
超絶便利-Googleスプレッドシートの COUNTIFやSUMIFS、FILTER関数を(割と)厳密な一致判定に切り替える{魔法}

関数超応用例シリーズで UNIQUE関数を取り上げている途中なんですが、1週違うネタを挟んで、次回 UNIQUE関数の続きを書きたいと思います。
理由は、今回紹介するネタが UNIQUE関数の超応用例に関係してくるからです。
SNSやブログ等でもあまり見かけない レアなハックネタですし、使い方は超簡単で超絶便利という魔法のような テクニック。
是非、活用ください!
前回は UNIQUE関数や派生関数の COUNTUNIQUE関数、COUNTUNIQUEIFS関数について書きました。
COUNTIFやSUMIF(S)を 割と厳密な一致判定に変える{魔法}とは?
すぐ使える簡単ハックネタなんで、いきなり結論を書いておきましょう。

おわかりいただけただろうか?
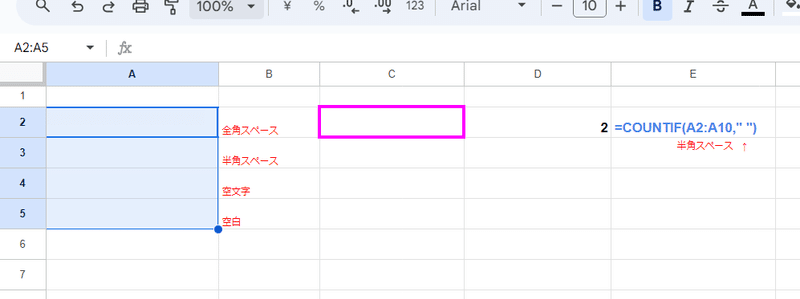
COUNTIF関数で、範囲 A:A 内に D2 (葬送のフリーレン)に一致するものが幾つあるか を カウントしてるわけですが、
範囲 A:A → 配列 {A:A}

範囲に { } 中カッコをつける。
たったこれだけで COUNTIFSやSUMIFSといった 〇〇IFS系関数の 一致判定基準が(割と)厳密になり、正しい結果が得られるようになります。
なんで? と聞かれても 理由は mirにもわかりません。
上の画像だと、「葬送のフリーレン」と一致するセルは 2であるはずですが、普通に COUNTIFで一致する数を得ると 8という誤った結果になります。
これは Googleスプレッドシートの
「ひらがな、カタカナ、全角、半角、伸ばし棒と母音」を全て区別しない
緩い一致判定の 困った仕様の為です。
しかし、A:A → {A:A} と 第1引数の条件範囲を配列化することで、 2という正しい(厳密な)判定結果に変わっているのがわかりますね。
まとめると、こんな感じ ↓
■Googleスプレッドシートの イコールによる一致判定は、ひらがな、カタカナ、全角、半角、大文字、小文字を区別せず一致とみなす非常に緩い判定である
■COUNTIFSやSUMIFSなど 〇〇IF(S)系関数は、この緩い一致基準のせいで困ること(誤判定)がある
■【ここがポイント!】しかし 関数の条件範囲を セル範囲から配列に変更することで、一致判定が割と厳密になる(もっとも簡単に セル範囲を配列にする方法は、中カッコ{ }で括る方法)
アルファベットの大文字、小文字が同一とされてしまうので「割と」厳密な一致という言い方をしていますが、Googleスプレッドシートの困った仕様 「一致判定の緩さ」が、この簡単なテクニックで一気に解消されます。
単純に COUNTIF(S)、SUMIF(S) での集計に使うケースだけではなく、
条件付き書式
FILTER関数による重複の抽出
といったケースでも活用できます!
今回はこの {魔法} の詳しい動作、活用例をみていきましょう!
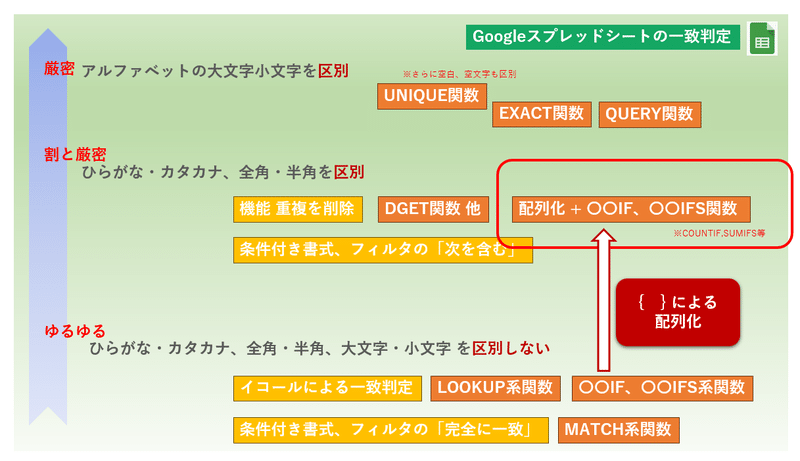
Googleスプレッドシートにおける 一致
まずはGoogleスプレッドシートの「一致」の基準、そして関数ごとの挙動の違いを見ていきましょう。
ユルユルだぜ! ひががな、カタカナの一致判定
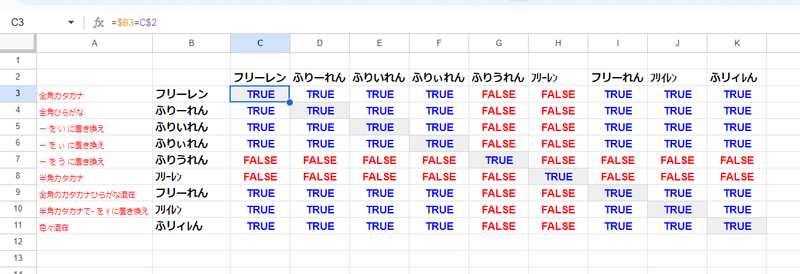
Googleスプレッドシートは 基本的に一致を判定する際、全角・半角、ひらがな・カタカナを区別してくれません。
表記のゆれを吸収してくれる度量の広さと言えなくもないですが、どちらかと言えば、この緩い一致基準による誤判定で困るケースの方が多いかも。
表では、かなりかけ離れている「ふりいれん」と「フリイレン」他、かなりの組み合わせが 一致と見なされているのがわかりますね。
さらに

伸ばし棒(長音記号)と母音のケース でも一致と判定してしまう親切設計w
「リー」と「リイ」は一致扱いですが、「リー」と「りう」は一致ではない、でも 「クール」と「くうる」は一致。
しっかり伸ばし棒の前の文字の母音を判別してくれてます。

しかし、このように 普通はありえない伸ばし棒が連続するケースの場合や、伸ばし棒の前が漢字のケース、また
ー と ~
は区別されるようです。 ~ と ~ は一緒の扱いですね。
不思議なのが 伸ばし棒の全角、半角の一致判定ルール

半角カナの伸ばし棒 と全角の伸ばし棒、単体だと一致判定なんですが、なぜか伸ばし棒の前に 同じ文字(ひらがな、カタカナ)がつくと、別モノと判定されてしまいます。
