
機械学習やるならGoogle Colabが素晴らしかった話(Python実行環境)

Pythonの環境を作って勉強とか実装テストするとなると、今までなら「Jupyter Notebook」をローカルで立ててやっていたのだが、もうそんなことをせずともクラウド使ってどこでも実行環境を得られるようになった!スマホでもできちゃう!それが「google Colab」
Colaboratory とは
Colaboratory(略称: Colab)では、ブラウザから Python を記述し実行できるほか、次の特長を備えています。
・構成が不要
・GPU への無料アクセス
・簡単に共有
Colab は、学生、データ サイエンティスト、AI リサーチャーの皆さんの作業を効率化します。詳しくは、Colab のご紹介をご覧ください。下からすぐに使ってみることもできます。
Google Colaboratory の開始方法 (Coding TensorFlow)
Google Colab のはじめかた
Google Colab( https://colab.research.google.com/?hl=ja )にアクセスしてGoogleのアカウントでログインするだけですぐ使えます。
Colaboratory へようこそ
ログインしたらノートブック一覧が表示されてます。「Colaboratory へようこそ」というノートブックがあるので試しに開いてみよう。Googleドライブのデータを開くようなイメージです。

チュートリアルという感じのノートブックが表示されてます。説明はここに書いてある通りなので読んでみよう。
「Jupyter Notebook」を使ったことがある人ならほぼ同じと考えて良いです。(若干違うけど)、ブラウザ上に、実行環境とwikiみたいなものを同時に貼る付けられるイイ感じのものです。

テキストを編集してみる
編集方法は、たとえば、見出しにある「Colaboratory とは」をダブルクリックしてみよう。すると下図にある通り、HTMLの編集画面とプレビュー画面にその領域だけ切り替わりました。勘が鋭い方はもうこの時点で理解できてるでしょう。

コードを編集してみる
このチュートリアルの最初に出てくるコードに下記のようなものがある

ソースコードでいうと下記になるのだが、テキスト同様にコードも編集できます。
# 24 × 60 × 60 を計算して変数に格納しなさい
seconds_in_a_day = 24 * 60 * 60
# 変数seconds_in_a_day を表示(出力)しなさい
seconds_in_a_day
掛け算部分を、「seconds_in_a_day = 4 * 6 * 7」のように変えてみた。けど、その下の「86400」という数字が変わらない。そこで下図にあるように▼マーク(再生マーク)を実行してみよう。

すると▼マークの周りがくるくる回って計算してくれます。
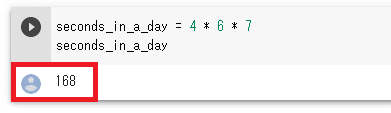
答えが出ましたね。4×6×7 = 168 らしい。実際そうですね。
このような感じで、1枚のノートブックに、テキスト(HTML)とコード(Python実行コード)を同時に入れることができます。ノートブックを多数作って、自分のGoogleドライブに格納しておくこともできます。
アヤメデータを機械学習のSVMモデルで分類
irisデータというものがあって、機械学習でよく使われるアヤメの品種のデータです。アヤメの品種のSetosa Versicolor Virginicaの3品種に関する150件のデータが入っています。そのデータセットがすでにscikit-learnライブラリに含まれているので使ってみます。
import matplotlib.pyplot as plt
from sklearn import cluster
from sklearn import datasets
# iris データセットをロード
iris = datasets.load_iris()
data = iris['data']
# k-means モデルの作成
# クラスタ数は 3 を指定
model = cluster.KMeans(n_clusters=3)
model.fit(data)
# クラスタリング結果ラベルの取得
labels = model.labels_
# 以降、結果の描画
# 1 番目のキャンバスを作成
plt.figure(1)
# ラベル 0 の描画色は緑色★
ldata = data[labels == 0]
plt.scatter(ldata[:, 2], ldata[:, 3], color='green')
# ラベル 1 の描画色は赤色★
ldata = data[labels == 1]
plt.scatter(ldata[:, 2], ldata[:, 3], color='red')
# ラベル 2 の描画色は青色★
ldata = data[labels == 2]
plt.scatter(ldata[:, 2], ldata[:, 3], color='blue')
# x軸、y軸の設定
plt.xlabel(iris['feature_names'][2])
plt.ylabel(iris['feature_names'][3])
plt.show()
# 結果は下図の通り、3色のラベル散布図として描画されました。これを、Google Colab のコード追加で張り付けて実行を押してみよう!

実行の結果は一番最後のコードにある「plt.show()」の結果が表示されるはずです。今回は結果は数字ではなく図表になります。
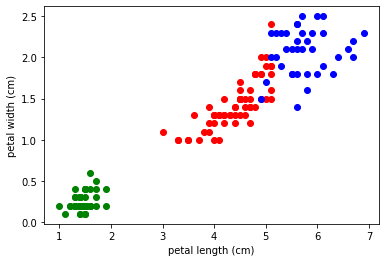
もう一回実行してみます。
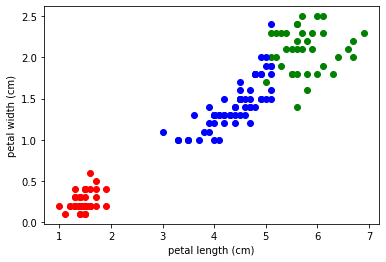
実行するたびに、座標の集合クラスターの色は指定してないのでいずれかの色に収束されているだけなので、実行のたびに色が変わる(再抽選されているということになりますね)
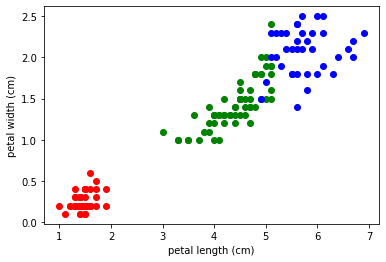
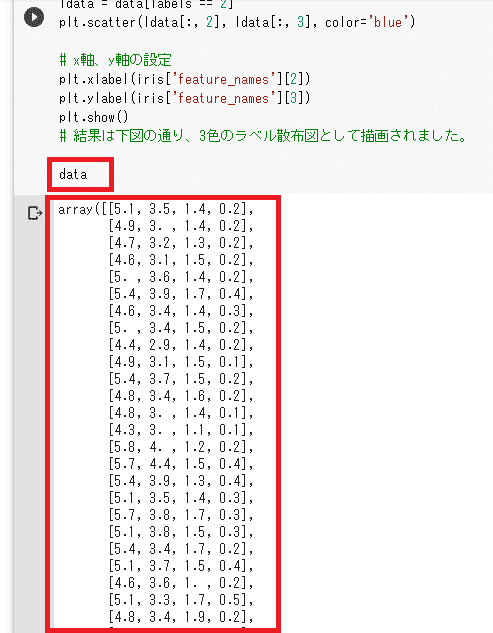
アヤメの元データを出してみたいときは、出力するものはコードの最後に、その変数を書くと実行結果に表示させられます。
iris = datasets.load_iris()
data = iris['data']つまり、deta にアヤメの生データが入ってるので出力してみると下記の通り配列で出てきます。
Googleドライブにノートブックを保存

・・・
Webのお仕事、元phpプログラマ、今主にWebディレクタ、たまにエンジニア、UXディレクタ、LTのネタ探ししてます。