
Googleスプレッドシート シート関数で作る「順列と組み合わせ」全パターン出力 2

前回に続きGoogleスプレッドシートのシート関数ネタ。「順列と組み合わせ」の全パターンを出力する数式を考えてみたいと思います。
GASを使わずシート関数の組み合わせのみで実現します。
今回は前回と同じく LETやLAMBDA登場前の古いやり方での「組み合わせ」の全パターン出力式の紹介ですが、こちらは新関数を使ったイマドキ(最先端)の 順列、組み合わせの式にも負けない、割とシンプルで動作の軽い現在でも十分通用する式となっています。
LAMBDA関数を使った最新の解法は・・・、今回はそこまでたどり着かず次回となりますw (組合せ の解説だけで1万文字超えてしまったので)
相変わらずの長文noteですが、是非最後までお読みください。
前回の noteはGoogleスプレッドシートのLET,LAMBDA 登場前の関数を組み合わせて「順列」を全パターン出力する式を紹介しました。
前回の式をベースに「組み合わせ全パターン出力式」を考える

この部分は正直、余談なんで読み飛ばしていただいてもOKです。
前回の順列の式をベースに組み合わせの全パターン出力式を作ろうとした時にネックとなるのが、重複をどう排除するかです。
たとえば 画像のケース、A,B,C,Dの4つの要素から3つを取り出した場合、組み合わせだと
A,B,C と A,C,B、B,A,C、B,C,A、C,A,B、C,B,A これらは同一と見なされます。
前回の順列の全パターン出力式
=ARRAYFORMULA(
VLOOKUP(
A1,
A1:E1,
MID(
FILTER(
BASE(SEQUENCE(COUNTA(A1:E1)^B3,1,0),COUNTA(A1:E1),B3),
LEN(REGEXREPLACE(
CONCATENATE(SEQUENCE(COUNTA(A1:E1),1,0)),
"["&BASE(SEQUENCE(COUNTA(A1:E1)^B3,1,0),COUNTA(A1:E1),B3)&"]",
))=COUNTA(A1:E1)-B3
),
SEQUENCE(1,B3),1
)+1,
FALSE
)
)これをベースに考えた場合、どういった重複排除方法があるでしょうか?
1.FILTER関数で「行単位で見て自分の右側に自分以下の数値が無い」を条件に絞り込む
実データだと難しいので、その手前の数値をベースに考えてみましょう。
先ほどと同じく4つの要素から3つを取り出した場合、BASE関数で生成できる数値で考えた場合、
0,1,2
と 以下は同じ組み合わせである
0,2,1
1,0,2
1,2,0
2,0,1
2,1,0
こうなります。
この時 同じ組み合わせと見なされる数値の組み合わせの特徴としては、「自分の右側に自分以下の数値が登場する」と言えます。
0,1,2 ・・・必ず右側の数字は左側の数字より大きい
0,2,1
1,0,2
1,2,0
2,0,1
2,1,0 ・・・ 自分の右側に自分以下の数値が登場している
これを条件にFILTER関数で絞り込むためには

=ARRAYFORMULA(--MID(BASE(SEQUENCE(4^3,1,0),4,3),SEQUENCE(1,3),1))
BASE関数で生成した 000~333までの配列を3列の数値配列に分割してから

=ARRAYFORMULA(BYROW(--MID(BASE(SEQUENCE(4^3,1,0),4,3),SEQUENCE(1,3),1),LAMBDA(r,{-1,CHOOSECOLS(r,SEQUENCE(COLUMNS(r)-1))})))
BYROW関数で行毎に、左に -1を繋げて、一番右側の列を除外した3列の配列を生成してから

=ARRAYFORMULA(BYROW(--MID(BASE(SEQUENCE(4^3,1,0),4,3),SEQUENCE(1,3),1),LAMBDA(r,AND({-1,CHOOSECOLS(r,SEQUENCE(COLUMNS(r)-1))}<r))))
このように行単位で
AND(一つ左にズラして 一番右に -1を付けた 3列の配列 < 元の3列の配列)
という処理をすることで、
「行単位で見て自分の右側に自分以下(同じも含む)の数値が無い」行だけ TRUEとなります。

