
ユーザー数1500人超えの 自作Webアプリを、2ヶ月でクローズさせた話。

2024年5月31日に、4月1日よりサービスリリースしていたPDF翻訳アプリ「Indqx」のサービス提供を終了させました。
本記事では、PDF翻訳アプリIndqxをなぜ作ったのか?
なぜ、2ヶ月でサ終了させたのかを開発者である私が、書き残したいと思っています。
1.PDF翻訳アプリIndqxとは?



Indqx翻訳は、論文読者向けのPDF翻訳Webアプリ。
論文特化の翻訳サービスで、DeepL翻訳+自作のPDF翻訳エンジンにて、PDFを翻訳します。それだけ!
サービスURL(サイトは残してるけど、サーバー課金を切ってしまったので、開くのにすごく時間が掛かる)
https://indqx-demo-front.onrender.com/
2.何がすごいの?
2-1.すごい所①「PDFフォーマットが崩れない」
ご存知の通り、既にPDFを翻訳できる翻訳サービスはリリースされている。しかし、既存のDeepL翻訳や、Google翻訳でPDFを翻訳した際、PDFからテキストおよび画像を、順番に取得し、翻訳してしまうため、PDFのフォーマットや文字の配置が崩れてしまう。
フォーマットが崩れるのは、一般的なPDFを読むうえでは問題にならないが、論文等レイアウトが大事になるPDF翻訳においては、問題となりうる。
せっかく翻訳したのに、原文との照らし合わせと時間がかかる、読みづらい、表の意味が変わってしまう等の問題が起きる。(論文は原文と翻訳文を照らし合わせながら読むため)
Indqx翻訳では、論文のフォーマットを崩さず翻訳する事ができる。
2-2.すごい所②「本文検知技術」


更に、独自の本文認識技術を用いて、本文検知を行い、本文のみを翻訳することで、翻訳精度を高める工夫を行っている。
またこの本文検知により、数式や図、表等が翻訳されないため、式や図が翻訳されて意味が変わってしまう問題にも対処している。
(本文検知を行うと、本文以外の余計な箇所(ページ数、注釈等)が翻訳データとして入らないため、翻訳精度改善および翻訳コスト軽減につながる)
2-3.すごい所③「ページをまたいでも一括翻訳」

更に更に、DeepL翻訳は、翻訳の際、改行検知機能があり、有効にしていると、行ごとに翻訳してくれる機能があるが、、、
改行データごと(ブロックごと)に翻訳をすると、各行の文章が完結していることが前提となるので、1文が2ブロックにまたぐようなブロックの翻訳時、ブロック間の行間を正しく翻訳できない問題がある。
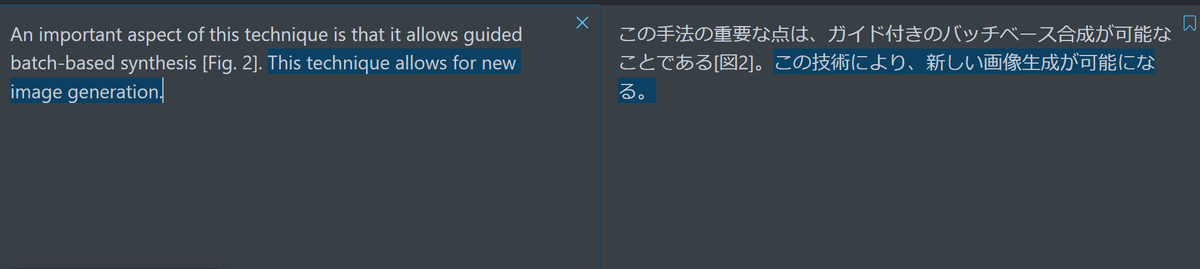

