
Photo by
shinobuwada
テニスデータでロジスティック回帰

今回はロジスティック回帰で分析をしてみます。
今回もテニスのデータです。
過去に決定木でも分析しています。
ロジスティック回帰は、決定木と違って正規性仮定や標準化・正規化が前提条件となっているのでそのままデータを突っ込むということができないので注意です。
データ準備
まずはライブラリをインポートします。
#必要なライブラリのインポート
import pandas as pd
import numpy as np
from io import StringIO
from sklearn.preprocessing import Imputer, LabelEncoder, OneHotEncoder, MinMaxScaler, StandardScaler
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
import math
import matplotlib.pyplot as plt
import statsmodels.api as sm
from sklearn.feature_selection import RFE
from sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn import metrics
from sklearn.metrics import confusion_matrix
from sklearn.metrics import roc_auc_score
from sklearn.metrics import roc_curve
from sklearn.metrics import classification_report
from matplotlib.font_manager import FontProperties
from sklearn import datasets今回の前処理は決定木分析と全く同じとします。
ここも前回と同様に学習データとテストデータに分割していきます。
from sklearn import tree
from sklearn.model_selection import train_test_split
train_x = df.drop('vic or def', axis=1)
train_y = df['vic or def']
(train_X, test_X ,train_Y, test_Y) = train_test_split(train_x, train_y, test_size = 0.3)今回は変数同士の相関性(多重共線性)も調べてみます。
plt.figure(figsize=(10, 10)) #heatmap size
sns.heatmap(train_X.corr(), annot=True, cmap='plasma', linewidths=.5)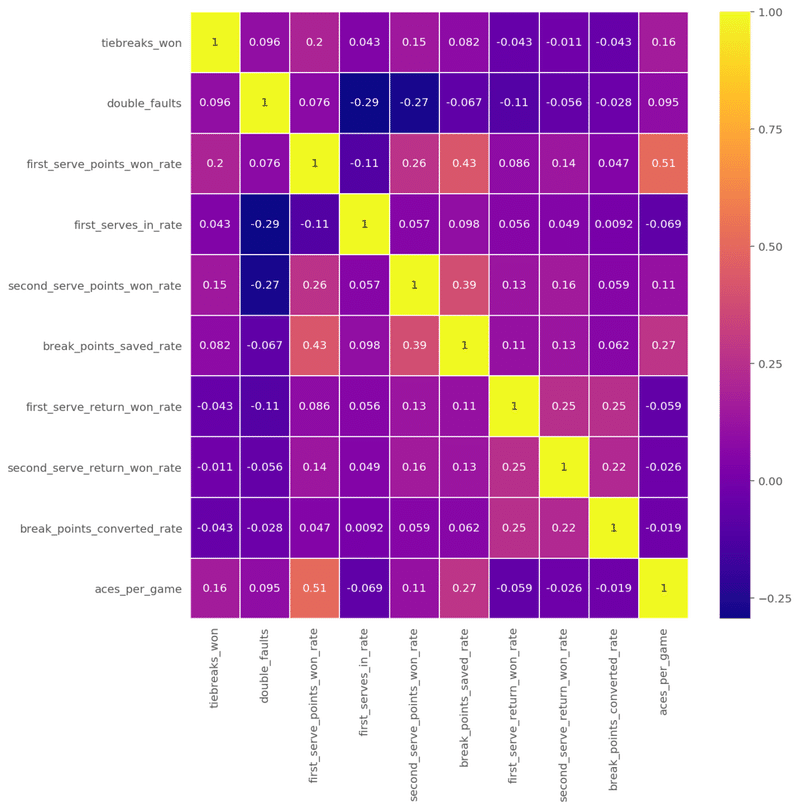
ざっとみたところ、相関係数が高いものはありませんね。(絶対値0.6以上)。なぜ0.6なのかという議論は今回は省きます。
モデルにデータを入れる前にランダムフォレストでどの変数が重要度が高いかを見ます。
feat_labels = train_x.columns
