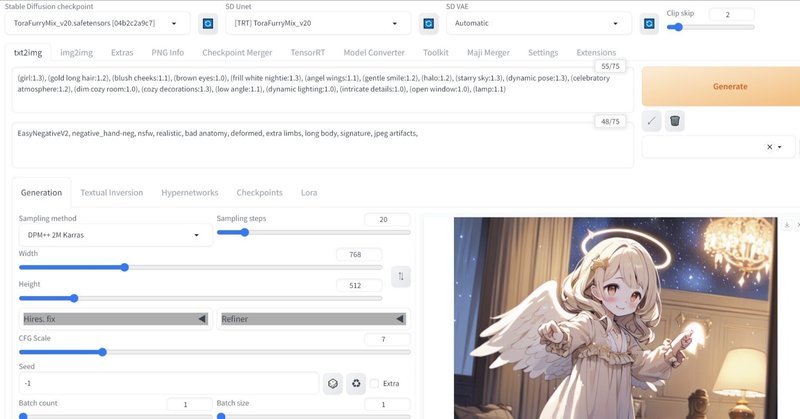
AUTOMATIC1111版Stable Diffusion web UIでNVIDIAのTensorRT拡張を利用する手順

Last update 10-25-2023
※まずは「0. 結論」をご確認ください。
※拡張を入れても使えない場合は、本体に様々な変更を行います。筆者は一切フォローできませんので、くれぐれも自己責任でお願いします(心配な方は新規環境で…)。なお、TensorRTは比較的多くのVRAMを消費します。
高速に生成ができる、別の手法についての記事もご覧ください。
▼ 0. 結論
下記の内容だけで話が理解できる方は、本記事の長々とした内容を読む必要はありません。どうぞお試しください。
GeForceの最新ドライバー(545.84以上)をインストールする。
TensorRT拡張をインストールする。
使えない → UI本体(拡張も)とtorch(とxformers)の更新、medvramやlowvramの削除を行う。
まだ使えない → venvを削除する。
エラーが出る → venv\Lib\site-packages\nvidia\cudnnをリネームする。
▼ 1. 本記事について
1-1 概要
Stable Diffusion形式のモデルで画像を生成する有名なツールに、AUTOMATIC1111氏のStable Diffusion web UI(以下、AUTOMATIC1111 web UI)があります。最近、NVIDIAがこれに対応したTensorRTのエクステンションを公開しました。
TensorRTを利用すると画像の生成が高速化するのですが、最初、筆者の既存の環境ではうまく動きませんでした。その後なんとか解決できたので、方法を含めて本記事で紹介します。
順を追って説明しているので、項目順に確認してみてください。
1-2 注意
トラブル解決の際に、AUTOMATIC1111 web UIのアップデートや構成ファイルの変更を伴うため、自己責任で実施してください。
1-3 動作環境(推定)
Geforce 2000番台以降とします。VRAMは8GB以上でなるべく多い方が良いでしょう(medvramやlowvramが使えません)。ローカルに別途TensorRT等をインストールする必要があるかどうかは、今後確認します(筆者の環境はインストールされています)。
1-4 公式リポジトリ
TensorRT Extension for Stable Diffusion
https://github.com/NVIDIA/Stable-Diffusion-WebUI-TensorRT
1-5 以前の情報
過去に、同様のエクステンション「TensorRT support for webui」について紹介したことがあります。こちらはメンテナンスされていないようなので、インストール済みであれば削除した方が良いかもしれません。
1-6 関連情報
本記事は小難しく書いていて読むのが大変なので、他の方の記事を先に読んでみるのもいいかもしれません。
▼ 2. TensorRT Extensionの導入
インストール済みの方は読み飛ばしてください。
2-1 エクステンションのインストール
先にTensorRT Extensionをインストールしても差し支えないようですので、インストールを行います。
AUTOMATIC1111 web UIを起動したら、タブを「Extensions」「Install from URL」の順に移動し、公式リポジトリのURLを入力して「Install」ボタンをクリックしてください。
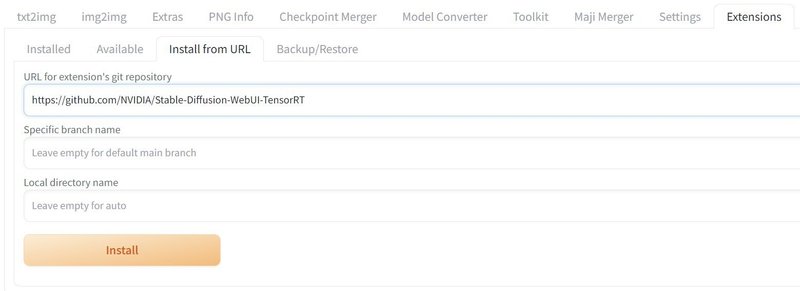
インストールが完了すると、「Install」ボタンの下に表示が出ます。その後、「Installed」のタブに移動して「Apply and restart UI」をクリックして再起動を待ちます。
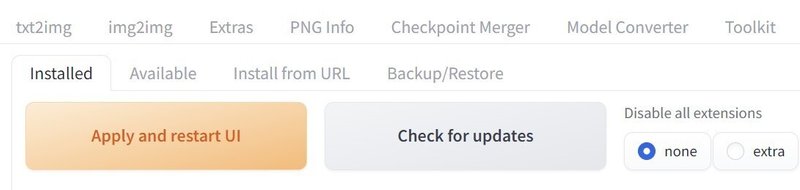
これで「TensorRT」のタブが表示された方はおめでとうございます。以降の手順は必要ないかもしれません。現実を信じたくない方は、AUTOMATIC1111 web UIをいったん終了して起動し直してください。