Indqx翻訳では、1文が複数ブロックに分割されていたとしても、1文として翻訳し、翻訳後にブロックサイズにテキストを分割する。これによりページまたぎ等での翻訳精度の低下を防止している。
(何がすごいって? 翻訳文を1つのブロックに収めるために、フォントサイズを逆算させるだけでも大変なのに、これが複数ブロックで、一貫したフォントサイズを計算する+文章の分割位置も計算して決めないといけない!で大変なのよ!スペック制限も翻訳時間制限もキツイんだから!)
2.なんで作ったの?
私事だが、今年、3月よりフリーター(創業から5年間努めていたベンチャーを辞めた)となったので、生活費を稼ぎたかったという都合もある。
しかし、1番の目的は、「論文を気軽に読みたかった」それに尽きる。
Open AIから、davinci(GPT3.5の前)が発表されてからLLMを触り始めた私。
当時、AITuberの開発にのめり込んでおり、LLMの精度を向上させる最もの近道は論文から最新情報を収集し実装することだった。
しかし、論文はもちろん英語。学がなく、英文が読めるわけでない私は、翻訳機を用いで1本ずつ読むことになるけど、いかんせん効率が悪すぎる。
論文1本読むのにDeepLで翻訳して、Acrobatで編集、論文の日本語版を作って、読み上げアプリに入れて移動中に聞く。翻訳工程だけで、1時間ほどかかる。効率が悪すぎるので、翻訳アプリを自分向けに作ろう!と思って、Xでつぶやいたら、バズった。

なら、自分だけではなく、サービスリリースをしようと言うことで、作ったのが今回のIndqx翻訳となる。
(ちなみに、本人は元々機械畑の人間なので、ウェブアプリを作ったことがないどころか、ウェブサイトすらまともに作ったことがなかった。。)
3.結果はどうだったの?
結果から先にいうと、サービス開始(3月30日)からサービス終了(5月31日)までで、
アクテイブユーザー数
(同一ユーザーから複数アクセスあっても1回とカウントされる)
1,688人

総リクエスト数
(翻訳リクエスト数)
2,266回(たぶん)

であった。

アクセス経路が、ほとんどがソーシャルメディア(1,452)からであり、その次がダイレクト(525)なことを考えると、健闘した結果といえる。
(検索での流入はわずか65)

SNSでツィートがバズった時期を除いた期間でアクセス数を見てみると概ね1日あたり15ユーザー程度で推移していることがわかる。
1日のリクエストについても20-25リクエストで推移していた。
4.どうしてサ終するの?
4-1.表の理由 それは金!
表の理由は、身も蓋もないが、
稼げないから である。
Indqx翻訳は当初、翻訳毎に手数料を頂くことで、収益化しようと考えていた。(2ヶ月の提供期間は、手数料無料)
具体的には、「DeepLの翻訳コスト+手数料=サービス利用料」とし、ユーザーはコインを課金し、サービスの独自通貨にて、翻訳料金を支払うビジネスモデルである。
しかし、サービスを2ヶ月提供してみてこのビジネスモデルが破綻しているのに気づく、問題は単価の安さ。
DeepLでは、概ね5ページの論文を翻訳するのに60円の翻訳コストが発生する。翻訳代金と同額の手数料を乗っけたとして、ユーザーは5ページ翻訳するのに120円を支払う。
このモデルの場合、1翻訳あたり60円の利益。
課金サービス開始後も課金前と同じ、リクエスト数が維持されるとして(希望的な観測)、月あたり利益見込みは
750リクエスト x 60円 = 45,000円
そこにサーバー料金がかかる、
フロントエンド $7 + バックエンド $25 + SQL $7 + B2 $6 = $45(7,100円)
つまり純利益(人件費等考えない)は、
「37,900円」
となる。キツくないか。。
この金額だと、1ヶ月あたり、工数1.5日で赤字転落である。更に、リクエスト数が増えると、サーバー費用が指数関数的に増えるオマケ付きなので、リクエスト数が増えてもスケールしないビジネスモデルとなる。
「バックエンドの$25ドルが高い!もっと低スペの安いサーバーで動かせ!」と言われるかもしれないが、
バックエンドレンタルサーバーのスペックは1CPU 2GB RAMと複数ユーザーの文章処理をやらせるには、かなり非力な環境で動作させている。(2GB RAMはiPhone 6sと同じ)
今どきの激安PCでも、RAM 8GB、4スレッドが当たり前だというのに。。。

