new AI feature, 'My AI,' that runs on OpenAI's latest version of GPT.
You can talk to My AI similar to ChatGPT, PLUS you can:
-Give it a name
-Customize the wallpaper for your Chat. pic.twitter.com/1dmbZUEKMI
・huggingfaceで、画像を編集等されないように免疫化するデモが公開
自分の画像を免疫化し、画像を編集してみることでどうなるかチェックできる
https://huggingface.co/spaces/hadisalman/photoguard…
ブログ: http://gradientscience.org/photoguard/
論文: http://arxiv.org/abs/2302.06588
github: https://github.com/MadryLab/photoguard
A @huggingface demo for our image immunization paper is out! You will be able to:
— Hadi Salman (@hadisalmanX) February 27, 2023
- edit your images
- check what immunizing your images would do to these edits!
w/ @Alaa_Khaddaj @gpoleclerc @andrew_ilyas @aleks_madry https://t.co/9Nnensn6J2 https://t.co/XgvEGjLG5s pic.twitter.com/pwV66FOuux
・langchain AGIハッカソンで1位を取ったLife Copilot テキストと画像を理解し、ブラウザ処理を自動化する@MultiON_AIを使い、最適な提案や処理を代行するAIアシスタント
動画は、サラダ画像をアップし、そのサラダのデリバリー注文を自動代行
他事例はスレッド)
これは欲しい!(まだ)
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) February 28, 2023
作りたいこれ
langchain AGIハッカソンで1位を取ったLife Copilot
テキストと画像を理解し、ブラウザ処理を自動化する@MultiON_AI
を使い、最適な提案や処理を代行するAIアシスタント
動画は、サラダ画像をアップし、そのサラダのデリバリー注文を自動代行
他事例は続) https://t.co/ssvkixaWFU pic.twitter.com/XdIpVbkqIq
・TikTokに手をかざしてもフィルターが外れない「Beauty filter」
— memo akten (@memotv) February 26, 2023
・テキストto UIデザインのGalileo AI
アーリーアクセス: https://usegalileo.ai
テキストto UIデザインのGalileo AI
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) February 28, 2023
アーリーアクセス: https://t.co/ATxVKGm9st pic.twitter.com/sgaREIbAY6
・テキストから3Dキャラクター生成
waiting list: https://forms.office.com/Pages/ResponsePage.aspx?id=DQSIkWdsW0yxEjajBLZtrQAAAAAAAAAAAANAAUIQFilUNjNGM0NLUUhEUEkxVlRFTkw0OVA3NzlVNS4u
Say hello to #ChatAvatar - part of our #Hyperhuman platform,the game changing text-to-3D character creation tool powered by Generative AI.
— Deemos Tech (@DeemosTech) February 26, 2023
Combined with @OpenAI, #ChatAvatar has never been more powerful.
Join waiting list now:https://t.co/2o3zClc7NT#AIGC #ChatGPT #TextTo3D pic.twitter.com/8F6fsyqC1H
・人の写真をアップロードすると、AI がインターネット上のすべての同じ顔画像を見つけるサイト
https://pimeyes.com/en
The most disturbing AI website on the internet.
— Rowan Cheung (@rowancheung) February 28, 2023
Upload a photo of a person, and AI will find ALL of the images of that person across the internet. pic.twitter.com/ac6A1xRxQi
・adsai はヘルプデスクやカスタマーサポート向けの動くマニュアルをクリックするだけで作成できるツール「secondz」を日本市場向けにローンチ
今後、ChatGPT などと組み合わせ、ユーザと対話的にやり取りできるツールへと進化させる計画。
https://thebridge.jp/2023/03/adsai-officially-launches-seconds-for-japan…
・ChatCAD:レントゲンなどの医療画像から自動診断した症状をチャット形式で教えてくれるシステム
言語モデルとCAD(コンピュータ検出/診断支援)ネットワークの組み合わせ 医療画像を3つのAI(画像分類、病変セグメンテーション、報告書生成)に送り込み、レポート生成AIが診断報告書を作成、GPTが編集する
https://www.itmedia.co.jp/news/articles/2303/01/news070.html