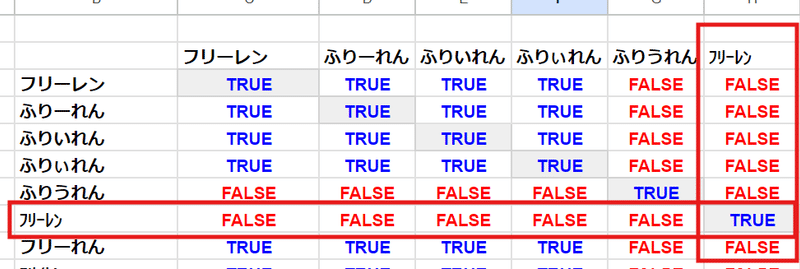
冒頭の表で、このように 半角の フリーレン が他と一致と見なされなかったのは、この せいだったんですね。
あまり無いケースですが、前につく文字が漢字の場合は影響なく、また伸ばし棒の後ろにひらがな、カタカナが付いても影響はありません。

特殊ですねー。
アルファベット、漢字、数字の一致判定
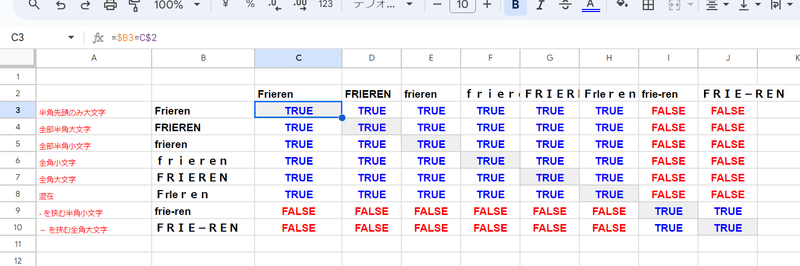
英語(アルファベット)の場合は、全角と半角を同一扱いに加え、大文字・小文字も区別せず一致と判定されます。
また、伸ばし棒(ハイフン)に関しては 前に付くのがひらがな、カタカナではないからか
frie-ren と FRIE-REN
は一致という扱いになってますね。ちなみに、この英字の伸ばし棒(ハイフン)は カタカナ変換の時とは別モノです。

色々違いがあるみたいで、解説サイトもあります。
漢字に関してはよほど特殊なケースでなければ 区別してくれると考えてよいでしょう。
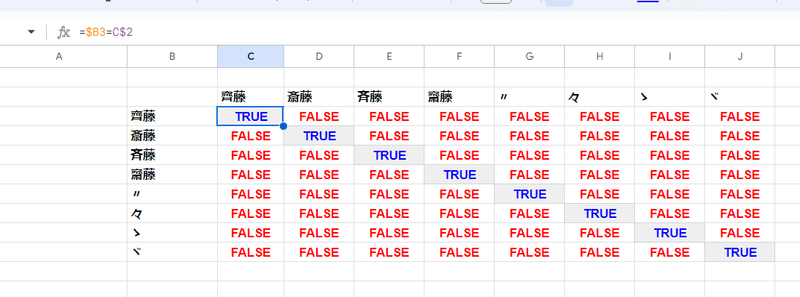
数字の場合も 横棒含め、全角・半角は同一と見なされます。

電話番号の表記に全角や半角のブレがある場合は、一致と判定してくれるんで便利かもしれません。
最後にスペースですが、さすがに空白、空文字とは区別されますが、半角スペース、全角スペースは同一とされます。
Googleスプレッドシートで イコール一致と同じ判定の関数
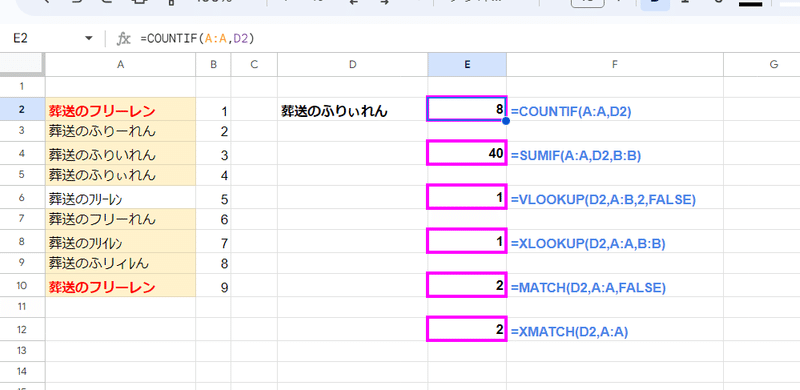
実はGoogleスプレッドシートの多くの主要関数が、この緩い = イコールでの一致判定と同じ判定基準となっています。
COUNTIFやSUMIFなどの 〇〇IF系
COUNTIFS、SUMIFSなどの 〇〇IFS系
VLOOKUPとHLOOKUP (第4引数 FALSE指定)、XLOOKUP
MATCH(第3引数 FALSE指定)、XMATCH
これら 非常によく使う関数が、ひらがな・カタカナ、全角・半角、大文字・小文字を区別せずに結果を返しています。
なかなか恐ろしいですね。
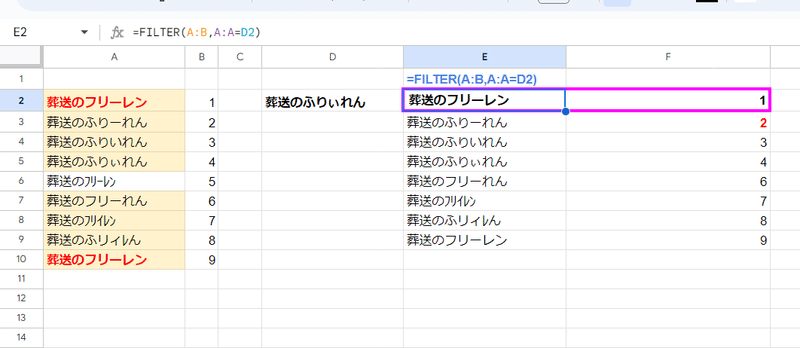
他にも FILTER関数でイコール条件で一致するデータを抽出する時や
マニアックなSORTN関数の 重複排除&並び替え
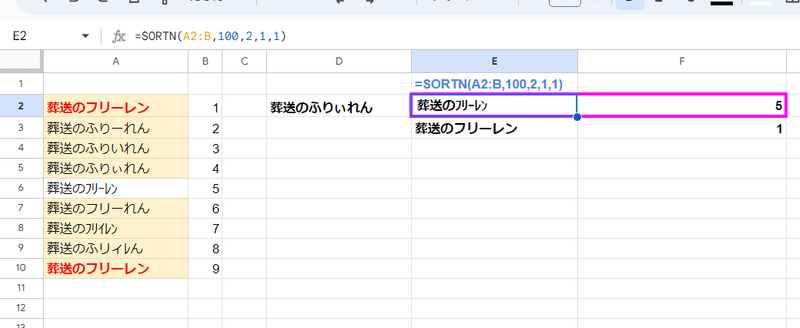
これらも、緩い一致判定の影響で意図しない結果となることがあります。
条件付き書式は「完全一致する」を条件にすると逆にゆるーい判定に
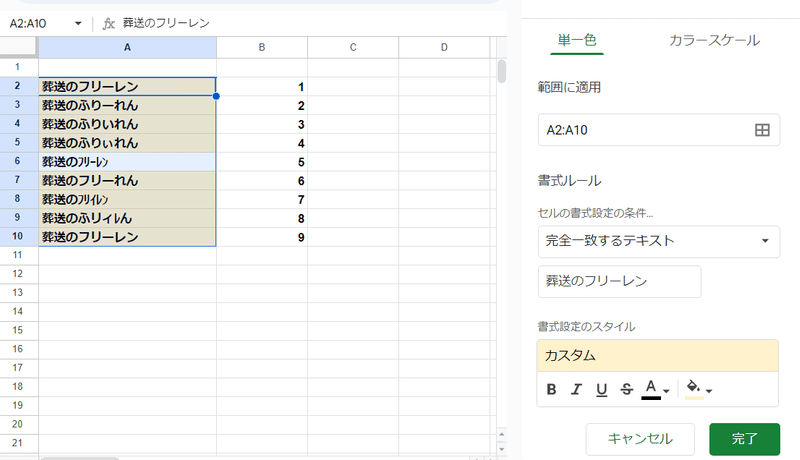
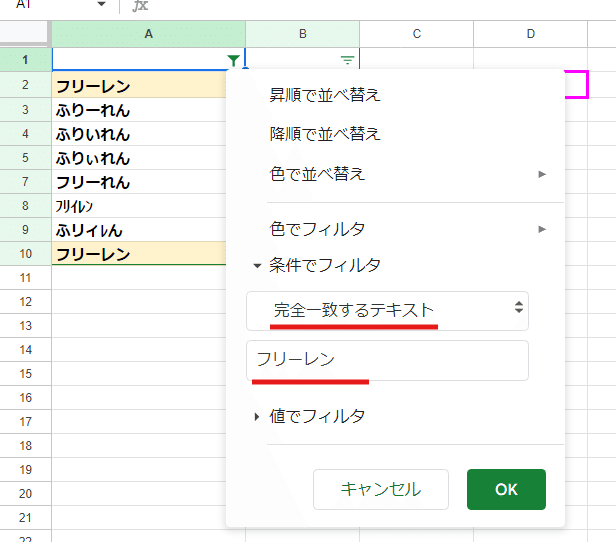
この緩い一致判定、実は条件付き書式でも使われています。
上のように、「葬送のフリーレン」と 「完全一致するテキスト」を条件にしているにも関わらず
葬送のふりぃれん や 葬送のフリイレン まで 一致と判定され色が付いちゃってますね。
どこが「完全に」なのやら・・・。
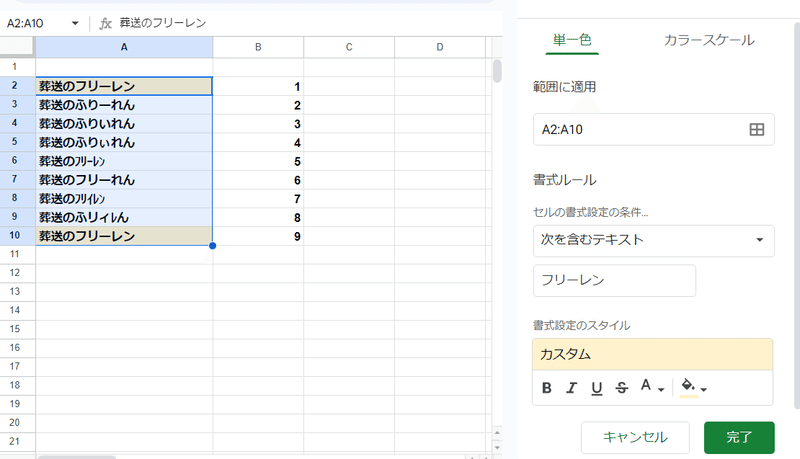
ところが「次を含むテキスト」だと、逆に判定が厳密になります。
セル参照を使っても
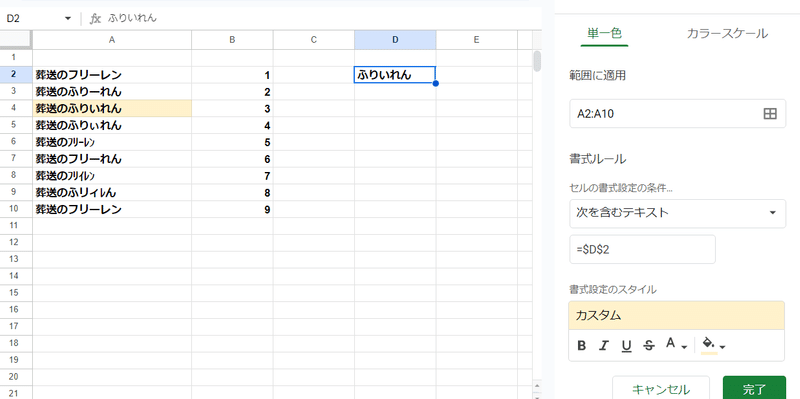
このように厳密になってますね。
でも、「次で終わるテキスト」を使うと
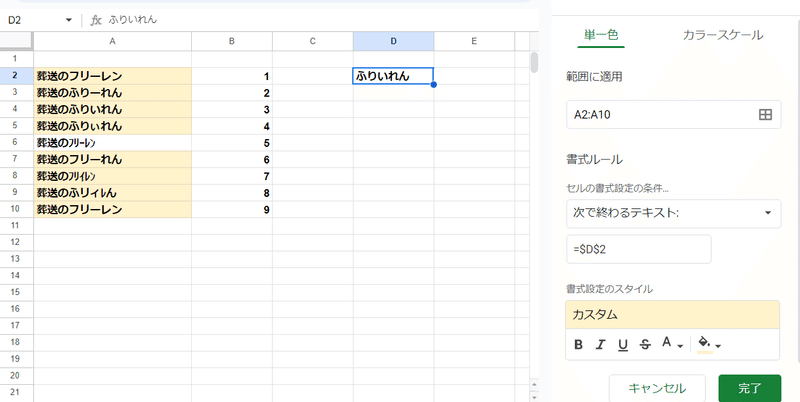
こっちはユルユル判定にw なんだこりゃ。
条件付き書式の一致判定の検証結果としては、
ひらがな、カタカナ、半角、全角を区別しない 緩い判定
・次で始まるテキスト
・次で終わるテキスト
・完全一致するテキスト
ひらがな、カタカナ、半角、全角を区別する割と厳密な判定
・次を含むテキスト
・次を含まないテキスト
このようになっています。「含む」「含まない」の時だけ判定が違うようです。
上の判定の違いは、条件付き書式だけではなく、フィルタやフィルタビュー(フィルタ表示)の 「条件でフィルタ」で使った場合も同様の基準となっています。
困ったもんですね。
とりあえず 部分的に一致するデータの考慮が不要であれば、
条件付き書式やフィルタで 厳密に一致を判定したい場合は、
「完全に一致するテキスト」ではなく「次を含むテキスト」を使った方が良い
ってのを覚えておくと良さそうです。
Googleスプレッドシートで 厳密に一致を判定できる関数
では逆に、ひらがな・カタカナ、全角・半角、大文字・小文字を区別して厳密に一致判定できる関数は何があるか?