サブスクにして、
1ユーザー月1000円で無制限で翻訳できるビジネスモデルしても良かったが、、PDFファイルのページ数は変動しやすいし(サービス期間に1リクエストで100ページものPDFが送られたこともある)、
数人のヘビーユーザーの出現で、簡単にビジネスが崩壊しそうな世界線が見えたのでやめた・・・
(サブスク解禁してしまうと簡単にサ終することもできなくなる。。)
4-2.裏の理由 使いづらい!
「なんで作ったの?」で述べた通り、
このサービスを作った理由は、
「自分が、気軽に、論文を読みたいから。」
である。しかし、実際にリリースしたあと、デバッグ以外で自分で使った回数は数える程度。使っていない。。
元々は、自分向けに作っていたPythonスクリプトをWebアプリ化してリリースさせたアプリ。
にも関わらず、サービスリリース+収益化が目的化してしまい、リリース後に自分が理想としていた効率化と異なることに気づく。

あ、ありのまま起こったことを話すぜ!
『俺は元々、論文をタブレットで気軽に読みたかったんだ。。。
だが、気づいたら、PDF翻訳しかできない上に、ブラウザで叩かないと翻訳できない不安定なクソシステムが完成していた!』
な、何を言っているのか わからねーと思うが…..
つまり、
「手段が目的になっている」
状態になってしまった。。
チーム開発あるあるだけど、個人でやらかすかー

一応、再現性を確認するために
なぜ手段が目的化したか考察すると、元々開発していたスクリプトがPythonベースであったため、Pythonシステムをユーザーが環境インストールせずに利用するにはWebアプリ化する必要があった。(Pythonの実行ファイル化がヒジョーに難しい)
そのため、サーバーレンタルでのWebアプリ化を計画した流れである。
フロントエンド:Svelte Kit(未経験)
バックエンド:Python
RDBMS: PostgreSQL
オブジェクトサーバー: BackBlaze
の構成になったわけ。
本来であれば、開発前検討にて、開発言語を吟味すべきであったけども、私自身がPython以外まともに書けないこと、Webアプリのフロント側、Svelte Kitの開発工数を甘く見ていたことがあり、今回の構成となってしまった。。
5.何が駄目で、どうすればよかったの?
だめだったー!では芸がないので、今回のような2ヶ月で撤退サ終とならないように、何が駄目だったのかを、具体的に上げていこう!
5-1.運用コストの見積もりミス
Webアプリ開発となった時点で、ランニングコストの見積もりを行っていたが、このランニングコストの見積もりが甘々だった。
初期の案では、フロントエンドは無料サーバーを利用し、バックエンドのみ最低限課金。SQLも無料で運用し、オブジェクトストレージも無料枠で済ます予定だった。そのため試算では、
フロントエンド $0 + バックエンド $7 + SQL $0 + B2 $0 = $7(1,100円)
であり、19リクエストの翻訳がリクエストされれば、利益が出る計算であった。
しかし、この試算には、ミスが複数ある。
Renderのフロントエンド$0プランではSEO対策ができない
Renderの0円プランは、ホビー開発者向けプランであり、レスポンスが遅くなる+低スペック環境の条件で無料で提供されていた。開発中のWebアプリのフロントエンド処理は、表示処理程度であったため、0円の低スペック環境でも十分に動作し、レスポンスについても不便だが無視できると考えていた。そう、
レスポンス速度(表示までの時間)は遅いサイトがGoogle検索に表示されないという問題を除けば。。。。そう、みんなご存知SEO対策。
SEO対策にはいろいろな方法があるが、表示までのレスポンス時間が長いサイトは、SEO対策以前の問題で、検索で表示されることはほとんどないのである。。。
そのため、サービス化するには、最低課金の$7プランに入らざるおえなかった。。バックエンド側コストの見積もりミス
本Webアプリは、PDFを翻訳するサービスであるため、PDFデータを一旦メモリー領域に保管し、DeepLで翻訳後、再度PDF化するプロセスが必要だった。その仕様上、翻訳処理には比較的大きなメモリー領域が必要となるシステムとなっていた。(もちろん事前にメモリー使用量を見積もっており、5リクエストで250MBを超えない程度であったため、Renderの最安プラン$7(512MB)で動作すると試算していたが、実際に動作サせると2リクエスト程度でサーバーダウンした。)
デバッグ環境では、最安環境で動作できていたため、$7で行けると試算していたが、
実際にサービスリリースしてみたら、サーバーが落ちまくり、すぐに$25ドルプランに切り替えざる負えなくなった。。
更に、ユーザーが増えるごとに、$25ドルプラン(Standard)でも集中アクセス時、落ちる自体が発生し、その上のプランが$85ドル(Pro)であったため、アップグレードを断念し、
プログラムの処理の見直しや効率化に追われることとなる。。