0,1,2、0,2,3、1,2,3 の行がTRUEとなっていますね。
これを条件としてFILTER関数を使うことで

=FILTER(
--MID(BASE(SEQUENCE(4^3,1,0),4,3),SEQUENCE(1,3),1),
BYROW(--MID(BASE(SEQUENCE(4^3,1,0),4,3),SEQUENCE(1,3),1),
LAMBDA(r,AND({-1,CHOOSECOLS(r,SEQUENCE(COLUMNS(r)-1))}<r))))
0,1,2,3,4 の 4つの要素の中から 3つを取り出した 組み合わせの全パターンとなります。
でもこれ、なかなかヘビーな式ですよね。
一応 FILTER関数の条件列の生成にBYROW関数を使う方法は、以前のnote「FILTER関数の超応用例」で触れています。
2.SORT関数で「行単位に左から昇順に並べ替えをして最後にUNIQUEで重複排除
もう1つ、順列の中の重複を排除して組み合わせにする方法として「行単位で並び替える」やり方が思いつきます。
0,2,1 → 0,1,2
1,0,2 → 0,1,2
1,2,0 → 0,1,2
2,0,1 → 0,1,2
2,1,0 → 0,1,2
このように 全て左から右に昇順に並び替えてからUNIQUE関数で重複排除とする方法です。
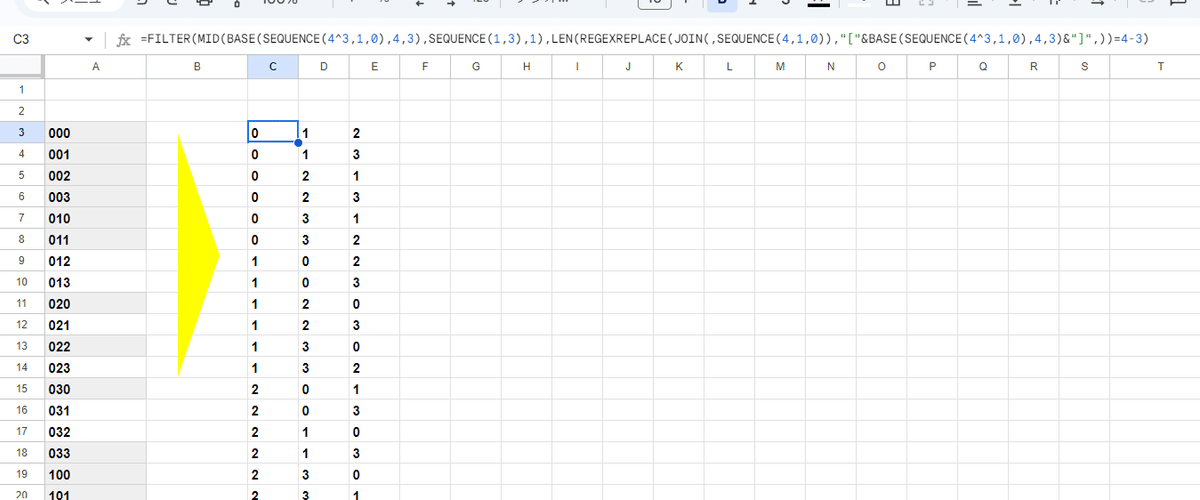
=FILTER(
MID(BASE(SEQUENCE(4^3,1,0),4,3),SEQUENCE(1,3),1),
LEN(REGEXREPLACE(JOIN(,SEQUENCE(4,1,0)),
"["&BASE(SEQUENCE(4^3,1,0),4,3)&"]",))=4-3)
こちらは分割の前に前回の順列で登場した REGEXREPLACE関数とLEN関数を用いた方法で条件式を作り、FILTER関数で同じ数字を2回以上使うケースを排除しつつ 3列に分割。

=TRANSPOSE(BYCOL(TRANSPOSE(
FILTER(MID(BASE(SEQUENCE(4^3,1,0),4,3),SEQUENCE(1,3),1),
LEN(REGEXREPLACE(JOIN(,SEQUENCE(4,1,0)),
"["&BASE(SEQUENCE(4^3,1,0),4,3)&"]",))=4-3)),
LAMBDA(c,SORT(c))))
これをTRANSPOSE関数で 縦横変換して、BYCOL関数で列毎にSORTで昇順にしてから 再度全体をTRANSPOSEで縦横を戻します。
Googleスプレッドシートは横方向の並べ替えが出来ないので、どうしても
縦方向のデータにする → SORT関数で並び替え → 横方向のデータに戻す
という手順を踏む必要があります。