厳密な一致判定が出来る 主要な関数は
EXACT関数
UNIQUE関数(COUNTUNIQUE、COUNTUNIQUEIFS 含む)
QUERY関数
この3つです。
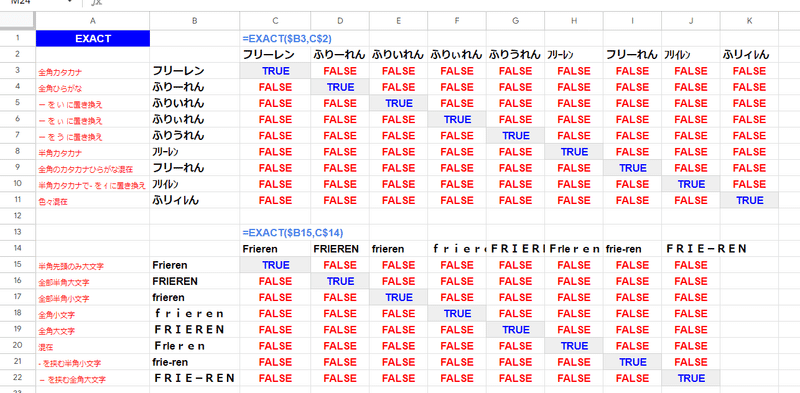
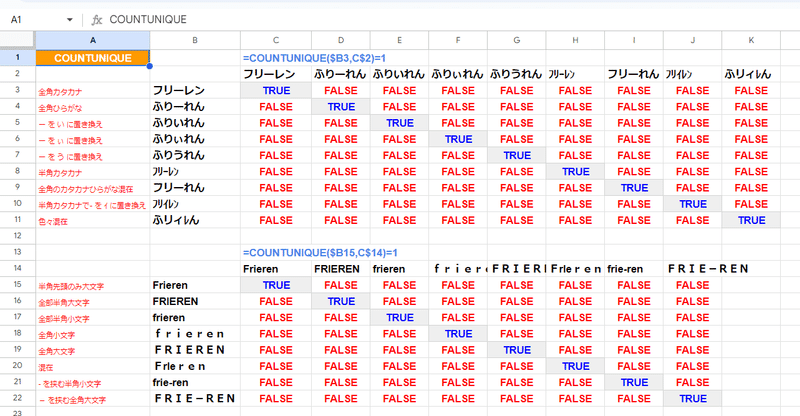
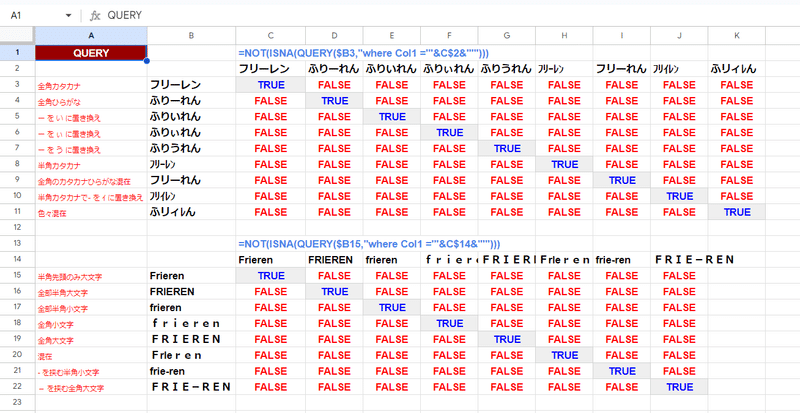
もちろん 文字列の検索関数や置換関数の FINDやSUBSTITUTE、REGEX系関数なども 厳密な一致となっていますが、これらは基本的にはセル内の文字列を探索するものなので除外しています。

Googleスプレッドシートで割と厳密に一致を判定できる関数
ちなみに、ややマニアックですが DCOUNTA関数やDSUM関数、DGET関数といったデータベース系の関数は、割と厳密に一致を判定してくれます。
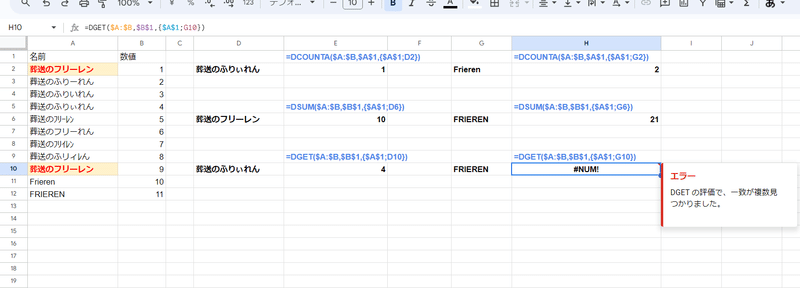
大文字と小文字は同一判定となるものの、ひらがな・カタカナ、全角・半角に関しては区別してくれるので、だいぶ精度はマシになってますね。
対象とするデータによるので完全な代わりとはなりませんが
COUNTIF → DCOUNTA
SUMIF → DSUM
VLOOKUP、XLOOKUP → DGET
このように代替して 検索(一致)の精度を高めることが出来るケースもあります。
配列化によって一致判定を割と厳密にする方法と効果
でも、DSUMやDCOUNTAのデータベース系関数って ちょっと使い方にクセが強くて苦手な人も多いんですよね。。型がしっかりした表じゃないと使えないことも多いし。。
というわけで、今回紹介する {魔法} が効果を発揮します!