3.サービスのスケール=収益増加ではない!
Webサービスの場合難しいのは、必ずしもWebサービス利用者の増加=周期の増加に繋がらないのである。上記画像は、私が利用したRender.comのサーバーレンタル料金。プランが上位になる事にコストが指数関数的に増加することがわかる。コストに合わせて、使用できるメモリー使用も酢数関数的には増加するのだが、
裏を返すと、Webサービスのユーザーの増加によって処理量が指数関数的に増える場合、サーバー料金も指数関数に増加するため、利益率は変わらない。そのため、今回のような比較的大きなデータを処理させるようなWebサービスの場合、ユーザー数が増加しても、単純に利益率は増加しないのだ。。。
5-2.Webアプリ開発における工数の見積もりミス
ウェブアプリを開発した経験がある方なら当たり前の話であるが、Webアプリでは、フロントエンドとバックエンドが別のサーバーで動作しているため、フロントエンドとバックエンドは通信を行い、やり取りをする必要がある。
つまりは、「color = 'Black'」の関数をフロントエンドがバックエンドから受信するにも、Post Getリクエストを使って、バックエンドサーバー側にリクエストを送り、バックエンド側からの応答を待つ必要がある。バックエンドからフロントエンドもしかり。
一見何が難しいのか?と思うかもしれないが、それぞれのサーバーは別に動作しているのである、フロント側が、データ参照リクエストを送った際バックエンド側は、翻訳タスクを複数抱えていて、リクエストを返せる状態ではないかもしれない。バックエンドが翻訳を完了して翻訳結果を返してもフロントエンド、ユーザー側はオフラインになっているかもしれないわけだ。。
これが、1言語、1サーバーで実行されているのであれば、エラー処理や参照処理は簡単であるが、
別言語、別サーバーで動いている場合、簡単ではなかった。
バックエンド側は並列に次ぐ並列処理で、タスクが溜まっている場合でも、適切にフロント側にレスポンスを返さなければいけない。フロントエンド側は、バックエンド側に負荷をかけないように、バックエンド側の状態を取得し、適切なタイミングでリクエストを送るように組まなければいけない。このやり取りすべてを、1から開発する必要があるのである。。
正直、フロントバックのやり取りの実装は予想以上に大変で、更に今回の実装ではセキュアな情報をやり取りする都合上フロントバックエンド側双方の処理が複雑となり、無事工数が爆増。
なんとか1ヶ月にて、αテストリリースにこぎつけたが、
収益化する場合は、より複雑なユーザー認証、ユーザーの課金システム実装、ユーザー情報の保存など、さらなる工数爆増が見込まれ・・・
もうヤ゙になっちゃった。。。
(巷のIT会社が、フロントとバックエンドで分業している理由がよくわかる。正直、複雑なWebアプリは個人開発すべきじゃあねぇ。。)
5-3.どうすればよかったのか?
ここについては、明確な回答はないが、
正直「デスクトップアプリ・スマホアプリ」での開発を検討すべきであったと思う。
今回、PDFの翻訳には、メモリー領域が必要との話をしたが、これはサーバーに翻訳リクエストを集約した結果、処理サーバーに大容量メモリー領域が必要になった。という話である。
1つのPDFを翻訳する際に必要なメモリー領域は多くても100MB程度ほどである。
今回のような、1つのサーバーですべての翻訳リクエストを捌くの構図ではなく、ユーザーのPCまたはスマートフォンのメモリー領域が利用できれば、この問題は発生しない。そのため、処理をユーザーのメモリー領域に展開するようなアプリケーション構成にするのが適切なアプリケーション設計であったと考えている。
(なお、PDFというフォーマットを扱う関係上、SwiftやC#にてアプリケーション開発を行うと、今度は、PDFライブラリの利用料を取られる羽目になるんだが。。PythonのPDFライブラリはオープンソース)
「どうすればよかったか?」の最も大切な考察がペラペラな気もするが、Noteに記事を書いても1円も入ってくるわけでもないので、許されると思っている。これを読んでいる奇特な方々には是非、事前に何をするべきで、どうすればよかったか?または、活路はどこにあったのかを考えて論じて貰えればと思っている。
6.オマケ・質問
6-1.Indqx OSS化
今回、開発したIndqx翻訳は、バックエンドサーバーのデータごと、OSSで配布しているので、Indqx翻訳を実際に体験してみたい、活路を見出したいという方は是非見てみてほしい。
GitHub Sponsor も行っているので、支援いただける方は少額でも支援痛ければありがたき幸せ。
6-2.質問[翻訳になぜLLMではなくDeepLを用いたの?]
XおよびYoutube配信にて、翻訳モデルとして、なぜLLMを用いずDeepLを用いたのか?という質問が来たので回答したい。
実は、Indqx初期開発時は、GPT4 Turboによる翻訳機が実装されていたが、以下の理由によりお蔵入りになっている。
1.値段
1番目の理由は、コストだ。
DeepLの翻訳コストは、基本料無視して1文字0.0025円
LLMの翻訳コストはGPT 4oで、Input $5.0/1M | Output $15.0/1M
となる。
試しに、走れメロスの一部を翻訳したと仮定しよう。