それでは次項より、解決方法をひとつずつ紹介します。
▼ 3. 本体と起動オプションの確認
3-1 情報
PyTorch等のパッケージを含めて最新版になっていること、medvramやlowvramを有効にしていないこと、本体のバージョンが古くないことが、正常に利用できる条件となっていると思われます。予め、問題が起こりそうな箇所を解消しておいてください。
3-2 注意点(必読)
場合によっては、中身が大きく変更される手順です。これにより起動できなくなったり、一部のエクステンションが利用できなくなる場合があります。心配な方は別のディレクトリに新規インストールして、そちらで初めから行ってください。
3-3 VRAM節約のオプションを無効化する
もし起動オプションに「--medvram」や「--lowvram」があれば、削除してください。原因不明ながら、モデルの変換自体ができない現象を確認しています。この手順は3-5の時に行うと良いでしょう。
3-4 本体の更新
Gitを使ってインストールした場合は、インストール先に移動して「git pull」のコマンドを実行するだけです。下記は一例です。なお、Gitを使用しない更新方法は失念しました(すみません)。
cd \aiwork\stable-diffusion-webui
git pull3-5 PyTorchとxFormersの更新(1回のみ)
起動に使用しているバッチファイルを編集してください。多くの方は「webui-user.bat」か、そのコピーではないかと思います。編集画面を開いたら、「set COMMANDLINE_ARGS=」の箇所に注目してください。下記は手順を説明するための例です。
set COMMANDLINE_ARGS=--autolaunch --xformers イコールの直後に「--reinstall-torch --reinstall-xformers」を追加してください(後ろでも構いませんが前の方が視認性が良いです)。元々あったオプションとの間の半角スペースも忘れないでください。
set COMMANDLINE_ARGS=--reinstall-torch --reinstall-xformers --autolaunch --xformers 長いことアップデートしていない方は「--update-all-extensions」も加えた方が良いかもしれません。エクステンションが古いと、起動できなくなる場合があります。
編集が終わったら起動してください。場合によっては、しばらく待たされる可能性があります。正常起動を確認したら終了して、追加した部分を削除してください。残しておくと起動に時間がかかるようになります。
3-6 参考
筆者は、起動オプションを「set COMMANDLINE_ARGS=--opt-sdp-no-mem-attention --no-half-vae」にしています。「--medvram」のみを削除して、この状態で動作を確認しています。
(opt-sdp-no-mem-attentionは同一設定時の再現性が非常に高く、no-half-vaeは黒画面対策)
▼ 4. TensorRTのタブが無い場合
表示されている方は読み飛ばしてください。
4-1 状況
筆者の環境では「TensorRT」のタブが出現しませんでした。この際、起動途中に「AttributeError: module 'tensorrt' has no attribute 'IProgressMonitor'」のエラーが出ていることを確認しました。この状態でも、TensorRTが利用できないこと以外の支障はありません。ご安心ください。
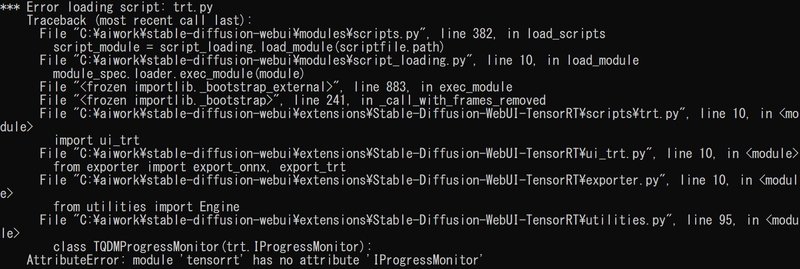
結論から話すと、必要なパッケージがインストールされていないため、環境を再構築するのが早いようです(もしかすると、TensorRT関連のパッケージを入れるだけでも済むかもしれません)。
下記画像は、TensorRTのタブが表示されなかった環境と、再構築して利用できるようになった環境の相違(pip freezeの出力)の一部です。git pull で更新はしていたもののパッケージは特に手を入れず、現状と大幅に異なっていることがわかりました。

