
Python グラフ作成 seaborn

seabornを使えば簡単にデータの可視化が可能となる。1変数から多変数間の分布まで可視化する関数を列挙する。データはirisを使用。
# モジュールインポート
print("実行環境")
import pandas as pd
import numpy as np
import matplotlib as mpl
import matplotlib.pyplot as plt
import seaborn as sns
import itertools
!python -V
print('pandas ' + pd.__version__)
print('numnpy ' + np.__version__)
print('matplotlib ' + mpl.__version__)
print('seaborn ' + sns.__version__)実行環境
Python 3.8.5
pandas 1.1.3
numnpy 1.19.2
matplotlib 3.3.2
seaborn 0.11.0# データ読み込み
df = pd.read_csv('iris_raw.csv')
# データの確認
display(df.head())
#seabornの標準設定を読み込み
sns.set()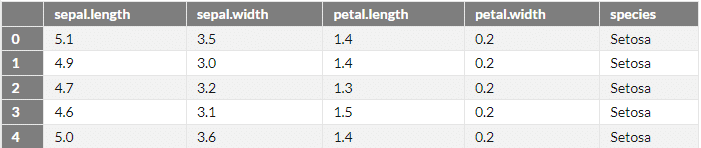
1変数の分布
を可視化
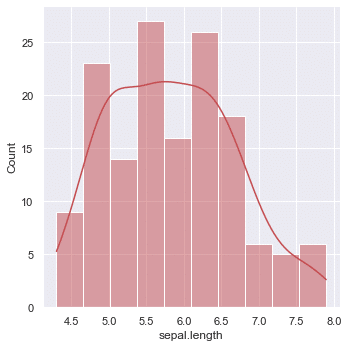
ヒストグラム化 displot
In [26]:
sns.displot(df['sepal.length'], #データの指定
kde=True, #カーネル密度分布の表示
bins=10, #ビンの数指定
color='r', #グラフ色
alpha=0.5 #透明度
);
2変数間の分布を可視化
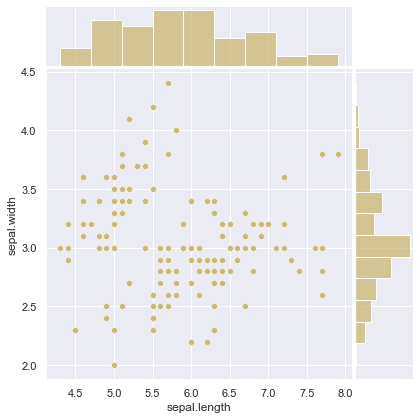
散布図とヒストグラムの同時可視化 jointplot
sns.jointplot(x=df['sepal.length'],y=df['sepal.width'], #x,yのデータ
kind='scatter', #未指定で'scatter'
#{'scatter' : 散布図,
#'reg': 散布図と回帰直線,
#'resid': y 軸に回帰直線からの残差 (誤差) を出力する,
#'kde': カーネル密度推定を用いた等高線風の図
#'hex': 六角形のヒートマップ }
space=0.05, # 散布図とヒストグラムの隙間
