
テニスデータで決定木分析withコード

こんにちは。Zonoです。
先日、あるメディアにテニスのデータ分析を取り上げていただきました。
といっても、ただ記事を書いただけなのですが。
こちらの記事では、コードを載せていなかったので大変見苦しく、汚いですが記載していこうと思います。また、一部誤った認識をしていたのでその部分は除去しています。
前処理
まずデータです。

こちらが0,1,2,3.....と連続した数になっているので率(rate)に計算し直します。その後にもう必要ではない列を削除します。
df['first_serve_points_won_rate'] = df['first_serve_points_won'] / df['first_serve_points_total']
df['first_serves_in_rate'] = df['first_serves_in'] / df['first_serves_total']
df['second_serve_points_won_rate'] = df['second_serve_points_won'] / df['second_serve_points_total']
df['break_points_saved_rate'] = df['break_points_saved'] / df['break_points_serve_total']
df['first_serve_return_won_rate'] = df['first_serve_return_won'] / df['first_serve_return_total']
df['second_serve_return_won_rate'] = df['second_serve_return_won'] / df['second_serve_return_total']
df['break_points_converted_rate'] = df['break_points_converted'] / df['break_points_return_total']
df['service_points_won_rate'] = df['service_points_won'] / df['service_points_total']
df['return_points_won_rate'] = df['return_points_won'] / df['return_points_total']
df['total_points_won_rate'] = df['total_points_won'] / df['total_points_total']
df['aces_per_game'] = df['aces'] / df['service_games_played']
df = df.drop('first_serve_points_won', axis=1)
df = df.drop('first_serve_points_total', axis=1)
df = df.drop('first_serves_in', axis=1)
df = df.drop('first_serves_total', axis=1)
df = df.drop('second_serve_points_won', axis=1)
df = df.drop('break_points_saved', axis=1)
df = df.drop('second_serve_points_total', axis=1)
df = df.drop('break_points_serve_total', axis=1)
df = df.drop('break_points_converted', axis=1)
df = df.drop('first_serve_return_won', axis=1)
df = df.drop('first_serve_return_total', axis=1)
df = df.drop('second_serve_return_won', axis=1)
df = df.drop('second_serve_return_total', axis=1)
df = df.drop('break_points_return_total', axis=1)
df = df.drop('service_points_won', axis=1)
df = df.drop('service_points_total', axis=1)
df = df.drop('return_points_won', axis=1)
df = df.drop('total_points_won', axis=1)
