AUTOMATIC1111版Stable Diffusion web UIでLCM LoRAを利用する手順

Last update 11-26-2023
▼ 0. LCM LoRAを利用する簡単な方法
記事の本編よりも先に、LCM LoRAを体験する最も簡単な方法を紹介します。標準の利用方法については1.以降をご覧ください。
0-1. LCM LoRAをマージしたモデル
LCM LoRAをマージしたStable Diffusionモデルが登場していて、これらを利用すればすぐに生成ができます。Sampling stepsとGFC Scaleをかなり下げる必要がありますので注意してください(steps=8程度、GFC=1~2)。また、LCM LoRAを指定するプロンプトを記入してはいけません。
なお、LCM Samplerは必須ではなく、Euler a、DPM++ 2S a Karras等を利用するのが良さそうです。LCM Samplerを利用したい場合は3.をご覧ください。
LCMモデルは、Civitaiのモデル一覧にて絞り込めば見つけられます。Model typesの選択を「Checkpoint」に、Base modelの選択を「SD 1.5 LCM」や「SDXL 1.0 LCM」に変更してください。今はまだ少ないですが、今後増えていくと思われます。
0-2. LCM LoRAのマージモデルと生成画像
執筆時点で存在するモデルでの例です。
EveryjourneyLCM (SD 1.5 LCM)
https://civitai.com/models/210006

Negative prompt: (worst quality, low quality:1.2),
Steps: 8, Sampler: LCM, CFG scale: 2, Seed: 3723027663, Size: 768x384, Model hash: 1341c166e5, Model: everyjourneylcm_v10Ace, Denoising strength: 0.55, Clip skip: 2, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+ Anime6B, Version: v1.6.0-2-g4afaaf8a
blue_pencil-XL-LCM (SDXL 1.0 LCM)
https://civitai.com/models/202108

Negative prompt: (worst quality, low quality:1.2),
Steps: 7, Sampler: DPM++ 2S a Karras, CFG scale: 1.5, Seed: 1901377996, Size: 1024x512, Model hash: 9d592e9646, Model: blue_pencil-XL-v1.0.0-lcm, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires upscaler: R-ESRGAN 4x+ Anime6B, Version: v1.6.0-2-g4afaaf8a
Reproduction_LCM (SDXL 1.0 LCM)
https://civitai.com/models/202308