範囲を配列にする方法
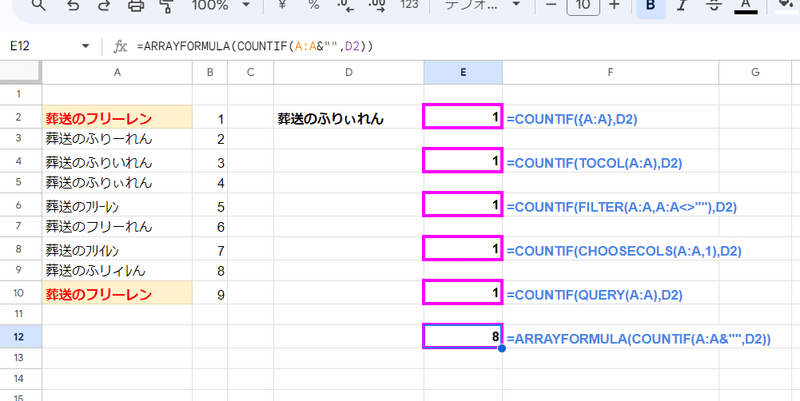
魔法を使う為の 配列化ですが、色々な方法があります。
そもそもの セル範囲と配列の違い・・・について、厳密に書こうとすると難しいので、ここでは簡単に
セル範囲
- 実際にそのスプレッドシート上に存在する範囲
- 位置情報をもっており ROW関数やCOLUMN関数で 行や列を取得できる
配列
- シート上ではなく計算領域(バーチャル空間)に存在する
- 位置情報をもたない為、OFFSET関数やその他一部の関数で使用できない
- シート上に書き出すと複数セルに展開される(スピルする)
※要素が1の配列もあり、その場合は単体セルとなります
こんな認識でよいかなと。(識者にはツッコまれそうですが。。)
で、範囲 → 配列 の変更は 1列データなら TOCOL関数を使ったり、複数列複数行なら FILTER関数やQUERY関数を使う方法もあるんですが、
一番簡単な方法は
範囲 A:A → 配列 {A:A}
このように 中カッコ { } で括る方法です。
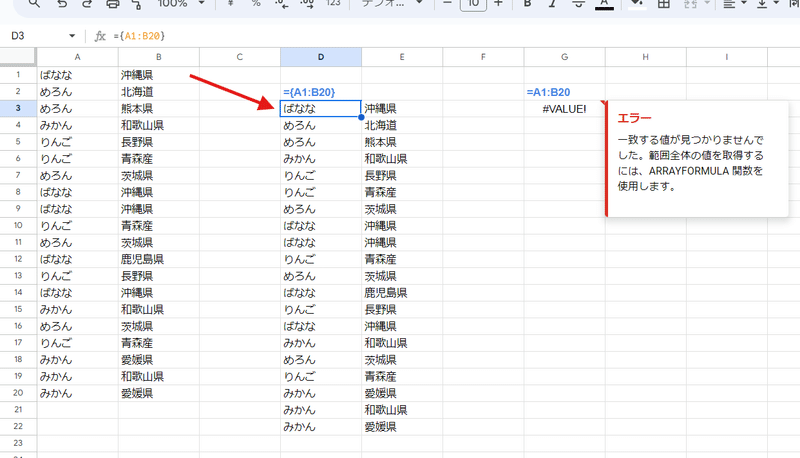
この 中カッコによる配列化は、Googleスプレッドシートでは活用の場は多く、たとえば Googleスプレッドシートは
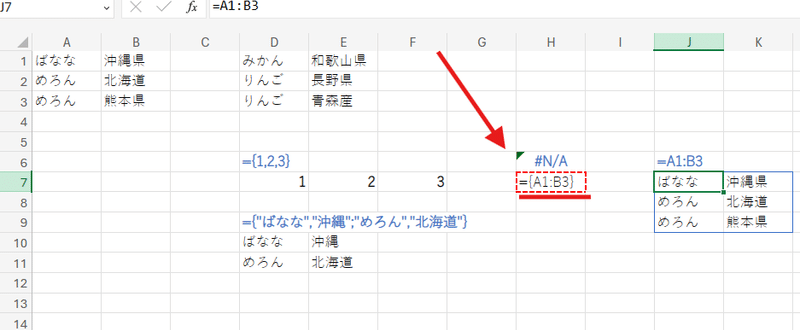
=A1:B20
といった形で1つの式で 範囲を出力しようとするとエラーになります。
=ARRAYFORMULA(A1:B20)
もちろん、ARRAYFORMULAを付けて解決する方法でもいいんですが、もっと簡単に
={A1:B20}
これだけで、配列となるのでセルに展開されます。
そして、中カッコに カンマ、セミコロンを組み合わせた セル範囲・配列の 縦横の連結も 中カッコによる配列化の非常に便利な使い方です。
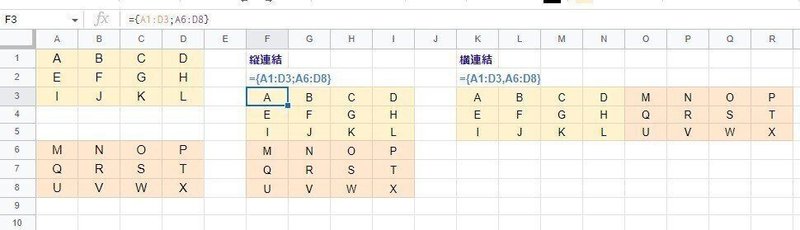
■縦方向の連結
={array1; [array2]; …}
■横方向の連結
={array1, [array2], …}
引数の array は セル範囲、配列 どちらでも可
ちなみに Excelの場合は、この中カッコによる セル範囲の配列化や範囲の連結は使えません。
Excelは 定数のみ配列として中カッコで扱える仕様になっています。
これ故に Excelは 新関数の VSTACK、HSTACKの登場で圧倒的に配列操作が便利になったわけです。
とりあえず、Googleスプレッドシートで 範囲を配列にする最も簡単な方法は、範囲 を { } 中カッコで括る(たとえば A1:B10なら {A1:B10} )と覚えておきましょう!
配列化で一致判定が変化する関数

範囲の配列化で 一致判定が厳密化する関数は、ズバリ 〇〇IF、〇〇IFS関数です。
■〇〇IF系関数
COUNTIF
SUMIF
AVERAGEIF
■〇〇IFS系関数
COUNTIFS
SUMIFS
AVERANGEIFS
MAXIFS
MINIFS
COUNTUNIQUEIFS
これら全てに効果があり、配列化すると 半角、全角、ひらがな、カタカナを区別した一致判定で結果を返します。