4-2 仮想環境を再構築する
まずはAUTOMATIC1111 web UIを終了してください。次に、インストールフォルダを開いて「venv」ディレクトリをリネームしてください。トラブルがあった場合は、ディレクトリの名前を戻せば回復します。新しい環境がうまく動作した後で削除するかどうかはお任せします。

では、改めてAUTOMATIC1111 web UIを起動してください。パッケージを全てインストールし直すため、すこし時間がかかります。その後の起動中に別のエラーが出たため、次項にて説明します。
▼ 5. 起動中にエラーが出る場合
5-1 状況
AUTOMATIC1111 web UIの起動中に、エラーのダイアログが出現しました。とりあえず「OK」を何度かクリックすると起動はできます。

5-2 注意点(必読)
誤操作から発見した、正統とは言いづらい方法です。ただし、この操作によってcuDNNの参照先が変わり、正しく動作しているように見えます。他の方法が見つかった場合は本記事に記載します。
CUDNN_PATHの設定は不要のようです。ただし、PC自体にcuDNNをインストールする必要があるかどうかは未確認です。(※cuDNNはPythonの環境上に入っているため必要ありません)
5-3 仮想環境のcudnnディレクトリを無効化する
まずはAUTOMATIC1111 web UIを終了してください。次に、インストールフォルダを開いて「venv\Lib\site-packages\nvidia」まで移動してください。ここに「cudnn」ディレクトリがあるので、リネームしてください。