=UNIQUE(TRANSPOSE(BYCOL(TRANSPOSE(
FILTER(MID(BASE(SEQUENCE(4^3,1,0),4,3),SEQUENCE(1,3),1),
LEN(REGEXREPLACE(JOIN(,SEQUENCE(4,1,0)),
"["&BASE(SEQUENCE(4^3,1,0),4,3)&"]",))=4-3)),
LAMBDA(c,SORT(c)))))
並び替えが出来れば、最後に UNIQUE関数で重複排除で完成です。
2つ方法を紹介しました。
このように前回の順列の全パターン出力式をベースに 組み合わせを出す方法もあるのですが、どちらの式も LAMBDAヘルパー関数の BYROWやBYCOLがあるからなんとか処理できています。
これらを使わない方法となると非常に難しそうですよね。。行毎の並べ替えは厳しそう・・・、1つ目の比較はMMULT組み合わせて出来るかも。。
仮に出来たとして手順が増えるので、順列の重い計算処理がさらに重くなりそうという懸念もあります。
違うアプローチで「組み合わせ全パターン出力式」を考える
というわけで、組み合わせは 順列の全パターン出力式とは、別アプローチで考える必要があります。
ここからが、組み合わせ全パターン出力式の本番です。
Step1. 組み合わせを 2進数で考える
並び順が影響する順列と違って、組み合わせは 要素の中から「選択する」か「選択しない」かの2択です。
つまり 「0 か 1 か」の 2進数の世界と考えることができます。

4つの要素から 2つを取り出すケースの組み合わせを考える際に、 4桁の2進数 0000~1111 までを用意したとします。
0を「取り出す」、1を「取り出さない」 フラグと定義すると、
0000 や 0001、0010は 0 が3つ以上あるので 対象外となりますが、0011や0101などは 0が2つなので 2個取り出すという今回のケースにマッチします。
0の位置をそのまま横並びの要素の位置と考えれば
0011 なら A,B を取り出す
0101 なら A,C を取り出す
と 見なせますね。
ここで「1を取り出す、0を取り出さない」と定義する方が自然な気がしますが、ここは「0を取り出す、1を取り出さない」と定義することをお勧めします。
「1を取り出す」としてしまうと 0000~1111までを並べた時に、順番的に 0011や0101 などが先に登場する為、要素のうち右側の組み合わせ C,DやB,Dが先に登場してしまう為です。

人間の感覚だとまず左側の要素から組み合わせていく方が自然ですよね。だから1ではなく、0を「取り出す」と定義しています。
Q1. BASE関数で 0000~1111を生成したい

それではお題いってみましょう。全開の順列の時よりも簡単だと思います。
BASE関数を使って一つの式で 0000~1111までの画像のような配列を生成するのはどうすればよいでしょうか?
使える値は
元の要素数 ・・・ 4
取り出す数 ・・・ 未定(ここでは使わない)
底 ・・・ 2
だけです。考えてみましょう!
↓↓
ここから回答です。
↓↓
A1. BASE関数で 0000~1111を生成する
回答です。
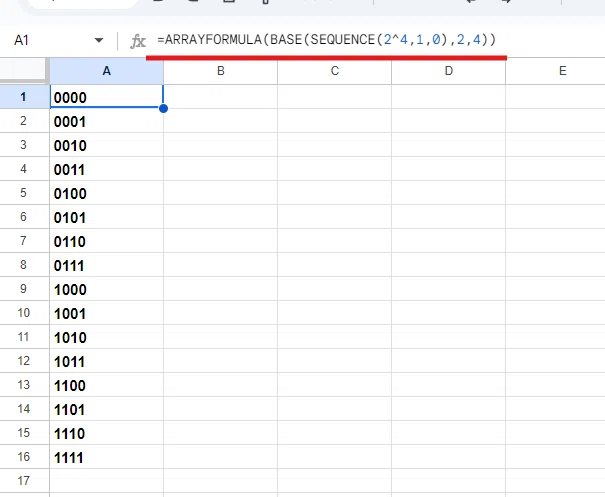
=ARRAYFORMULA(BASE(SEQUENCE(2^4,1,0),2,4))
まず 4桁の 0000~1111 までは 2^4(2の4乗)通りあります。
これは 0か1のどちらか2択の入れ物が4つあると考えてください。