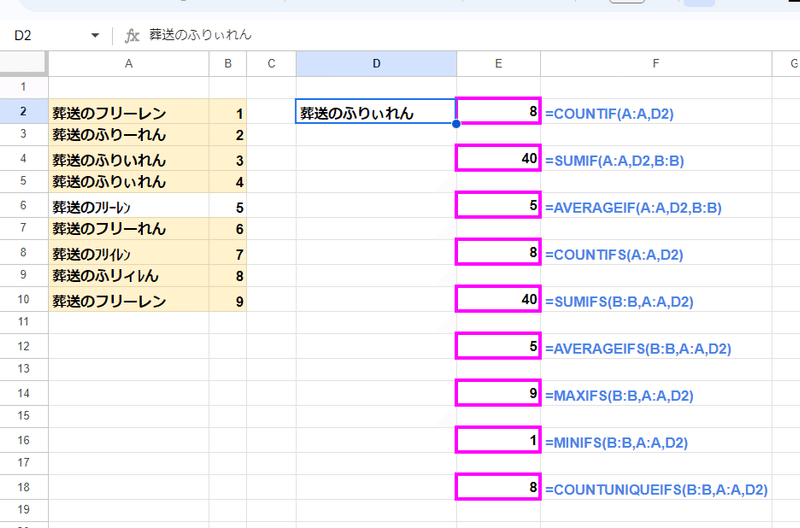
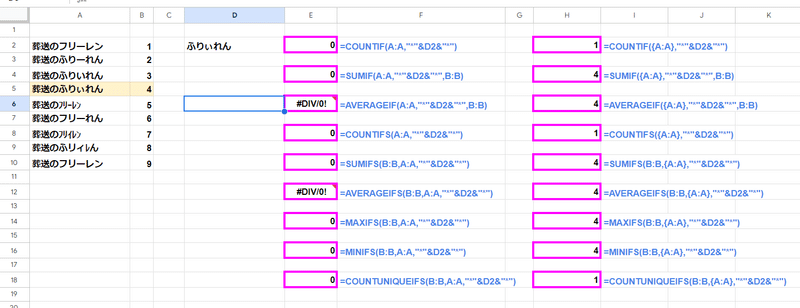
画像だと D2の値 「葬送のふりぃれん」を一致条件としていますが、範囲A:Aを対象とすると
葬送のフリーレン
葬送のふりーれん
葬送のふりいれん
葬送のふりぃれん
葬送のフリーれん
葬送のフリイレン
葬送のふリィレん
葬送のフリーレン
これら全てが「葬送のふりぃれん」と一致すると判定されてしまっています。
唯一、半角の ー が特殊な判定となる 葬送のフリーレン だけが一致と見なされていません。
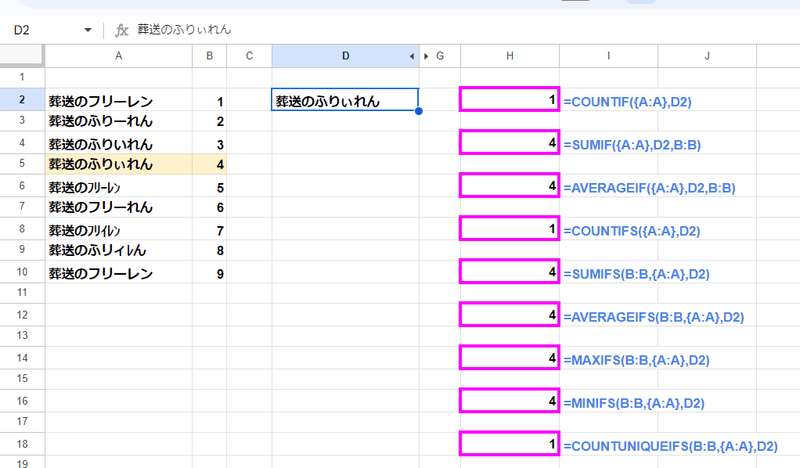
これを A:A を {A:A} とすることで、「葬送のふりぃれん」のみが一致と見なされ、全て結果が正しくなっているのがわかりますね。
前回紹介したマニアックな COUNTUNIQUEIFS関数にも、効果があるのは面白いです。
ちなみに SUMIFSなど 〇〇IFS関数の場合は、複数の条件を引数に設定できるので、配列化はそれぞれの範囲に対して必要になります。
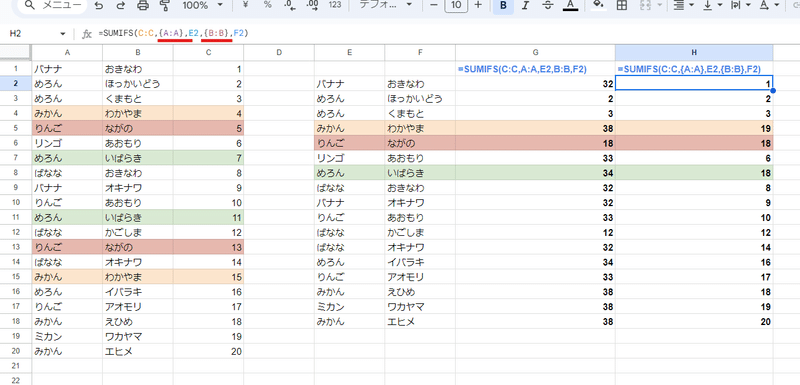
=SUMIFS(C:C,A:A,E2,B:B,F2)
▼
=SUMIFS(C:C,{A:A},E2,{B:B},F2)
COUNTIF や SUMIFS の緩い一致判定は ワイルドカードと組み合わせるとバグる
さらに、この緩い一致基準は ワイルドカードを使った 「含む」判定の時に非常に厄介だったりします。
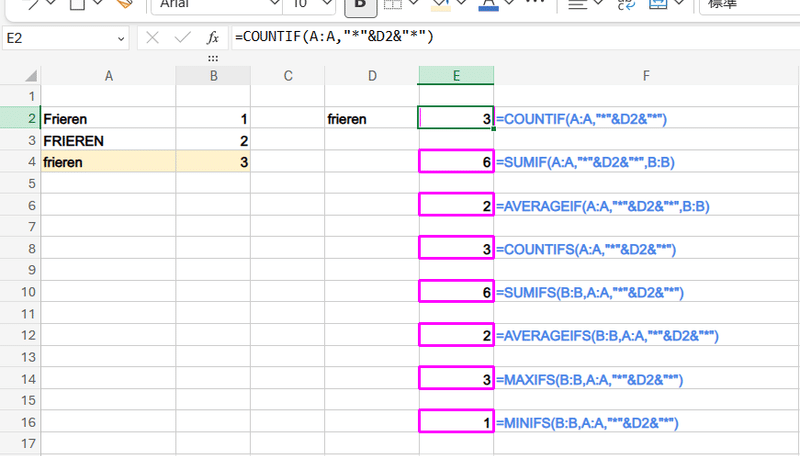
=COUNTIF(A:A,"*"&D2&"*")
↓
なぜか 結果が 0に??
範囲を指定した普通の〇〇IF、〇〇IFS関数を ワイルドカードを使った「含む」判定とした場合、範囲内で 検索値(D2)と完全に一致する値(ふりぃれん)より上に 緩い判定で一致と見なされる値(フリーレン)があると、一致するデータは 0となるバグがあります。
これはとんでもないバグです!
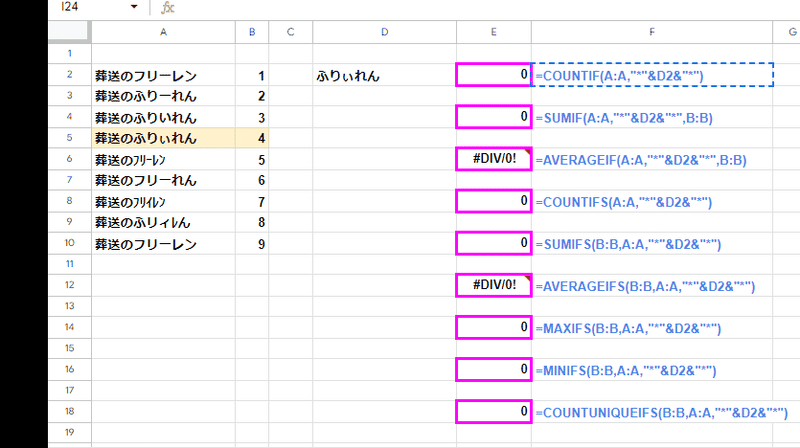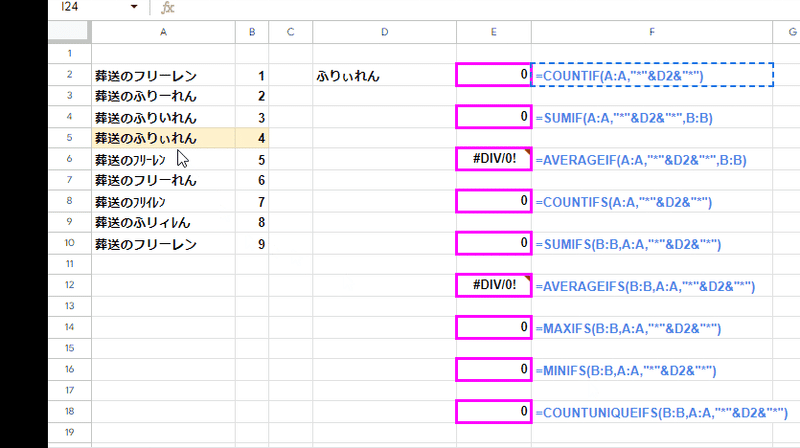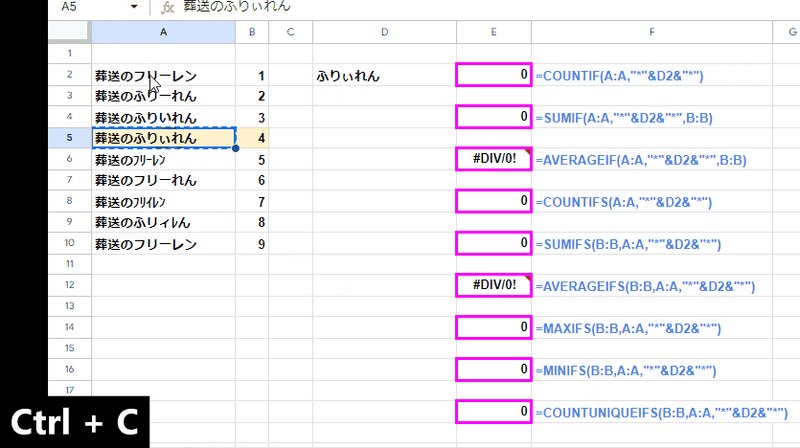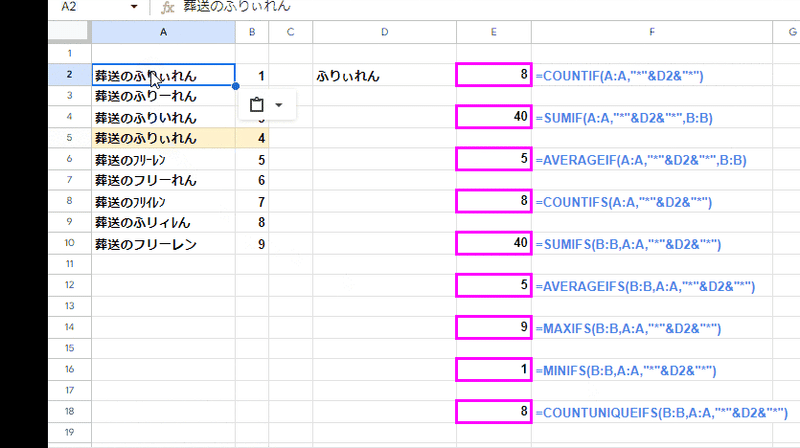
このように、範囲内で先に (上に)キーワードに厳密に一致する値を含むセルがあれば、緩い一致判定の結果が返ります。(これは正しい結果ではありません)
なんとも不思議なバグです。

しかし、このワイルドカードを使った「含む」を条件とした場合も、範囲を{ } で配列化することで、不具合は解消され 正しい結果を返してくれます。
これはもう、〇〇IF、〇〇IFS関数を使う場合は、配列化は必須と言えるんじゃないでしょうか?
× =COUNTIF(A:A,"*"&D2&"*") こうじゃなくて
〇 =COUNTIF({A:A},"*"&D2&"*") こっち!