df = df.drop('total_points_total', axis=1)
df = df.drop('return_points_total', axis=1)
df = df.drop('match_duration', axis=1)
df = df.drop('sets_won', axis=1)
df = df.drop('games_won', axis=1)
df = df.drop('id', axis=1)
df = df.drop('aces', axis=1)そうすると欠損値が含まれている行を全て削除します。
df = df.dropna()
そして全体のデータを眺めてみます。
df.hist()
よく見てみると外れ値があるのでそのデータを落としていきます。
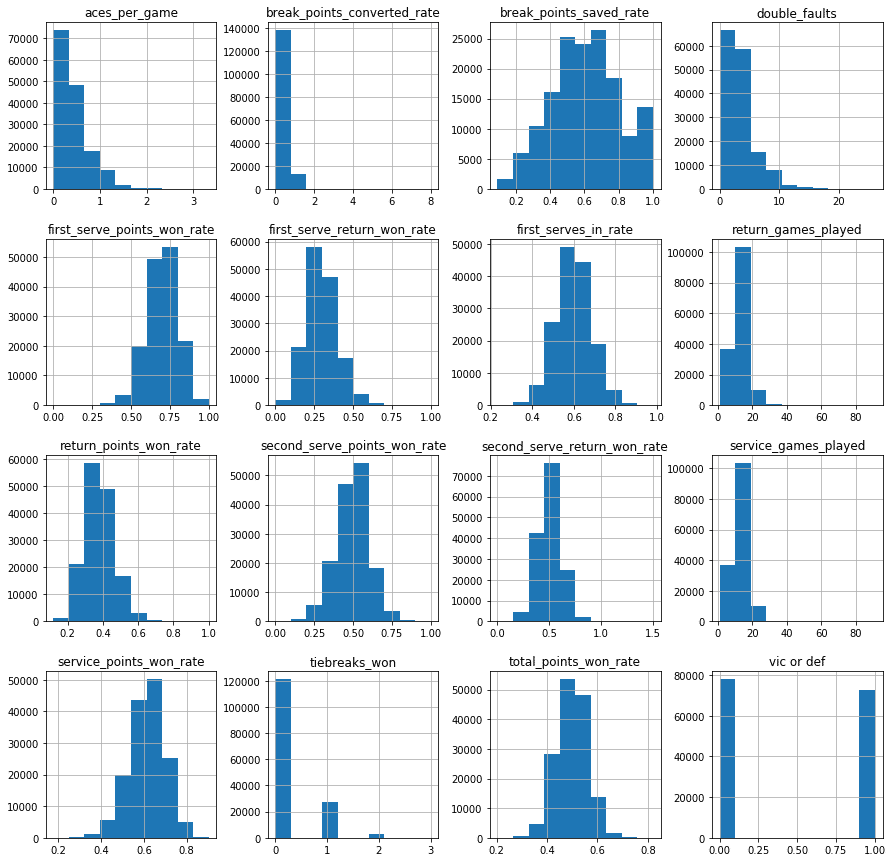
次の2つの列を
first_serves_in_rate
break_points_saved_rate
綺麗に外れ値を除去します。
df = df[df['first_serves_in_rate'] > 0]
df = df[df['break_points_saved_rate'] > 0]
これで今回の前処理は完了です。
機械学習のための準備
次に機械学習の準備をします。
まずはライブラリを呼びます。
#ライブラリをインポート
from sklearn import tree
from sklearn.model_selection import train_test_split
#説明変数と目的変数に分ける
train_x = df.drop('vic or def', axis=1)
train_y = df['vic or def']
#学習データとテストデータを7:3に分割
(train_X, test_X ,train_y, test_y) = train_test_split(train_x, train_y, test_size = 0.3)今回は、勝敗に対しての変数を見たいので[vic or def]を目的変数にしてtrain_xとtrain_yに格納します。
その後に機械学習の定番である学習データとテストデータを7:3に分割します。
決定木分析
ここから決定木分析です。
※記事と内容が違います。主成分分析をしていません。
決定木分析はノンパラメトリック手法で母集団の分布の前提も必要ないですし、大小関係を見ているので標準化・正規化が必要ありません。
大変便利です。
ライブラリをインポートから始めます。
from sklearn.tree import DecisionTreeClassifier
from sklearn.metrics import (roc_curve, auc, accuracy_score)
clf = DecisionTreeClassifier(criterion='entropy', random_state=0)
clf = clf.fit(train_X, train_y)
pred = clf.predict(train_X)
pred = clf.predict(test_X)
fpr, tpr, thresholds = roc_curve(test_y, pred, pos_label=1)
auc(fpr, tpr)
accuracy_score(pred, test_y)このコードを実行すると
0.9256196519778008
と表示されます。これはモデルがテストデータに対して説明できる割合です。1が最大値です。割と説明できてそうです。
そして可視化です。どの変数が重要なのか見ていきます。
#可視化
import pydotplus
from IPython.display import Image
from graphviz import Digraph
from sklearn.externals.six import StringIO
dot_data = StringIO()
tree.export_graphviz(clf, out_file=dot_data,feature_names=train_X.columns, max_depth=2, filled=True,rounded=True)
graph = pydotplus.graph_from_dot_data(dot_data.getvalue())
graph.write_pdf("graph.pdf")
Image(graph.create_png())
このように画像がアウトプットされます。
課題は変数選択です。
最後に
データがどこに落ちているのか等、ソースを知りたいという方はぜひこちらの記事を読んでみてください。
この記事が気に入ったらサポートをしてみませんか?