color='y'
# hue='species' # kind='scatter'のみ使用可、species列の名称でカテゴライズ
);
散布図と回帰直線の同時可視化
数値データとカテゴリデータが混在するときに役立つ。speciesをcol(横並び), row(縦並び), もしくはhue(1つのグラフ枠にまとめる)で指定する。
sns.lmplot(x=df.columns[0], y=df.columns[1], data=df, # データの設定
col="species",
palette='Set3'); 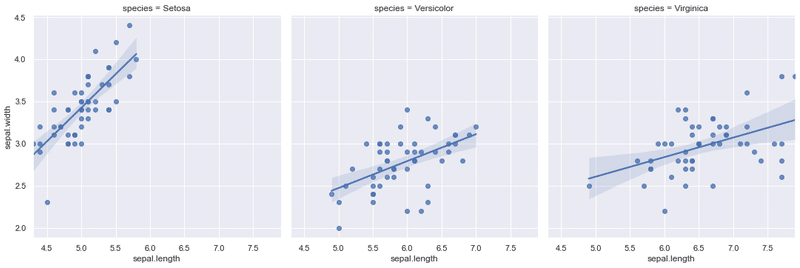
カテゴリー別に分布を可視化
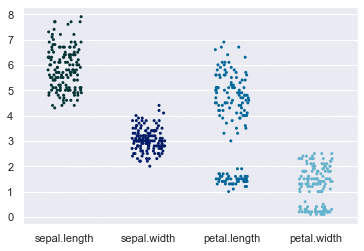
データ毎の分布 stripplot
データセットの各列のデータの分布を可視化する。各データの偏りが確認できる。
sns.stripplot(data=df,
jitter=0.2, # 横の広がり調整
palette='ocean', # カラーセッティング
orient='v', # 縦横切り替え {'h', 'v'}
size=3, # プロットの大きさ
); 
カテゴライズした分布 stripplot
上のstripplotで描いたsepal.lengthをさらにspecies列でカテゴライズする。
sns.stripplot(y=df['sepal.length'],x=df['species'], # x=カテゴリ, y=データ
jitter=0.05, # 横の広がり調整
palette='ocean', # カラーセッティング
orient='v', # 縦横切り替え {'h', 'v'}
size=3); # プロットの大きさ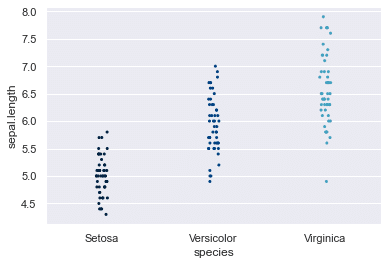
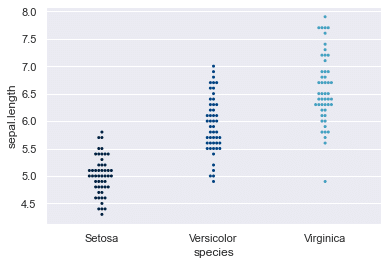
カテゴライズしてデータが重ならないように分布を描く swarmplot
stripplotとほぼ同じ。個人的にはこちらのほうがどの辺にデータが固まっているか見やすい。
sns.swarmplot(y=df['sepal.length'],x=df['species'],
palette='ocean', # カラーセッティング
orient='v', # 縦横切り替え {'h', 'v'}
size=3, # プロットの大きさ
);
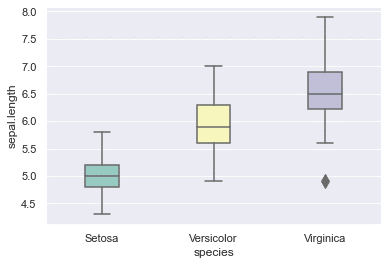