〇〇IF,○○IFS系関数で 配列化による 一致判定厳密化を使った際の弱点
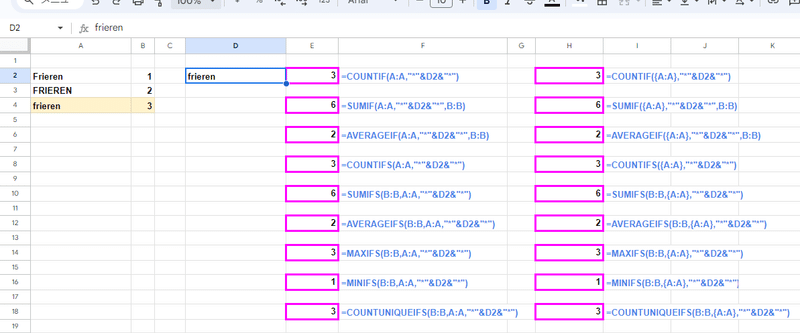
冒頭にも書いていますが、配列化による効果は 一致判定が「割と」厳密になることです。
範囲の配列化 + 〇〇IF、〇〇IFS
これによって、同一と見なされていた 全角・半角、ひらがな・カタカナ は区別できるようになりなす。
一方で、残念ながら 英字の 大文字、小文字は判別できません。
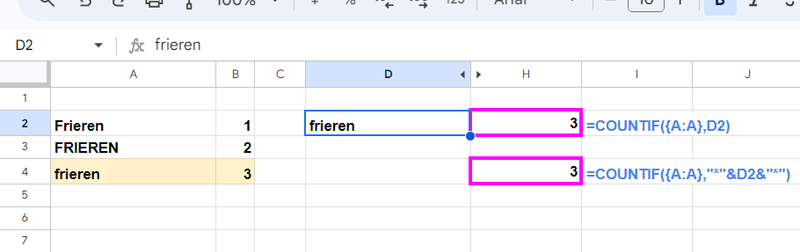
範囲を配列化したとしても、一致、 ワイルドカードを使った含む、どちらも大文字、小文字は同一と見なした結果が返ります。
ここが、EXACT関数やUNIQUE関数、QUERY関数などの 本当に厳格な一致判定が出来る関数との差です。
その為、「割と」厳密という表現をしています。
ただ、この仕様は Excelも一緒なんですよね。
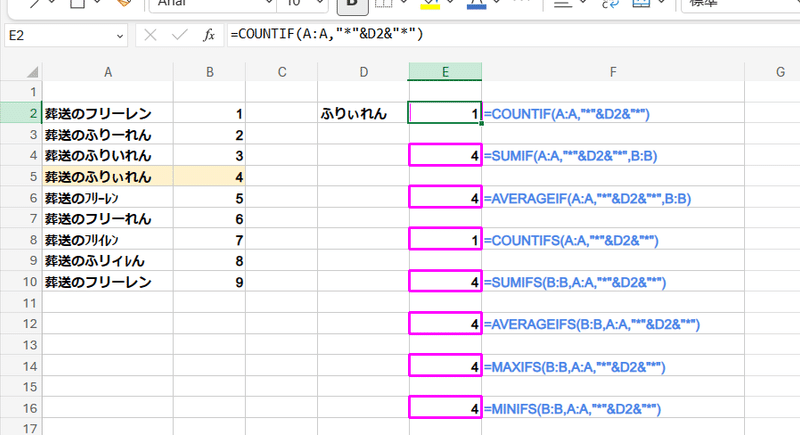
当たり前ですが、Excelのイコールによる一致判定や 〇〇IF、〇〇IFS の一致判定は、きちんと半角・全角、ひらがな・カタカナを区別してくれます。
しかし
Excelでもイコールや○○IF、〇〇IFS、VLOOKUP、XLOOKUPなどを使った場合、 大文字・小文字は同一として判定されてしまいます。
つまり Googleスプレッドシートの場合は、範囲を配列化すると、 〇〇IF関数、〇〇IFS関数 が Excelのものと 同じレベルの一致基準となる
ってことですね。
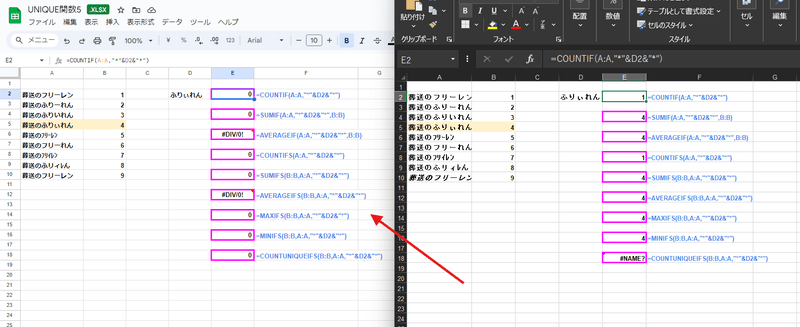
ちなみに当然ですが、ExcelをGoogleドライブに入れてブラウザで開いた場合は xlsxファイルであっても、Googleスプレッドシートの互換表示状態です。
COUNTIFやSUMIFS などの関数もGoogleスプレッドシートの挙動となります。
Excelとして開いていた時は正しい結果だったものが、誤った結果になったりエラーになってしまう場合もあるので注意しましょう。
配列化 + 〇〇IF,〇〇IFS関数の 活用例
COUNTIF やCOUNTIFS、SUMIFS の一致が厳密になるってだけでも十分に便利なんですが、その他の活用例にも触れておきましょう。
イコール一致の代わりに 配列化 + COUNTIF を使う
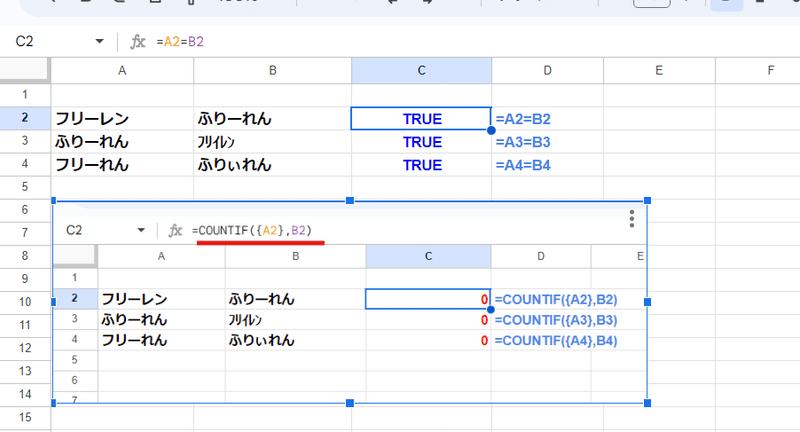
まず、Googleスプレッドシートの イコールによる緩い一致判定、これを配列化 + COUNTIFで置き換えることで、判定が厳密化されます。
=A2=B2 緩い判定で一致(TRUE)となる
▼
=COUNTIF({A2},B2) 割と厳密に判定し 一致(1)、不一致(0)を返す
一致だと 1、不一致だと 0 を返すので、これはそのままIF関数と組み合わせて TRUE,FALSEとして処理分岐に使えますね。
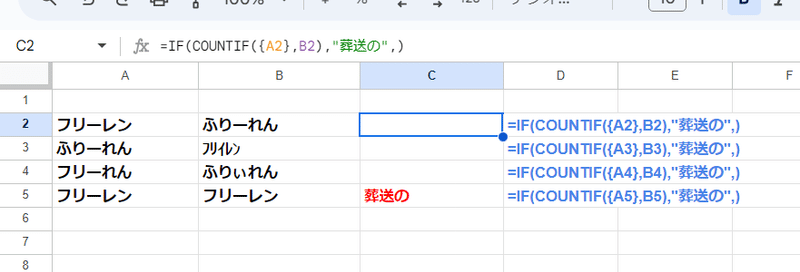
そして、「完全に一致する」を条件にしても、緩い一致判定となってしまう条件付き書式でも カスタム数式で
