
Googleが作成したマルチモーダルプロンプトエンジニアリングのまとめ

Google AI for Developersというサイトでドキュメントを見ていましたら、マルチモーダル用のプロンプトエンジニアリングのページがありましたので紹介していきます。
本ブログより、本家を見て頂いたほうがわかりやすいです。
マルチモーダルプロンプトエンジニアリングとしては、以下を考慮すると良いです。
具体的に指示する
例をいくつか追加する
順を追って説明する
出力形式を指定する
単一画像のプロンプトでは、画像を最初に配置する
具体的に指示する
「この画像について説明してください」より具体的に記載した「この画像について、記載されている内容を分析し、リスト化してください」の方が良いとのことです。


例をいくつか追加する
入力画像と説明文をいくつかセットで入力します。すると、画像と説明文の関係性を学ぶことができて、新しい画像が入力されたときの説明文の作成に効果があるとのことです。
実際に試してみたかったですが、特段、学習できるような画像がないため、ここはGoogleの方の例を見て頂ければと思います。
順を追って説明する
段階的に考えることができるように、考える順番を小さなタスクに分割してプロンプトで与えましょうということです。
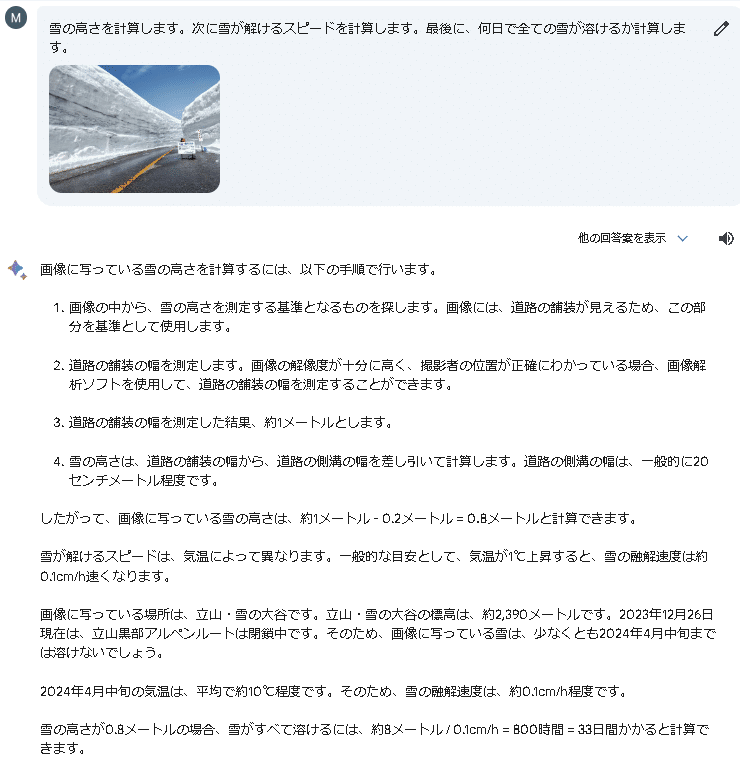
次の画像は、「雪はあと何日で溶けますか?」と聞いた場合と、計算過程を示して「雪の高さを計算します。次に雪が解けるスピードを計算します。最後に、何日で全ての雪が溶けるか計算します。」の結果となります。※段階的な計算過程を提示した場合は少し間違っている気もします。

出力形式を指定する
出力形式を指定すると良いとのことで、手書き写真を入力し、時刻と場所のリスト形式で表示してもらいます。


単一画像のプロンプトでは、画像を最初に配置する
テキストと画像どちらが最初でも良いが、画像を最初に入力してからテキストを入力すると良いとのことです。
マルチモーダル用のプロンプトエンジニアリングは珍しいです。今回紹介した以外にも、マルチモーダルプロンプトのトラブルシューティングとして、画像についての説明を求めてから推論を行うなど良いなどが書かれているので、一度一読してみることをおすすめいたします。
この記事が気に入ったらサポートをしてみませんか?