2^4、つまり 16パターンなので、SEQUENCE関数で16個の連番を生成します。この時スタートを 0 (変換後 0000) としたいので、
SEQUENCE(2^4,1,0)
としています。
BASE関数でこれを第1引数として、
第2引数の底を2進数なので 2
第3引数の桁数を 要素の数 4 として
さらに配列に対する処理なのでARRAYFORMULAを組み合わせて
=ARRAYFORMULA(BASE(SEQUENCE(2^4,1,0),2,4))
こんな式になります。
=ARRAYFORMULA(BASE(SEQUENCE(2^4)-1,2,4))
こうしてもOK。
つまり 組み合わせを求める際は、この段階で取り出す数は関係なく
=ARRAYFORMULA(
BASE(SEQUENCE(2^【要素の数】,1,0),2,【要素の数】))
ということですね。
Step2. 取り出したい数にマッチするものだけに絞り込む

この2進数の0000~1111の全パターンを「取り出す数」に合わせて絞り込みます。
「0を取り出す」と定義しているので、使われている 0の数が取り出す数と一致しているものだけに絞り込めばよいですね。
Q2. 生成した 0000~1111 を 0が2個使われているものだけに絞り込みたい

お題いってみましょう。BASE関数で生成した 0000~1111のうち 0が2回だけ使われている(登場する)ものだけに絞り込みたい場合、どんな数式を組めばよいでしょうか?
これも順列の時の式に比べるとぐっと簡単です。考えてみましょう!(※LET,LAMBDA が無い時代の式です)
↓↓
ここから回答です。
↓↓
A2. 生成した 0000~1111 を 0が2個使われているものだけに絞り込む
回答です。

=FILTER(BASE(SEQUENCE(2^4,1,0),2,4),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2)
「0が2回だけ使われている」は、「0以外の文字(数字)を消して0だけにした場合 残った文字数は 2になる」と考えることができます。
今回は0以外は1しか使われてないので簡単ですね。基本の置換関数であるSUBSTITUTE関数を使いましょう。

その結果から LEN関数で文字数を取得すれば、0が使われている数となりますね。これが =2 (取り出す数)であるを条件としてFILTER関数を使用すればよいので
=FILTER(BASE(SEQUENCE(2^4,1,0),2,4),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2)
回答のこの式になるわけです。FILTER内では自動で配列処理効果が付与されるので、ARRAYFORMULAは不要となります。
要素数と取り出す数 を使うと
=FILTER(BASE(SEQUENCE(2^【要素数】,1,0),2,【要素数】),
LEN(SUBSTITUTE(
BASE(SEQUENCE(2^【要素数】,1,0),2,【要素数】),1,))=【取り出す数】)
こうなります。
Step3a. 分割じゃなく、あえて元の要素を連結で正規表現で取り出す

このFILTER関数で取り出したい数(0の数)で絞り込んだ結果を使って、順列の時と同じように分割して実データから引き当てしたいところですが、これはお勧めしません。
上の画像は
=FILTER(
IF(--MID(BASE(SEQUENCE(2^4,1,0),2,4),SEQUENCE(1,4),1),,A2:D2),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2
)このような式でFILTER内でBASE関数で生成した0000~1111を分割して数値化、IF関数で 1をTRUE、0をFALSE扱いで分岐させて 配列として位置が対応する A2:D2を引き当てたものを、取り出したい数(0の数)でFILTER関数で絞り込んだ結果です。
この結果が

こうなるわけですが、きゅっと左に寄せたいですよね。。
この行毎の左への空白詰め・・・今だったら BYROWを使って行毎にTOROW関数で空白詰めが簡単に出来ます。
TOROW関数やTOCOL関数の 第2引数 1設定で 空白を無視して詰める仕様は非常に重宝します。