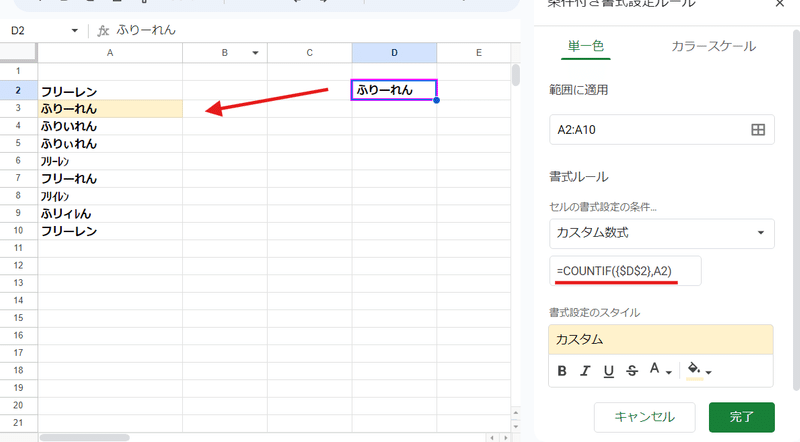
=COUNTIF({$D$2},A2)
このようにすることで、D2セルの値と (大文字・小文字の判定を除いて)厳密に一致したセルだけに書式を設定して色付けすることが出来ます。
※このケースだと =COUNTIF({A2},$D$2) でもよいんですが、条件付き書式は条件を適用するセルからの視点なので、固定の範囲 D2内に 条件 A2,A3,A4… と一致するものが幾つあるか?というのが本筋かなと考えます。
でも、この辺りの処理は正直 EXACT関数を使えばいいって話ですねw そっちの方が簡単ですし。
まぁ、あまり無いケースですが、大文字・小文字は区別したくないけど、それ以外は区別したいって時には有効かと思います。
リスト同士の比較で 配列化 + COUNTIFを使う
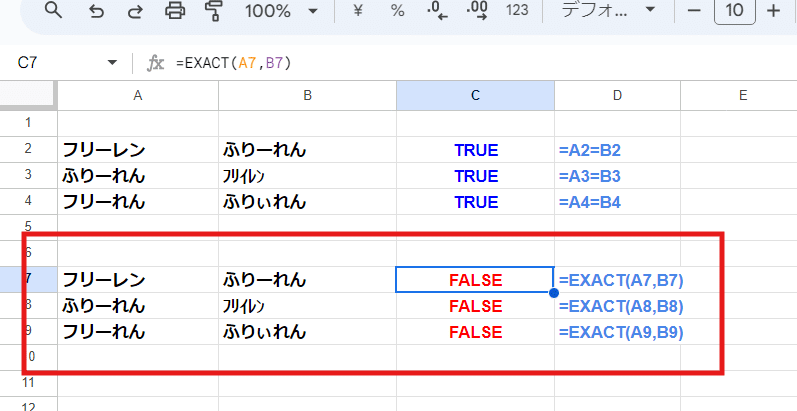
単純な一対一の比較であれば、わざわざ 配列化+COUNTIFに頼らなくても、より厳密でわかりやすい EXACT関数を使えば済む話です。
FILTER関数によって一致するデータを抽出する際、つまり 多対一の場合でも EXACT関数 +配列 で解決できます。
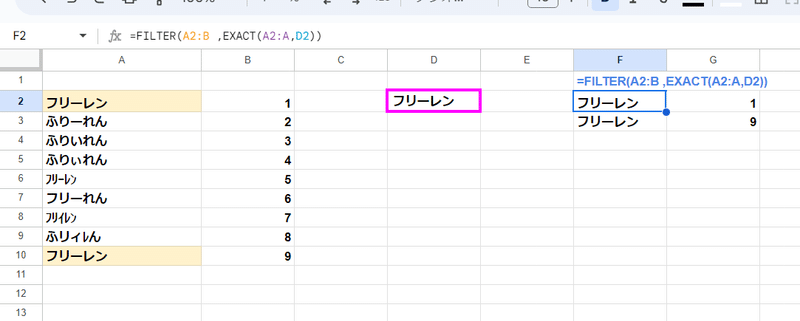
=FILTER(A2:B ,EXACT(A2:A,D2))
同じく 多対一 で「含む」を条件に 厳密な一致で 絞り込みをしたい場合は、FILTER関数の条件部分で FIND関数やREGEXMATCH関数を使うのもアリでしょう。
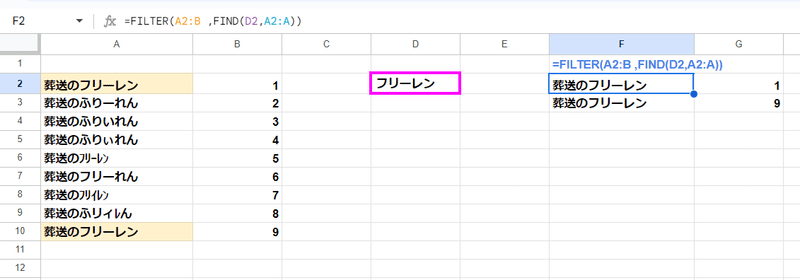
ただ、これらの関数で対応が難しいのが 多対多 のケースです。
たとえば、以下のように リストA(A2:B) のうち A列が リストBと重複するものを抽出したいといった場合、
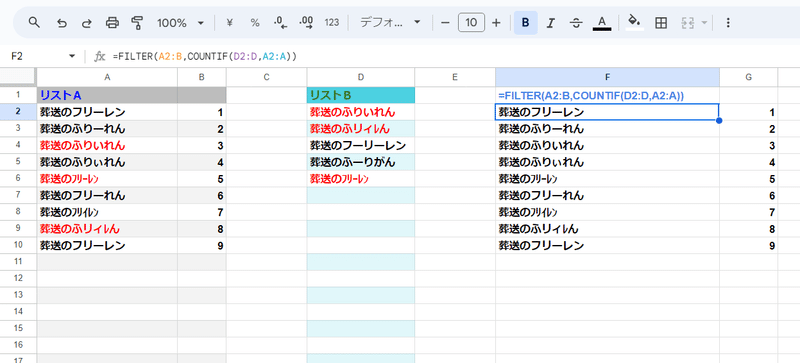
通常は
=FILTER(A2:B,COUNTIF(D2:D,A2:A))
このようにFILTER関数にCOUNTIF関数を組み合わせるのですが、上のような ひらがな、カタカナ、半角、全角が違うだけのデータが混在するデータだった場合、一致判定の緩さのせいで誤った結果を返してしまいます。
このような多対多を EXACT関数で処理しようとすると、なかなか難しい のですが 配列化 + COUNTIFの 厳密化テクニックを使えば
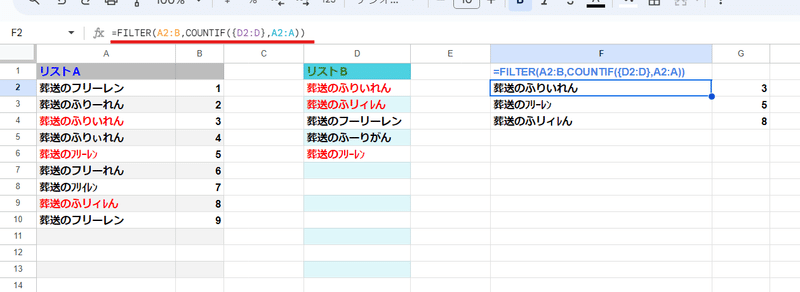
式をほぼ変えることなく
=FILTER(A2:B,COUNTIF(D2:D,A2:A))
▼
=FILTER(A2:B,COUNTIF({D2:D},A2:A))
これだけで解決できます!
リストBと重複するデータを条件付き書式で色付けしたい場合も
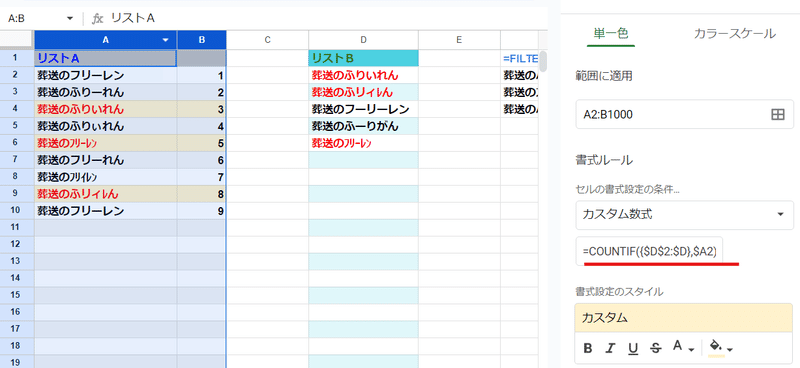
=COUNTIF({$D$2:$D},$A2)
このように配列化が使えます。
もちろん ワイルドカードを組み合わせれば、「割と厳密な一致」でリストBを 含む データを色付けしたり抽出したりも可能です。
この便利さ、実感いただけたでしょうか?