・Uizard Screenshotってツールで、スクショ画像を編集可能なモックアップに変換できるらしい
つまり、好きなアプリ、ウェブサイト、独自のソフトウェアの画面をスクショして、アップロードするだけで、その画面を編集したり、新しいプロジェクトを開始できる
https://uizard.io/blog/uizard-screenshot-convert-screenshots-to-mockups/…
なんだこれ!
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) March 1, 2023
Uizard Screenshotってツールで、スクショ画像を編集可能なモックアップに変換できるらしい
つまり、好きなアプリ、ウェブサイト、独自のソフトウェアの画面をスクショして、アップロードするだけで、その画面を編集したり、新しいプロジェクトを開始できるhttps://t.co/2NTenwV1I1 https://t.co/ISUZR4sHH8 pic.twitter.com/oBgPbLkPbV
・Uizardの手書きのワイヤーフレームスキャナー機能
手書きのワイヤーフレーム画像を編集可能なデジタルワイヤフレームにすばやく変換 企画者さんの細かいイメージを、爆速で表現できるようになった
https://uizard.io
Hand-drawn wireframe 🤝 Uizard's scanner feature
— uizard ✨ (@uizard) February 21, 2023
Check out how you can quickly turn a drawing into a digital, editable wireframe using Uizard ✨
See the magic for yourself here: https://t.co/ikYymOWtOv#uizard #aidesign #aitools #designtools pic.twitter.com/stQCYJibHU
・PortfolioPilot Insights 何百万ものマクロ経済関係をくまなく調べて、純資産に影響を与える洞察を自動的に生成
https://portfoliopilot.com/?utm_source=producthunt&utm_campaign=insightslaunch

・仕事用のSlack AI検索アシスタントDashworks Slack
チャンネルに追加するだけで、Wiki、チャット、その他の仕事用アプリに埋もれている情報から質問に応答
https://dashworks.ai/for-slack

・ChatGPTをLINEで使えるサービス
http://lin.ee/rnlquLs

・セールス Co-PilotのGoldie
Goldieは、ベストプラクティスを提案し、あなたに代わって営業を実行することで、より短時間でより多くの案件を成約することができるツール
まだ未公開:
・stablediffusion用の新しい Blender プラグイン
ツール内でテクスチャ、ビデオなどを生成できる。
無料でダウンロード: https://platform.stability.ai/docs/integrations/blender…
Generative art meets 3D - use our new Blender plugin for #stablediffusion to generate textures, videos and more, right inside the tool you already know. Download for free here: https://t.co/mvw9UOJq68 pic.twitter.com/FzUa1B71q1
— Stability AI (@StabilityAI) March 2, 2023
・SnapChatのMinecraftレンズだそう
AR で 現実世界 x Minecraftができる。スティーブのように掘ったり、戦ったり、建てたり https://lens.snapchat.com/0d8bfe42b05849648c0eea39a99801e3?utm_source=Lens_Creator_Email
I remade Minecraft in AR so you can dig, fight, and build like Steve but in the real world!! pic.twitter.com/YEOMiUIPBF
— aidan (@Aidan_Wolf) February 14, 2023
・perplexity拡張機能でサイト要約もできるようになってた
閲覧しているニュース、記事、論文に対してワンクリックで要約したり、テキストでQAできるとのこと。色んなAIツールがこれ一本でよくなってる。
https://chrome.google.com/webstore/detail/perplexity-ask-ai/hlgbcneanomplepojfcnclggenpcoldo
Get to the heart of any article with Perplexity's new one-click summaries! Whether you’re browsing news, articles, or papers, instant answers are just one click away. 📚
— Perplexity AI (@perplexity_ai) March 2, 2023
Available on our Chrome extension now:https://t.co/NO0w2q3PjN pic.twitter.com/r6QRwuPBdt
・ChatGPTを搭載した栄養アシスタントNaraがリリース
好みに合わせた新しいレシピ、外食オプション、フードデリバリーのおすすめを24時間365日パーソナライズして提案してくれる yconのW22にも参加 やってみたけどプロンプトが仕込まれてるって感じ。
https://trynara.com

・roomGPTの発表
AIで部屋を数秒でデザインし直そすことができる無料ツール
リリースから12時間で
◆ 14,000 ルームが生成
◆ 10,000 人のユニークユーザー
◆ 400のGitHub スター
◆ かかったモデル推論代224 ドル
http://roomgpt.io
Announcing roomGPT!
— Hassan El Mghari (@nutlope) March 2, 2023
Redesign your room in seconds with AI! 100% free and open source.https://t.co/VuseUvF4kJ pic.twitter.com/LOL8qVVmJm
研究
・Metaが7B から 65B パラメータまでの 4 つの基盤モデル LLaMA をリリース
LLaMA-13B は、ほとんどのベンチマークで OPT および GPT-3 175B よりも優れている。 LLaMA-65B は、チンチラ 70B および PaLM 540B と競合
商用利用は禁止
・Composer: 数十億の(テキスト、画像)ペアで学習した大規模(50億パラメータ)な制御可能な拡散モデル
github: https://github.com/damo-vilab/composer…
paper: https://arxiv.org/abs/2302.09778
project: https://damo-vilab.github.io/composer-page/