=BYROW(
FILTER(
IF(--MID(BASE(SEQUENCE(2^4,1,0),2,4),SEQUENCE(1,4),1),,A2:D2),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2
),LAMBDA(r,TOROW(r,1))
)でも、こんな式で処理出来るのは、行毎に処理が出来るLAMBDAヘルパー関数のBYROWがあって、さらにGoogleスプレッドシートのBYROWは 行毎に処理して配列を返すことが出来るからです。
当然ですが LAMBDA登場前は、この状態から行毎の空白詰めはなかなか厳しいものがありました。
ただ、これは一応やり方があって

=ARRAYFORMULA(
SPLIT(TRANSPOSE(
SPLIT(TEXTJOIN(",",TRUE,
FILTER(
IFERROR(
IF(--MID(BASE(SEQUENCE(2^4,1,0),2,4),SEQUENCE(1,4+1),1),,A2:D2)
,"_"
),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2
)
),"_")
),",")
)このように、あえてMID関数の第2引数を +1 することで、1つ多くとろうとすることでエラーを吐かせ、IFERROR で "_"を一番右の列に仕込んだ配列を生成(これを改行用マーキングとする)、TEXTJOINとSPLIT2回で 一度まとめてから縦分割、横分割って流れで処理しています。
SPLITとTEXTJOIN、縦横変換を組み合わせた TEXTSPLITのような分割テクは過去noteでも紹介した技です。
ただ、もうちょい良い方法があるんで今回はそちらを紹介します。
考え方としては分割せずに正規表現を活用して、元の要素を連結してからぶっこ抜くです!
お題いってみましょう。
Q3. 正規表現で テキストから 複数パターンを取り出したい

細かい説明は後にして、まずはこのお題にチャレンジしてみてください。
Q3-1. A2:D2の範囲の要素を F2のように カンマ区切り(最後にもカンマ付)の1つのテキスト A,B,C,D, としたい。どんな式をF2に入れればよいか?
Q3-2. F2のテキストから カンマで区切られた要素の 1つ目と2つ目、そして1つ目と3つ目という組み合わせを F8:G9 のような形で取り出したい。
これは F8に入れた式
=ARRAYFORMULA(REGEXEXTRACT(F2,H8:H9))
で F8:G9 の結果を出力しているが、H8とH9にはどのような正規表現テキストをいれればよいか?
この2つをやってみましょう。
お題は A,B,C,D と単文字ですが、個々の要素が2文字以上のテキストでも対応できるように考えましょう。
↓↓
ここから回答です。
↓↓
A3. 正規表現で テキストから 複数パターンを取り出す
回答です。
まずは Q.3-1ですが、

=JOIN(",",A2:D2,)
こんな式が良いかと思います。
JOIN関数でカンマを区切り文字として結合、第3引数を空とする。他の式でも可能ですが、この式が一番短いでしょう。
TEXJOINの方が出番は多いですが、空白除去を気にしなくてよい一次元配列の結合であればJOIN関数の方が短く書けます。
第3引数に空を指定して区切り文字で連結できるはGoogeスプレッドシートならではですね。
そして3-2 の回答、正規表現ですが、

(.+?),(.+?),.+?,.+?, ・・・ H8
(.+?),.+?,(.+?),.+?, ・・・ H9
こんな正規表現テキストが正解となります。(他の書き方もあります)
取り出したい部分はカッコをつけてキャプチャグループとした (.+?),
不要な部分はカッコをつけない .+?,

このようにすることで、カンマで区切られた欲しい箇所を取得しています。

要素が2文字以上の場合でも、問題なく取り出せてますね。
Step4. 0と1を正規表現に変換しよう
ここまでくるとピンときた人もいるかもしれませんが、

このように BASE関数で生成してFILTERで絞り込んだ 4桁の2進数テキストの
0の箇所を (.+?),
1の箇所を .+?,
とすることで、元の要素を連結したテキストから、0の箇所を取り出せそうですね。
それではお題です。
Q4. 0 1を正規表現テキストに変換して、元データを引き当てたい