もちろんこれ以上の 英字の大文字・小文字も区別する 厳密な一致判定が必要な場合は EXACT関数や UNIQUE関数が必要になります。
これは 次週予定している UNIQUE関数の超応用例シリーズで 触れていきたいと思います。
配列化効果は VLOOKUPやXLOOKUPには効かない
配列化によって、〇〇IFや〇〇IFS系関数は 一致が厳密になり 便利に使えることがわかりました。
しかし、逆にこれ以外の関数には残念ながら効果がありません!(検証した限りでは)
特に残念なのが、VLOOKUPやXLOOKUP、MATCH、XMATCHといった検索系関数で効果がなかったことです。
検証:配列化 + VLOOKUP、XLOOKUP、MATCH、XMATCH
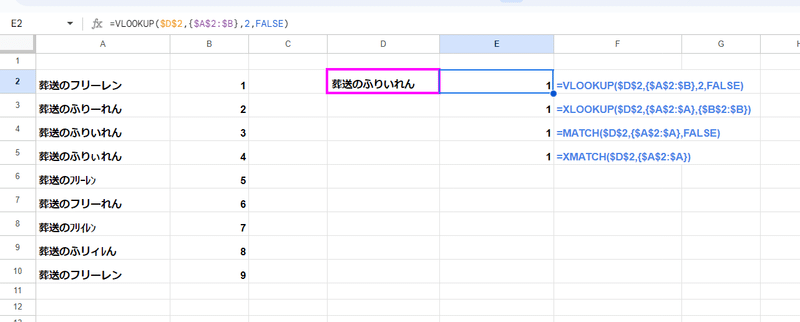
このように 第2引数の検索範囲を {A2:A} や{A2:B} と配列化しても、一切効果はなく 範囲の1行目(A2セル)の 「葬送のフリーレン」を「葬送のふりいれん」と一致と判定してしまいます。
はだしのゲンだったら「ギギギ・・・」となっちゃいます。
無理やり、これら VLOOKUPやXLOOKUP、MATCH、XMATCHに 配列化+COUNTIFを組み合わせて処理できなくもないです。
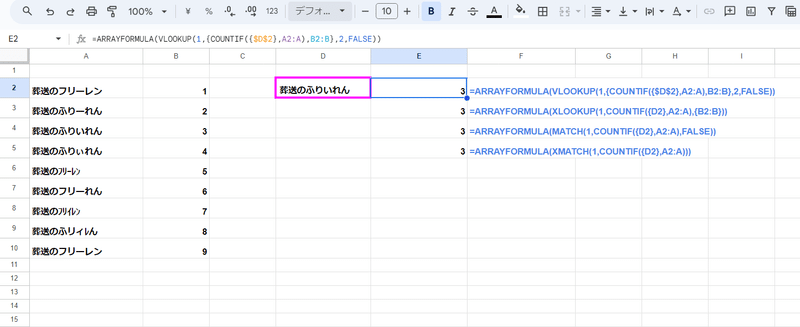
=ARRAYFORMULA(VLOOKUP(1,{COUNTIF({D2},A2:A),B2:B},2,FALSE))
=ARRAYFORMULA(XLOOKUP(1,COUNTIF({D2},A2:A),{B2:B}))
=ARRAYFORMULA(MATCH(1,COUNTIF({D2},A2:A),FALSE))
=ARRAYFORMULA(XMATCH(1,COUNTIF({D2},A2:A)))
でも、本来の検索キーをCOUNTIFの範囲に使う
COUNTIF({D2},A2:A)
という記述がちょっとわかりづらいですし、この部分の配列処理のために ARRAYFORMULAが必要になるんで式が長くなるしで イマイチです。
諦めて素直に EXACT関数 を組み合わせた方が良さそうですね。
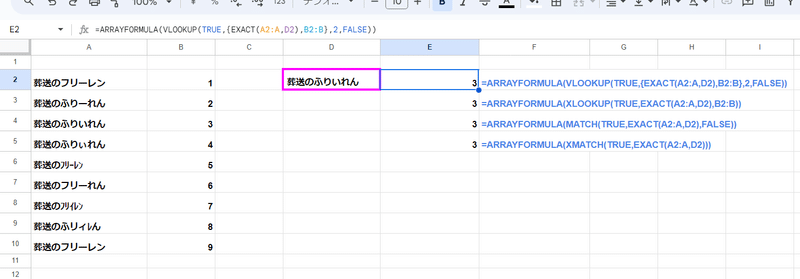
=ARRAYFORMULA(VLOOKUP(TRUE,{EXACT(A2:A,D2),B2:B},2,FALSE))
=ARRAYFORMULA(XLOOKUP(TRUE,EXACT(A2:A,D2),B2:B))
=ARRAYFORMULA(MATCH(TRUE,EXACT(A2:A,D2),FALSE))
=ARRAYFORMULA(XMATCH(TRUE,EXACT(A2:A,D2)))
VLOOKUP、XLOOKUPの代わりに DGET関数を使う方法
使い方にクセがありますし 見出し行が必要なんですが、厳密な一致で VLOOKUPのようなことがしたい場合、DGET関数を使う方法もあります。
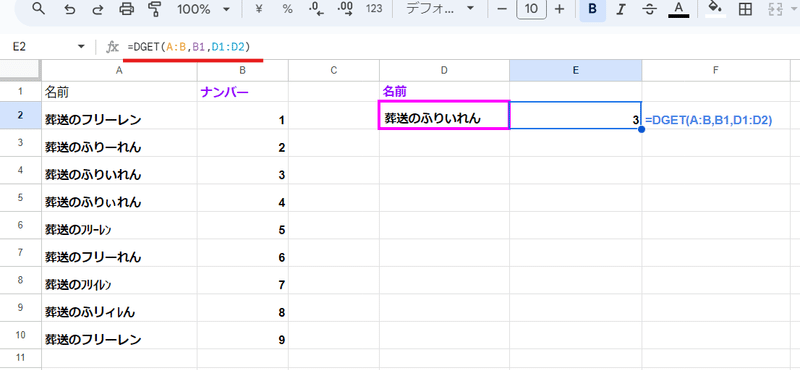
=DGET(A:B,B1,D1:D2)
前半でも触れましたが DGET関数やDCOUNT関数、DSUM関数といったデータベース系関数は、Googleスプレッドシートにおいては 割と厳密な一致判定となっています。
データベース系関数の中で挙動が VLOOKUP、XLOOKUPに近いのが、この DGET関数です。
DGET(データベース, フィールド, 条件)
でも、式の書き方が独特でわかりづらいんですよね。。
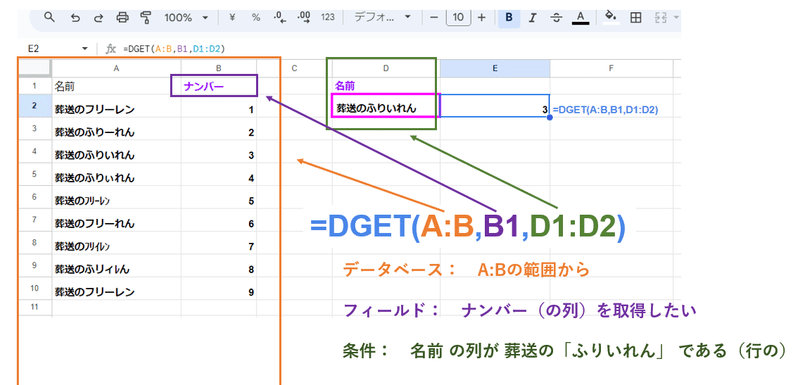
特に 条件の箇所は { "検索列の見出し" ; "検索キー" } と縦連結の配列を必要とする部分が、なかなか慣れません。
とは言え型にハメさえすればよいわけで、見出し行がなかったり、セル上には検索キーしか無い場合でも
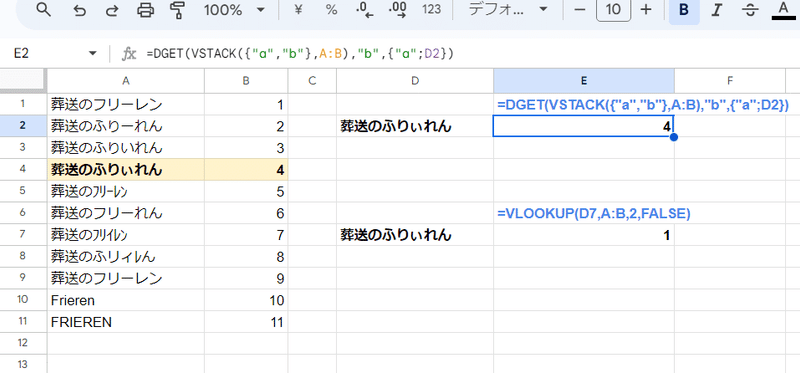
=DGET(VSTACK({"a","b"},A:B),"b",{"a";D2})
こんな感じで式の中で 配列化して適当に見出し行を付ける方法もあります。
ただし、DGET関数は 範囲内で検索キーと一致するデータが2つ以上あった場合、エラーを返すという注意点があります。
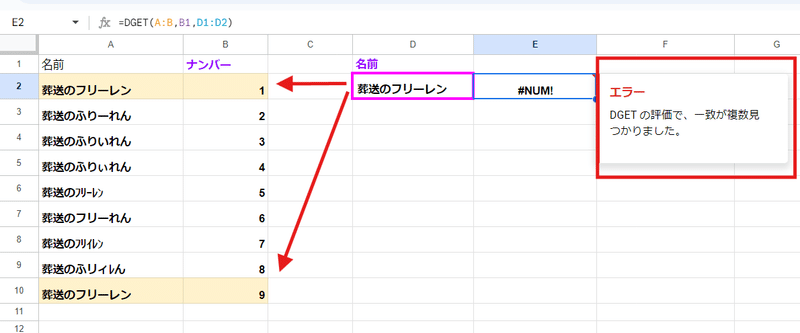
VLOOKUPやXLOOKUPのような 最初に見つかった結果を返すといった処理は出来ません。
結局、VLOOKUP、XLOOKUP、MTCH、XMATCH に関しては、緩い一致判定を厳密化する 方法は、これがベストというものは無く、状況によって
VLOOKUPやXLOOKUPに EXACT関数を組み合わせる
DGET関数を使う
QUERY関数を使う
といった方法を使い分けるしかなさそうです。
「ゆるゆるだっていいじゃない、無料だもの。」みつを
今回は、Googleスプレッドシートの 一致判定の緩さと、COUNTIFやSUMIFSなど 〇〇IF、〇〇IFS系関数に限られますが、判定を割と厳密にする魔法のテクニック「中カッコによる配列化」を紹介しました。
ただ、最後に触れた通り COUNTIFやSUMIFS以上によく使う関数の VLOOKUP、XLOOKUP、MATCH、XMATCHで効果がなかったのは残念。
たしかに「これだから Googleスプレッドシートはクソだな」と Excel派から言われてしまいそうなクソ仕様ではありますが、前向きにとらえてみてください。
Excelには ひらがな・カタカナ、全角・半角、大文字・小文字、さらには 「フリーレン」と「フリイレン」のように 伸ばし棒と母音を一致と判定するような関数はありませんよね?
さらに、シート関数を組み合わせて 上記のような 緩い判定で一致と見なす数式を作るのもかなり難解ですよね?
と、考えれば Excelには出来ないことが Googleスプレッドシートだと出来るんだ! って気になってきませんかw
まぁ、さすがにこれは無理があるかもしれませんが、
「ゆるゆるだっていいじゃない、無料だもの。」みつを
この一言で全て解決するんでないかなとww
まぁ色々工夫すれば「道はひらける」わけですし、不便を楽しむのも良いもんです。(アップデートで改善された時に盛り上がりますしね)
次回は UNIQUE関数シリーズに戻って、UNIQUE関数を使った超応用例について 書きたいと思います。
この記事が気に入ったらサポートをしてみませんか?