・基盤LLMを開発するのにかかった費用
Facebookの65B LLaMA: 合計約5億円
2048個のNvidia A100 GPUで21日間学習。(GCPが1時間3.93ドルとして)
Googleの540B PaLM: 合計約37億円
6144 v4 TPUで1200時間学習。(1時間あたり3.22ドルとして)
・プロンプトを変えることで画像を編集
https://huggingface.co/spaces/kadirnar/prompt-to-prompt_stable-diffusion

・ChatGPTは弁護士の代わりになるか? 「カタツムリ混入ビール事件」の判例で香港の研究チームが検証
研究チームは、総合的には有能な訴訟弁護士ほど高度ではなく、ChatGPTが作成する草稿や研究作業は法学部の1年生ほどと考察 (あくまでChatGPTは)
・外部の知識と自動化されたフィードバックを使用して大規模な言語モデルを改善
言語モデルに、例えばタスク特化DBに格納された外部知識に基づく応答を生成させ、プロンプトを繰り返し修正し、応答の事実性スコアなどをもとにしたフィードバックを用いて、モデルを改善
論文: https://arxiv.org/abs/2302.12813
・ELITE 高速かつ正確なカスタマイズされたテキストから画像への合成のための、新しい学習ベースのエンコーダ
0.05sでDreamboothてきなことができる画像生成。
論文: http://arxiv.org/abs/2302.13848
github(まだ何もない): https://github.com/csyxwei/ELITE


・FedCLIP: 連合学習におけるCLIPのための高速な汎化・個別化
abs: http://arxiv.org/abs/2302.13485

・Internet Explorer クエリを使用しネットの画像検索、ダウンロードした画像の自己監視トレーニング、有用な画像の判断、次に検索する画像の優先順位付けを繰り返し、タスクに寄与するデータで学習
1 つのGPUのみを使用して30,40時間クエリを実行することで、CLIP oracleを上回るか、同等まで。
Internet Explorer
— 納村 聡仁 / Osamura Akinori (@akinoriosamura) February 28, 2023
クエリを使用しネットの画像検索、ダウンロードした画像の自己監視トレーニング、有用な画像の判断、次に検索する画像の優先順位付けを繰り返し、タスクに寄与するデータで学習
1 つのGPUのみを使用して30,40時間クエリを実行することで、CLIP oracleを上回るか、同等まで。 https://t.co/vTgTBufsHW pic.twitter.com/aS1PoBGRj5
・KOSMOS-1、マルチモーダル入力を認識し、指示に従い、マルチモーダル タスクのコンテキスト内学習を実行できるマルチモーダル言語モデル
画像を元に対話したり、ビジュアルIQテストに合格したり、コンテンツの画像を分析したりなど
https://arxiv.org/abs/2302.14045

・与えられたテキストスクリプトと顔画像から音声を生成
顔でなんとなく声を想像できるよね、というところから着想
abs: https://arxiv.org/abs/2302.13700
プロジェクト: https://facetts.github.io

・CoH: chain of hindsight 「次の要約は悪い」など、比較の形で正と負の両方のフィードバックで構成される文を作成し学習
要約および対話タスクでは、SFT、RLHFより精度向上
Paper: https://arxiv.org/abs/2302.02676
Code: https://github.com/lhao499/CoH


・画像生成AIの高品質なプロンプトを盗む攻撃の検証と防御策の提案
生成画像が与えられたとき、対応するプロンプトを推測することができるのかという課題に対し画像からプロンプトを盗む攻撃を検証 PromptShieldと呼ぶプロンプトを適切に推測できないように攻撃を防ぐ手法も提案
https://itmedia.co.jp/news/articles/2303/01/news071.html


・100倍少ないデータ量と計算量でOpenAI CLIPを打ち負かしたそうな
データセット:fliker, mscoco
タスク:ゼロショット画像検索
ブログ:https://unum.cloud/blog/2023-02-20-efficient-multimodality…
huggingface: https://huggingface.co/unum-cloud/uform…
github : https://github.com/unum-cloud/uform…