forest = RandomForestClassifier(n_estimators=500, random_state=1)
forest.fit(train_x, train_y)
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(train_x.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))
plt.title('Feature Importances')
plt.bar(range(train_x.shape[1]), importances[indices], align='center')
plt.xticks(range(train_x.shape[1]), feat_labels[indices], rotation=90)
plt.xlim([-1, train_x.shape[1]])
plt.tight_layout()
plt.show()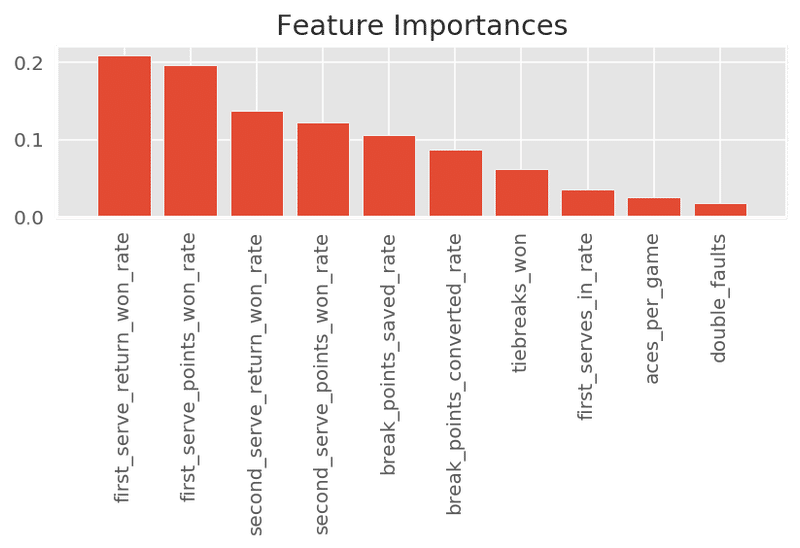
ここでもまた「first_serve_in_rate」の重要度は低いですね。
ここからが重要です。
先ほど学習データとテストデータに分割したものを標準化していきます。
sc = StandardScaler()
sc.fit(train_X)
x_train_std = sc.transform(train_X)
x_test_std = sc.transform(test_X)これでやっとモデルにデータを入れることができます。
ロジスティック回帰
# LogisticRegressionクラスのインスタンスを作成
log_model = LogisticRegression() # fit_intercept=False, C=1e9) statsmodelsの結果に似せるためのパラメータ。
# モデルを作成
result = log_model.fit(x_train_std, train_Y)
# モデルの精度を確認
log_model.score(x_train_std, train_Y)モデルの精度を確認すると
0.9291366190643153
このモデルで学習データに対して92%の説明ができました。
テストデータでも確認します。
log_model.score(x_test_std, test_Y)
0.9290894618140008
ほとんど変わりませんね。
良さそうです。
そしてモデルに対しての変数の係数を見ます。
coeff_df = DataFrame([train_x.columns, log_model.coef_[0]]).T
coeff_df.sort_values(1, ascending=False)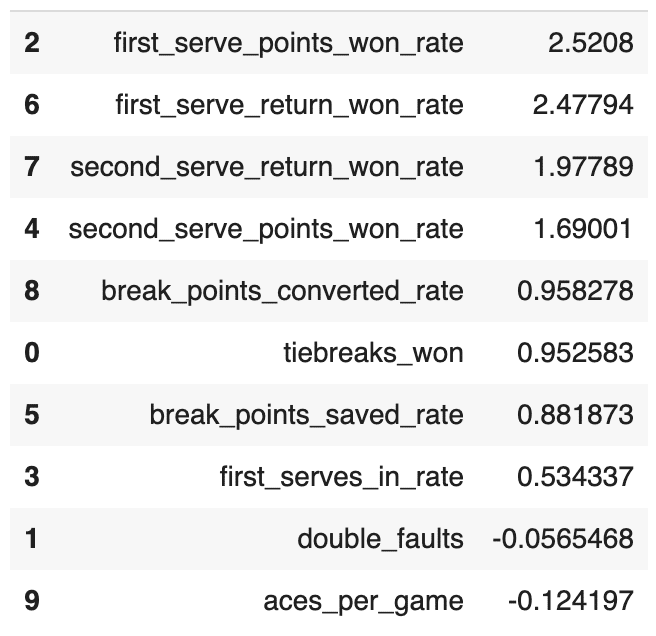
やはり『first_serve_points_won_rate』が高いんですね。つまり、ファーストサーブを入れてどれだけポイントを取得できたかということが重要です。
まとめ
今回はロジスティック回帰についてでした。
scikit-learnはかなり便利です。
それにしても変数選択と次元削減についてもっと詳しくなりたい。
この記事が気に入ったらサポートをしてみませんか?