Negative prompt: (worst quality, low quality:1.2),
Steps: 7, Sampler: Euler a, CFG scale: 2, Seed: 2209450610, Size: 1024x512, Model hash: 5e88584811, Model: reproductionLCM_v10, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires upscaler: R-ESRGAN 4x+ Anime6B, Version: v1.6.0-2-g4afaaf8a
▼ 1. 本記事について
1-1. 概要
Stable Diffusion形式のモデルで画像を生成する有名なツールに、AUTOMATIC1111氏のStable Diffusion web UI(以下、AUTOMATIC1111 web UI)があります。これを使い、高速に画像の生成ができるTensorRT拡張について記事を書きました。
本記事では、これとは異なる「LCM LoRA」という手法を用いる手順を説明します。生成時のStepsを大幅に下げられるため、Hires. fix(i2iのアップスケーリング)も高速化するのが特徴です。
LCMやLCM LoRAについては、下記の記事をご覧ください。なお、TensorRTと併用もできるようです。
▼ 2. LCM LoRAの注意点
2-1. 利用時の注意
LCM LoRAにて生成が高速になる代わりに、いくつかの代償を払う必要があるかもしれません。
生成画像が異なる。Sampling stepsとGFC Scaleをかなり低く設定するので、挙動の変化は避けられない。そのため、LCM LoRAの利用を前提としてプロンプトや設定を調整する必要がある。
モデルによる相性があり、望ましい結果が得られない場合がある。LCM LoRAが、ベースモデル向けであることが理由と考えられる。相性が良いモデルを探すか、LCM LoRAを組み込んだモデルを利用する。
Sampling methodの相性も激しい。LCM Samplerを使用するのは無難だが、描き込みが減ってしまう。Euler a、DPM++ 2S a Karrasは比較的向いている。
▼ 3. LCM LoRAを利用する手順
3-1. 概要
手順は2つあり、LCM Samplerを追加すること(ただし必須ではない)と、生成時にLCM LoRAを指定することです。本記事では下記の条件を前提とします。
既にAUTOMATIC1111 web UIを利用中、または新規インストールが済んで利用できる状態であること。正しく動作していない可能性があれば、アップデートを検討する。
操作画面の下部に「torch: 2.0.1+cu***」と表示されていること。これとは異なる場合の動作は未確認で、AUTOMATIC1111 web UI本体やPyTorchのアップデートを要する可能性がある。
(※LCM Sampler以外はLoRAの適用だけなので、古いバージョンでも利用できる可能性はあるが未確認。)
3-2. Sampling methodにLCMを追加
こちらは必須とまでは言えない模様です。興味のある方は追加してみてください。確認したところ、2つの方法がありました。本記事では前者の方法を選択します。なお、どちらもほとんど同じ手順でインストールできます。
AnimateDiff for Stable Diffusion WebUIを導入する(LCM Samplerも導入される)。
https://github.com/continue-revolution/sd-webui-animatediff単体のLCM Samplerを導入する(執筆時点で、名前が「LCM Test」になっている模様)。
https://github.com/light-and-ray/sd-webui-lcm-sampler
AUTOMATIC1111 web UIを起動したら、タブを「Extensions」「Install from URL」の順に移動し、AnimateDiffの公式リポジトリのURLを入力して「Install」をクリックしてください。導入済みでLCM Samplerが選べない方は、AnimateDiffをアップデートしてください。
インストールが完了すると、「Install」ボタンの下に表示が出ます。その後、「Installed」のタブに移動して「Apply and restart UI」をクリックして再起動を待ちます。もし、LCM Samplerがなければ、AUTOMATIC1111 web UI自体を起動し直してみてください。
3-3. LCM LoRAを追加
LCM LoRAは名前の通りLoRAですので、他のLoRAと同じように利用できます。下記のURLよりダウンロードして、LoRA用のディレクトリに移動してください。
Stabe Diffusion 1.5用
https://huggingface.co/latent-consistency/lcm-lora-sdv1-5Segmind Stable Diffusion 1B (SSD-1B)用
https://huggingface.co/latent-consistency/lcm-lora-ssd-1bStable Diffusion XL用
https://huggingface.co/latent-consistency/lcm-lora-sdxl
いずれもファイル名が同一(pytorch_lora_weights.safetensors)ですので、共存させたい場合は注意が必要です。最も簡単な解決方法は、ファイル名を変えることです。
ところで、モデルとLoRA等を併用する場合は、Stable Diffusionのメジャーバージョン(1、2、XL)が一致している必要があります。筆者はこれらの混在が進んで混乱してしまったので、バージョンごとに設置ディレクトリを分けることにしました。やり方は別の記事で紹介する予定です下記の記事で紹介しました。
Stable Diffusion web UI (Forge) の個人的な設定メモ
https://note.com/mayu_hiraizumi/n/nd05a329ff982
3-4. 生成を行う
準備ができたら生成を行います。設定で注意する点がいくつかあります。モデルのサンプル画像があれば、そちらも参照してください。
プロンプトでLCM LoRAを指定する(LCM LoRAをマージしたモデルの場合は不要)。末尾に「,<lora:pytorch_lora_weights:1>」の形式でLoRAのファイル名を記述すること。数値の1は調整が可能で、減らした値も試してみると良いかもしれない。
Sampling methodは、Euler a、DPM++ 2S a Karras、LCMのいずれかを選択する。LCMはシンプルなイメージになる傾向があるので好みで。確認したところ、DPM++ 2M SDE Exponential、DPM++ 2M SDE Heun Exponential、DPM++ 3M SDE Exponential、Restartも可とみられる。
Sampling stepsは、4~10程度。4では画像がぼんやりする場合がある。問題がなければ8で固定しても構わない。
CFG Scaleは、1~2程度。問題がなければ2で固定しても構わない。なお、スライダーは0.5単位だが実は細かい指定が可能(小技)。
Hires. fixは好みで使用する。モデルによっては苦手な出力解像度が存在するため、筆者は基本的にHires. fixを使用している。0-2.や4.に設定例がある。
その他の拡張機能は未確認。何かが悪さをする可能性があるので、シンプルな状態から始めるか、それぞれの影響を確認するのが望ましい。
▼ 4. LCM LoRAサンプル画像
4-1. 概要
生成したサンプル画像を設定込みで掲載します。起動オプションは下記のとおりです。opt-sdp-no-mem-attentionを指定してxformersを外すと、同一設定時の再現性が高くなります(常に同じ画像が生成される)。
COMMANDLINE_ARGS=--opt-sdp-no-mem-attention --no-half-vae --medvram4-2. 生成時の設定
下記のURLで配布しているLittleStepMix_AとVAEを使用しました。
https://huggingface.co/sazyou-roukaku/LittleStepMix
下記の設定はHires. fix有りの場合です。
pale pastel color anime,1girl, softly smile :d, upper body, yellow green pigtail hair, skyblue seaside beach, some palm-tree, gray eyes, pale pink ribbon dress, distant mountain, <lora:pytorch_lora_weights:1>
Negative prompt: (worst quality, low quality:1.2), backlit,
CFG scale: 2, Seed: 4184699122, Size: 768x384, Model hash: 1493009b1f, Model: LittleStepMIx_A, VAE hash: f6dbafc61e, VAE: sr_SDv2vae_kl-f8anime2.safetensors, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 2, Hires upscaler: R-ESRGAN 4x+ Anime6B, Lora hashes: "pytorch_lora_weights: aaebf6360f7d", Version: v1.6.0-2-g4afaaf8a
4-3. Hires. fix無し
出力解像度は768x384です。Stepsが低すぎると、不十分な出力になってしまうようです。Samplerごとの特徴も見られます。