上記文の文字数は690文字。
DeepLなら、単純計算で1.725円となる。

GPT4o()の場合、Input 780Tokenとなる。
(公式からGPT4oのTokenizerが提供されていないのでGPT4で代用)
Outputも同一Tokenとして、1リクエスト翻訳で仮定して計算すると、
$0.0156 = 24.53円
となる。(GPT3.5 Turboであれば成立するが、GPT3.5は出力精度が安定しなかった)
単純計算で14.22倍である。
つまり、DeepLだと60円原価で翻訳できていた論文が、853円かかってしまう。これは現実的ではない。
ちなみにコスト気にせず、チートのGPT4を使うと、200円(2.5分)で11ページのPDFを良い感じに翻訳してくれるんだが、1翻訳200円(原価)は高い。。 pic.twitter.com/GmecRcaoXj
— 猩々 博士🧪💻 研究開発系V & AITuber開発休止中 (@Mega_Gorilla_) March 6, 2024
2.レスポンス速度
DeepLAPI利用に場合、トークン長制限が、GPTに比べると大きいので、PDFを平文化したデータをそのまま、投げることができるがDeepLはそうはいかない。トークン調ごとにリクエストを分離し、リクエストを送信取得する必要がある。
DeepLの場合、リクエストが返ってくるまでに、5秒程度(だったと思う)かかるが、
GPTの場合、複数リクエストを同時に投げても、概ね30秒前後レスポンス取得に時間がかかるため、サーバー側は、30秒間プロセスがスタックしてしまう。(もちろん並列処理させるのだが、)
更に、サーバースペックによる遅ーいPDF結合プロセスが入るため、ユーザーにレスポンスを返すまで1分近く掛かってしまう事となる。
3.レスポンスが安定しない
GPTは翻訳に特化したモデルではないため、レスポンスに余計な文字列が混ざることが多々、本当に多々ある。(GPT4-Turboはマシだが、GPT3.5が致命的で、別の言語で返してきたり、そもそも文章でなかったり。。。)
このレスポンスの担保が本当に地獄で、前後に余計な文字列が挿入されている場合は、再度翻訳させる等の処理層も実装したり、GPT3.5で評価させるなどいろいろ対策をしたが、出力は安定せず。。。
GPT3.5のレスポンス!怖い怖い! pic.twitter.com/EAb2hXxm3N
— 猩々 博士🧪💻 研究開発系V & AITuber開発休止中 (@Mega_Gorilla_) March 5, 2024
本日実装したGPT3.5による翻訳が、品質的に破綻していることがわかったので、作り直し。進捗が1日戻る。
— 猩々 博士🧪💻 研究開発系V & AITuber開発休止中 (@Mega_Gorilla_) March 5, 2024
LLMによる翻訳の品質を担保が泥沼化してる。。
— 猩々 博士🧪💻 研究開発系V & AITuber開発休止中 (@Mega_Gorilla_) March 6, 2024
上記理由により、わざわざGPTを翻訳に使うメリットが薄いと判断したため、GPT翻訳から、DeepL翻訳に切り替えた経緯がある。
どうしてもLLM使いたい!という人がいたら、翻訳特化モデルを使うことをオススメするよ。。。
以上。個人ニート開発者の3ヶ月(リリースまでの開発1ヶ月、αテスト期間2ヶ月)の奮闘をここに示します。
私と同じ虎徹を踏まないことを願って。
この記事が気に入ったらサポートをしてみませんか?