・Vid2Seq:高密度ビデオキャプションのための視覚言語モデルの大規模な事前学習
論文: https://arxiv.org/abs/2302.14115

・複数の画像素材からうまくフィットするようにコラージュする Collage Diffusion
論文:https://arxiv.org/abs/2303.00262

・自然言語でドローンを動かす
MSの公開してるChatGPTでRobot制御するやつ、普通に動く。しかも日本語でもやりとりできる。これはやばい。
— Akira Sasaki (@gclue_akira) March 2, 2023
下記のGithubのプロジェクトは、そのまますぐ動かせます。https://t.co/lpuukrLGau pic.twitter.com/Hyu6ZEqleF
・サイズ無制限の画像復元
abs: https://arxiv.org/abs/2303.00354
github: https://github.com/wyhuai/DDNM

・WhisperX: 長時間音声の時間精度の高い音声文字起こし
abs: https://arxiv.org/abs/2303.00747
GitHub: https://github.com/m-bain/whisperX

・All-In-One-Deflicker 様々なビデオからあらゆる欠陥を除去できる後処理フレームワーク
https://chenyanglei.github.io/deflicker/
Blind Video Deflickering by Neural Filtering with a Flawed Atlas
— AK (@_akhaliq) March 2, 2023
project page: https://t.co/BStkbNmOZ7 pic.twitter.com/uupNLQuvqd
・言語モデルで科学の新しい仮説発見検証
-研究目標と2つの大きなコーパスを与える
-コーパスレベルの差分について仮説を立てる
-言語モデルは、関連する重要な仮説を提案 675 のビジネス、科学、健康などの問題について評価
論文: https://arxiv.org/abs/2302.14233
コード: https://github.com/ruiqi-zhong/D5

・Flan-UL2 20Bがオープンソースで公開
- フォームなし、Apache ライセンス
- UL2 20BモデルをFlanでインストラクショントレーニングしたもの
- MMLU/Big-BenchハードでのベストOSモデル
- Flan-T5 XXLを上回り、Flan-PaLM 62Bに匹敵
https://www.yitay.net/blog/flan-ul2-20b

・Google USM
100 以上の言語で自動音声認識 (ASR) を実行する大規模モデルである Universal Speech Model (USM) 1/7 のラベル付き学習データと事前トレーニング用の大量のラベルなしデータを使用したウィスパーと比較して、同等またはそれ以上の結果
https://arxiv.org/abs/2303.01037

・ImageNet での 3D 生成
論文: https://arxiv.org/abs/2303.01416
プロジェクト: https://snap-research.github.io/3dgp
3D generation on ImageNet
— AK (@_akhaliq) March 3, 2023
abs: https://t.co/E13WHbH73B
project page: https://t.co/9YczAX8pa1 pic.twitter.com/khHWPzPMgX
・学習済みの視覚言語モデルを使用したオープンワールド オブジェクト操作
言語コマンドと画像物体検出手法で情報を抽出し、現在のロボットポリシーを調整するMOOを提案 ゼロショットで幅広い新しいオブジェクトと環境に一般化し、指差しなどの非言語入力での対象指定も可能に。
論文: https://arxiv.org/abs/2303.00905
プロジェクト: https://robot-moo.github.io/
Open-World Object Manipulation using Pre-trained Vision-Language Models
— AK (@_akhaliq) March 3, 2023
abs: https://t.co/10CmxMuFLA
project page: https://t.co/kBQWopiKYW pic.twitter.com/CWsMtTwXGZ
・テキスト動画生成(英語のみ)
1, テキスト特徴量取得
2, 1より画像特徴量取得
3, 2より動画生成
4, 動画補間
5, 動画アップスケール
モデルはまだダウンロード不可
詳細: https://modelscope.cn/models/damo/cv_diffusion_text-to-video-synthesis/summary
a multi-stage text-to-video generation diffusion model, which inputs a description text and returns a video that matches the text description
— AK (@_akhaliq) March 2, 2023
model parameters are about 60 100 million (google translate)
model: https://t.co/Ut0aGgaEUO pic.twitter.com/fS633vf9Sj
・頭脳MRIから、見られた画像を再現
https://sites.google.com/view/stablediffusion-with-brain/?pli=1

この記事が気に入ったらサポートをしてみませんか?