Q2の回答の式
=FILTER(BASE(SEQUENCE(2^4,1,0),2,4),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2)
とQ3 の回答
=JOIN(",",A2:D2,)
と
取り出したい部分はカッコをつけてキャプチャグループとした (.+?),不要な部分はカッコをつけない .+?,
これらを組み合わせて、4つの要素(A,B,C,D)から2つを取り出した全組み合わせ 6パターンを出力する式を作りましょう!
考えてみましょう。
↓↓
ここから回答です。
↓↓
A4. 0 1を正規表現テキストに変換して、元データを引き当てる
回答です。
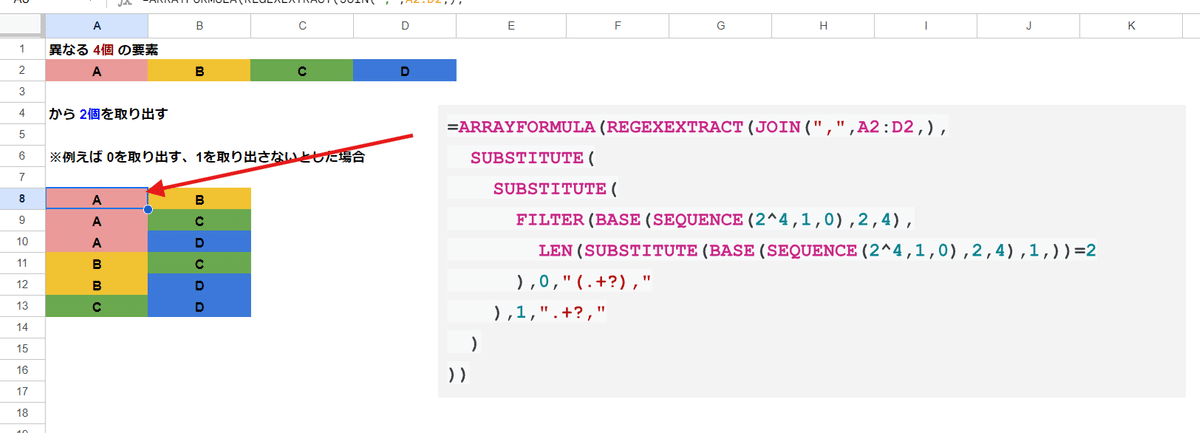
=ARRAYFORMULA(REGEXEXTRACT(JOIN(",",A2:D2,),
SUBSTITUTE(
SUBSTITUTE(
FILTER(BASE(SEQUENCE(2^4,1,0),2,4),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2
),0,"(.+?),"
),1,".+?,"
)
))ん?と思う方もいるかもしれませんが、解説していきます。
まず、
取り出したい部分
0 を (.+?), に置換
不要な部分
1 を .+?, に置換
この部分ですが、これはいい方法はありません。
煩雑ですが2回と固定されてますし、SUBSTITUTEをネストしちゃいましょう。
SUBSTITUTE(
SUBSTITUTE(
FILTER(BASE(SEQUENCE(2^4,1,0),2,4),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2
),0,"(.+?),"
),1,".+?,"
)あとは Q3 の時に作った JOIN(",",A2:D2,) の式で A,B,C,D, というテキストを生成して、REGEXEXTRACT関数でカッコ部分を取得すればOK。
FILTERの外側での配列処理なので、ARRAYFORMULAが必要となります。
Googleスプレッドシートの関数の知識がある人なら、この処理を丸ごとFILTER関数内に入れちゃった方が短くできるのでは?って考えたかもしれません。
もちろん、それでも同じような結果は得られますし式は短くなります。

=FILTER(
REGEXEXTRACT(JOIN(",",A2:D2,),
SUBSTITUTE(
SUBSTITUTE(
BASE(SEQUENCE(2^4,1,0),2,4),0,"(.+?),"
),1,".+?,"
)
),LEN(SUBSTITUTE(BASE(SEQUENCE(2^4,1,0),2,4),1,))=2
)しかし、これは同じような結果のように見えて実は

このように見えないですが、空白列を含む 4列データを結果として返しています。
これは FILTERで絞り込む前に REGEXEXTRACT関数で テキストを抜き出しているので、0000のケースは A,B,C,D と4列データ になっているからです。
その後で FILTERで行を絞り込んでも配列の列数のサイズは変わりません。
一方回答の式は ARRAYFORMULAが外側について式としては長くなってしまいましたが、