箱ひげ図 boxplot
データを扱う仕事をしていると必ずと言っていいほど使うことになる。見方を知っている人に対して分布の説明をする際に非常に便利。
sns.boxplot(y=df['sepal.length'],x=df['species'],
palette='Set3', # カラーセッティング
width=0.3, # 箱の横幅
fliersize=10 # 外れ値プロットサイズ
);
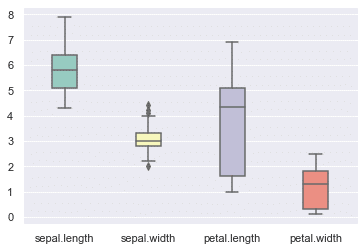
データの設定をデータフレーム全体にすればデータ各列の箱ひげ図となる。
sns.boxplot(data=df,
palette='Set3', # カラーセッティング
width=0.3, # 箱の横幅
);
多変数の分布を可視化
総当たりで各列毎の散布図を作成 pairplot
sns.pairplot(data=df, #データの設定
palette='ocean');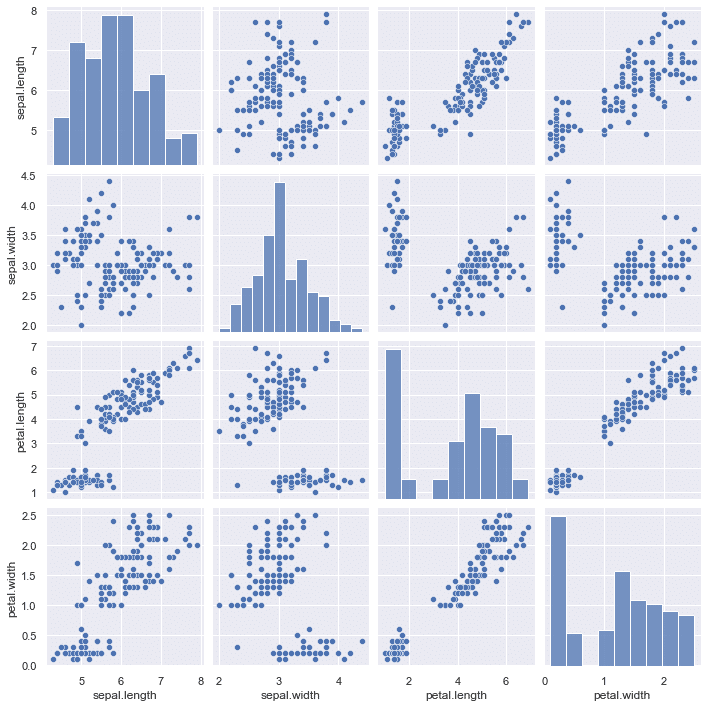
pairplotをカテゴライズしてプロットする。さらに全体の分布が見えやすくなる。
sns.pairplot(data=df, #データの設定
hue='species', #カテゴライズの設定
palette='ocean');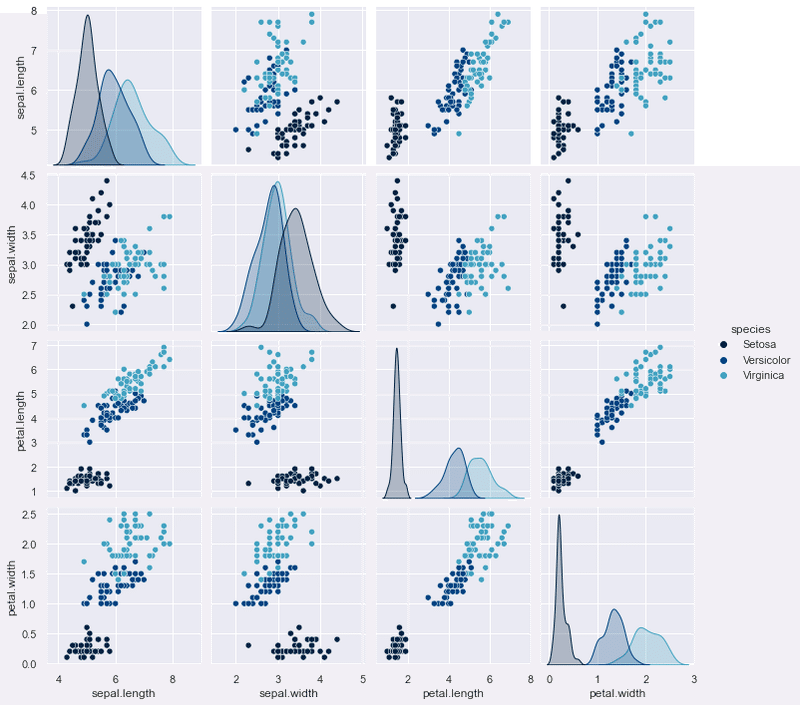
sns.pairplot(data=df, #データの設定
hue='species', #カテゴライズの設定
kind='reg',
diag_kind='kde',
palette='ocean');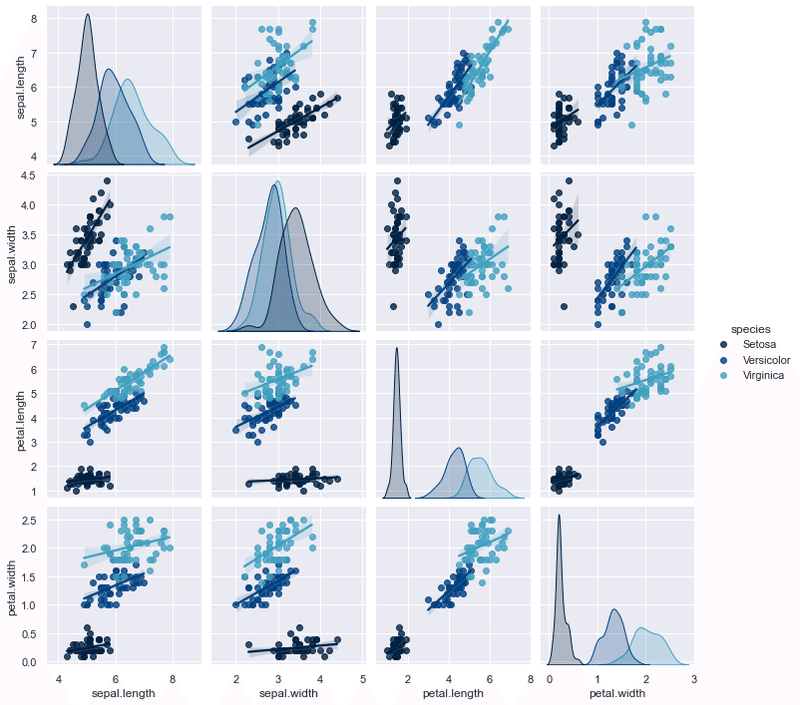
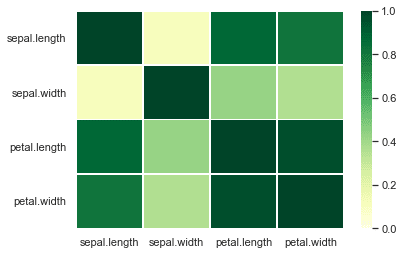
ヒートマップの可視化 heatmap
データ全体を総当りで相関関係を調べることができる。
In [47]:
#相関係数の一覧を表示
display(abs(df.corr())); #正負を区別しないためにabsを付加
上の表の結果をカラーマップにすることになる。
sns.heatmap(data=abs(df.corr()), # データの指定
vmin=0, vmax=1, # ヒートマップの最小最大値
linewidths=0.5, # 色の境界に引く線の太さ
linecolor='w', # 色の境界に引く線の色
cmap='YlGn' #
);
この記事が気に入ったらサポートをしてみませんか?