この変更によりエラーのダイアログは出なくなりましたが、今後トラブルが発生する可能性も考えられます。その場合はディレクトリの名前を戻してください。つまり、変更したことを覚えておく必要があります。
▼ 6. TensorRTの利用方法
現在、Stable Diffusion 1.5または2.1のモデルで利用できます。SDXLについてはdevブランチで対応しているとの情報があります。利用可能なサイズの幅や値を大きくしすぎると、VRAM不足で変換できなくなりますので注意してください。
6-1 表示項目の追加
AUTOMATIC1111 web UIを起動後、「Settings」タブに移動してください。左側から「User interface」を探してクリックして、「Quicksettings list」に「sd_unet」を追加します。
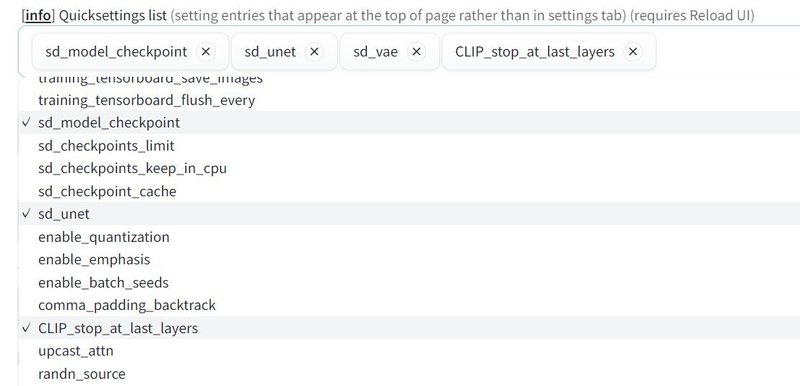
追加が終わったら「Apply settings」「Reload UI」を続けて行ってください。画面上部に「SD Unet」が出現します。
6-2 モデルの変換
まずは「TensorRT」タブに移動して、使用したいモデルを選択しておいてください。順番は前後しても構いません。
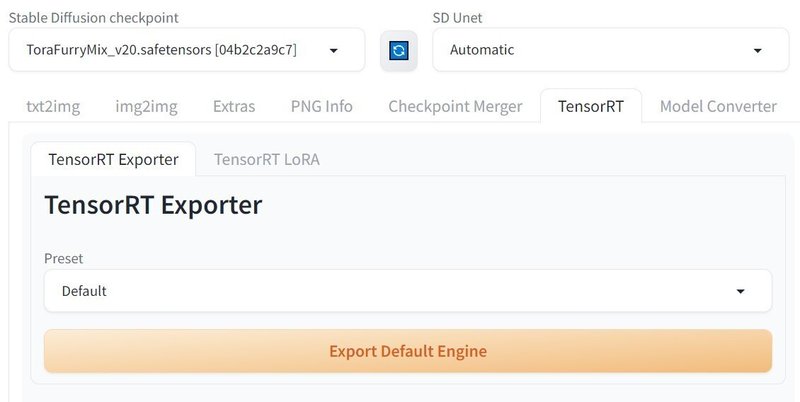
「Preset」は「Default」のままか、VRAMが少ない場合は一番上の「512x512 | Batch Size 1 (Static)」を選択してみてください。「Default」の設定内容は「512x512 - 768x768 | Batch Size 1-4 (Dynamic)」と同じとみられます。SDXLモデルの場合は「768x768 - 1024x1024 | Batch Size 1-4 (Dynamic)」になるようです(未確認)。
次に「Export Default Engine」をクリックすると変換が始まります。下記の表示は気にしなくても構いません。

特に初回は「Output」欄の表示を確認してください。下記のような表示で秒数が進んでいれば変換中です。しばらくお待ちください。表示が無ければ、何らかのエラーで変換を中断しています。コマンド プロンプトの表示も確認すると確実です。