このように2つ取り出す場合の結果範囲は2列で収まっており、3列目、4列目のセルは結果範囲ではないのでセルに手入力しても問題ありません。
ここは FILTER後に REGEXEXTRACTで抜き出す回答の式をおススメします。
Step5. LET関数を使った汎用的な式にしよう
最後にQ4 の回答の式をベースに、要素の範囲と 取得する数だけを指定するだけで使える 汎用性のある式としましょう。
今回は 最初からLET関数を使って整理することとしましょう。
Q5. 組み合わせ全パターン出力の汎用性のある式を完成させたい

母体となる7つの要素を セル範囲を A1:G1 、
取り出す数を B3 セルで指定するとして、
A1:G1の7つの要素から B3 で指定した数を取り出した時の組み合わせ全パターンを出力する A5セルに入れる式を考えてみましょう。
LET関数で
A1:G1 を a
B3 を k
と定義するものとします。
考えてみましょう!
↓↓
ここから回答です。
↓↓
A5. 組み合わせ全パターン出力の汎用性のある式を完成させたい
回答です。
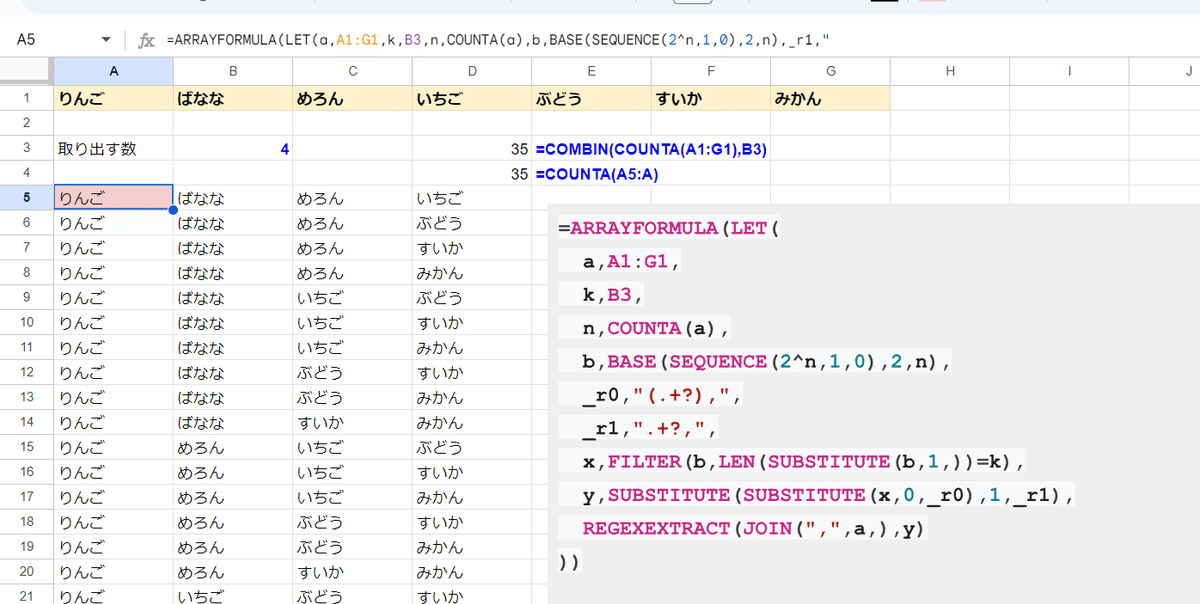
=ARRAYFORMULA(LET(
a,A1:G1,
k,B3,
n,COUNTA(a),
b,BASE(SEQUENCE(2^n,1,0),2,n),
_r0,"(.+?),",
_r1,".+?,",
x,FILTER(b,LEN(SUBSTITUTE(b,1,))=k),
y,SUBSTITUTE(SUBSTITUTE(x,0,_r0),1,_r1),
REGEXEXTRACT(JOIN(",",a,),y)
))LET関数を使うと書き方は色々ありますが、一つずつステップを踏むのがよいですね。
まず 全体に配列効果を付与する為に、LETの外側にARRAYFORMULAをセットします。
a,A1:G1, ・・・ 要素が入っている範囲
k,B3, ・・・ 取り出す数
を使って、
n,COUNTA(a), ・・・ 要素の数(今回の場合は7)
b,BASE(SEQUENCE(2^n,1,0),2,n), ・・・ 要素の数の桁数の 000.. ~ 111… の配列
を生成、また正規表現を
_r0,"(.+?),", ・・・ 取り出す部分の正規表現テキスト
_r1,".+?,", ・・・ 取り出さない部分の正規表現テキスト
このように事前に定義しておきます。ここまでが下準備
x,FILTER(b,LEN(SUBSTITUTE(b,1,))=k),
FILTERで 0が取り出す数のものだけに絞り込んだ結果を xと置いて
y,SUBSTITUTE(SUBSTITUTE(x,0,_r0),1,_r1),
この x の 0 を _r0(取り出す) に 1 を _r1(取り出さない) に置換した結果を yとして
REGEXEXTRACT(JOIN(",",a,),y)
最後に a(要素)をカンマ連結したテキスト JOIN(",",a,) から 先ほど生成した y (縦1列の正規表現テキストの配列)で配列処理で もともと 0だった箇所を出力 → これが組み合わせ全パターン
このようにしてみました。他の書き方でもよいです。
押さえるべきポイントは、使う際に変更が発生するのが
a,A1:G1,
k,B3,
この A1:G1 と B3 の部分だけとすることです。
ちなみに本当にLETが無かった時代は
=ARRAYFORMULA(
REGEXEXTRACT(
JOIN(",",A1:G1,),
SUBSTITUTE(
SUBSTITUTE(
FILTER(
BASE(SEQUENCE(2^COUNTA(A1:G1),1,0),2,COUNTA(A1:G1)),
LEN(SUBSTITUTE(BASE(SEQUENCE(2^COUNTA(A1:G1),1,0),2,COUNTA(A1:G1)),1,))=B3
),0,"(.+?),"
),1,".+?,"
)
)
)こんな式を書いていました。
LET関数で整理された式に比べると読解しにくいですね。
動作確認で式を動かしてみましょう。