4-4. Sampler: Euler a 固定
これ以降はすべて、出力解像度は1536x768(Upscale by 2)、Hires stepsは0です。Sampling stepsやHires samplerによる違いが見られます。

4-5. Sampler: DPM++ 2S a Karras 固定
ほど良い描き込みが得られそうな雰囲気です。Euler aかこちらか、好みで選ぶと良いでしょう。

4-6. Sampler: LCM 固定
Euler aよりもすっきりしています。こちらも好みで選ぶと良いでしょう。

4-7. 結論
念のためSamplerとHires samplerを変えて試してみましたが、わざわざ変える必要は無いと思います(モデルにもよるかも?)。全体的な設定をどうするかは好みによるところが大きいので、色々試してみてください。
もし良ければ、DPM++ 2M SDE Exponential、DPM++ 2M SDE Heun Exponential、DPM++ 3M SDE Exponential、Restartも試してみてください。X/Y plotを使って、Samplerごとの出力を確認してみるのも良いと思います。
▼ 5. おまけ
表紙画像のプロンプト等を記載します。同一の画像を生成するためには、「torch: 2.0.1+cu118」「--opt-sdp-no-mem-attention」の設定が必要です。
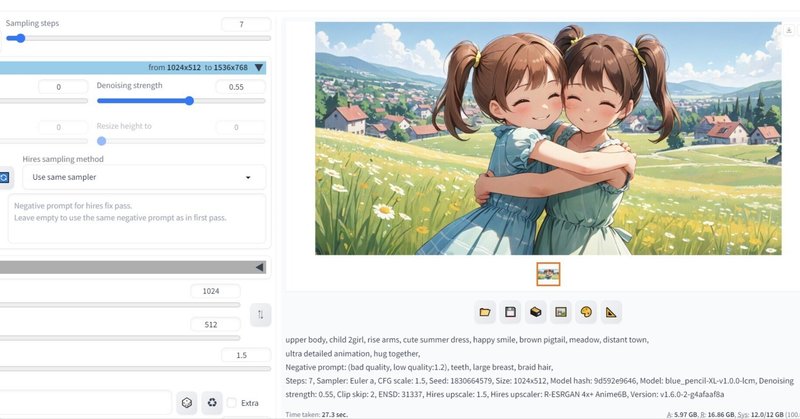
upper body, child 2girl, rise arms, cute summer dress, happy smile, brown pigtail, meadow, distant town,
ultra detailed animation, hug together,
Negative prompt: (bad quality, low quality:1.2), teeth, large breast, braid hair,
Steps: 7, Sampler: Euler a, CFG scale: 1.5, Seed: 1830664579, Size: 1024x512, Model hash: 9d592e9646, Model: blue_pencil-XL-v1.0.0-lcm, Denoising strength: 0.55, Clip skip: 2, ENSD: 31337, Hires upscale: 1.5, Hires upscaler: R-ESRGAN 4x+ Anime6B, Version: v1.6.0-2-g4afaaf8a

▼ 6. その他
私が書いた他の記事は、メニューよりたどってください。
noteのアカウントはメインの@Mayu_Hiraizumiに紐付けていますが、記事に関することはサブアカウントの@riddi0908までお願いします。
この記事が気に入ったらサポートをしてみませんか?