上記のカウント表示が消えると変換は終了です。「Available TensorRT Engine Profiles」の隣のリフレッシュボタンを押すと、変換済みモデルの一覧が表示され、展開すると設定が確認できます。同じモデルでも異なる設定で変換すると新しいプロファイルとなり、いずれも保持されます。
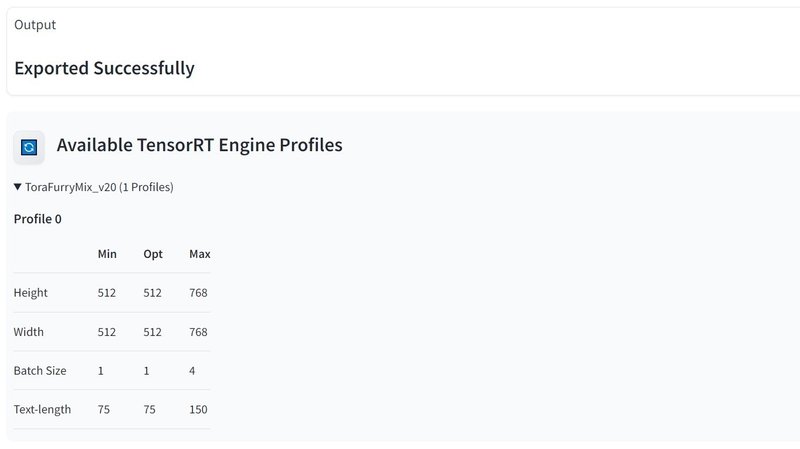
変換後のモデルは「stable-diffusion-webui\models\」の中の「Unet-onnx」と「Unet-trt」のディレクトリに入っています。
6-3 TensorRTのモデルで画像を生成する
タブを「txt2img」に戻してください。また、変換実行後は必ず、上部の「SD Unet」の右側にあるリフレッシュボタンを押してください。これを行うことで、変換済みモデルが認識されます。

通常はモデルを選ばずに「Automatic」のままで構いません。また、TensorRTを使用したくないときは「None」を選択してください。
もし手動でTRT(TensorRT)モデルを選択する場合、「Stable Diffusion checkpoint」は変換前のモデルを選択する必要があります。「Automatic」にしておけば、考慮する必要はありません。
その後は、いつもと同じように生成を行ってください。注意点が二つあり、「縦横のサイズはMinとMaxの間の64の倍数で、トークン数も範囲内」であることと、「Hires. fixやその他の拡張機能は制約または利用不可の場合がある」ことです。また、それ以外でも生成ができなかったり、VRAMを過剰に消費したりする現象が発生する可能性があります。

本当にTensorRTを使用したのかどうかは分かりづらいので、ログの表示で確認してください。下記のような、特徴的な箇所が見つかるはずです。

▼ 7. よく使う設定でモデルを用意する
7-1 モデル変換時の設定を変更する
自分でモデルの設定を調整することもできます。「Default」以外のPresetを選択して、「Advanced Settings」を展開してください。

設定の仕方は二通りあり、「Use static shapes.」にチェックを入れた場合は上記のようにシンプルになり、解像度等の制約が厳密になります。チェックを外した場合は、「Min-Optimal-Max」の値を設定する必要があります。設定が終わったら変換を実行してください。
参考まで、解像度などの幅はなるべく狭くしてください。可能なら、決め打ちにした方が消費リソースが少なくて済むようです。あまり幅を持たせてしまうと、VRAM不足で変換できなくなります。
変換時の設定毎にプロファイルとモデルが作成されるので、使いたい解像度別で用意しておくと良いかもしれません。
▼ 8. モデルの削除
8-1 削除方法
不要なモデルがあるときは、削除して容量を節約することができます。変換後のモデルは「stable-diffusion-webui\models\」の中の「Unet-onnx」と「Unet-trt」のディレクトリに入っています。
TensorRTに関するモデルの全てが不要であれば、「Unet-onnx」と「Unet-trt」のディレクトリを削除するだけなので簡単です。
Unet-onnxディレクトリに入っている「*.onnx」のファイルは、TensorRTモデルへ変換する前に作成されたモデルです。こちらは単純に削除できると思います。
Unet-trtディレクトリに入っている「*.trt」のファイルはTensorRTモデルです。同じディレクトリの「model.json」にも情報が記載されているため、単純に削除すると不具合が発生するかもしれません。中身はモデル名の下にプロファイルが含まれている形なので、構造が理解できる方は編集できると思います。
▼ 9. その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?