いい動きですね! COMBIN関数の結果と 全パターンの行数も合ってます。
順列の式は 7つの要素から7つ取り出そうとした場合、BASE関数を使う方法だと 一度 7^7 = 823543(約82万3千) という 膨大なデータを一度生成して処理していた為、非常に処理に時間がかかり固まるケースもありました。
組み合わせの場合は 同じ7つの要素から1つ取り出そうとした場合でも 7つ取り出そうとした場合でも、いずれの場合も BASE関数で生成するデータは 2^7 = 128 という 小さいサイズである為、処理が断然早いわけです。
次回はBASE関数を使わない 新関数で 順列・組み合わせを出力する式に挑戦
今回はLET、LAMBDA関数登場前の 組み合わせを全パターン出力する式を紹介しました。
まとめ:LAMBDA無しで書く 順列と組み合わせ全パターン出力式
↓ LETを使って見やすくした 組み合わせ全パターン式
=ARRAYFORMULA(LET(
a,A1:G1,
k,B3,
n,COUNTA(a),
b,BASE(SEQUENCE(2^n,1,0),2,n),
_r0,"(.+?),",
_r1,".+?,",
x,FILTER(b,LEN(SUBSTITUTE(b,1,))=k),
y,SUBSTITUTE(SUBSTITUTE(x,0,_r0),1,_r1),
REGEXEXTRACT(JOIN(",",a,),y)
))こちらは現在でも十分通用する式です。
でも、前回のnoteの 順列の式
↓ LETを使って見やすくした 順列全パターン式
=ARRAYFORMULA(LET(
array,A1:E1,
k,B3,
n,COUNTA(array),
x,BASE(SEQUENCE(n^k,1,0),n,k),
VLOOKUP(
INDEX(array,,1),
array,
FILTER(
MID(x,SEQUENCE(1,k),1)+1,
LEN(REGEXREPLACE(
CONCATENATE(SEQUENCE(n,1,0)),
"["&x&"]",
))=n-k
),
FALSE
)
))こちらは、ちょっと重すぎるんですよね。
そもそも、順列と組み合わせの式の構成が全然違うってのも気になるところ。
次週はいよいよ、LAMBDA 他 新関数を使った BASE関数以外の方法による順列・組み合わせの全パターン式(1つの式で引数で順列・組み合わせを切り替えて出力可能)に挑戦してみましょう!