
OpenAIの音声合成APIでウェブアプリを構築する方法

以前、OpenAIがText-to-speechのAPIを出したときに記事にしたのですが、改めてどのようなAPIか見てみたく音声合成APIを使い、Streamlitでウェブアプリを構築してみました。
用意するファイルとしては、requirements.txt、app.pyです。
requirements.txtは以下です。
openai
streamlitapp.pyは以下です。your-api-keyにはOpenAIのAPIキーを記載してください。
import streamlit as st
from openai import OpenAI
# Streamlitのユーザインターフェースを設定
st.title("OpenAIの音声合成デモ")
user_input = st.text_area("テキストを入力してください", "", height=200)
# 利用可能な声のリスト
voices = ["alloy", "echo", "fable", "onyx", "nova", "shimmer"]
# ユーザーが声を選択
selected_voice = st.radio("声を選択してください", voices)
# ユーザがテキストを入力し、Enterを押したら処理を開始
if st.button('音声合成'):
if user_input:
try:
# OpenAIクライアントの初期化
client = OpenAI(api_key='your-api-key')
# 音声合成リクエストの送信
response = client.audio.speech.create(
model="tts-1",
voice=selected_voice,
input=user_input,
)
# 結果をファイルに保存
output_file = "output.mp3"
response.stream_to_file(output_file)
# ユーザに音声ファイルをダウンロードするオプションを提供
st.audio(output_file)
except Exception as e:
st.error(f"エラーが発生しました: {e}")
else:
st.warning("テキストを入力してください。")次にPython環境で以下を実行します。
pip install -r requirements.txt
streamlit run app.pyすると、次の初期画面が表示されます。
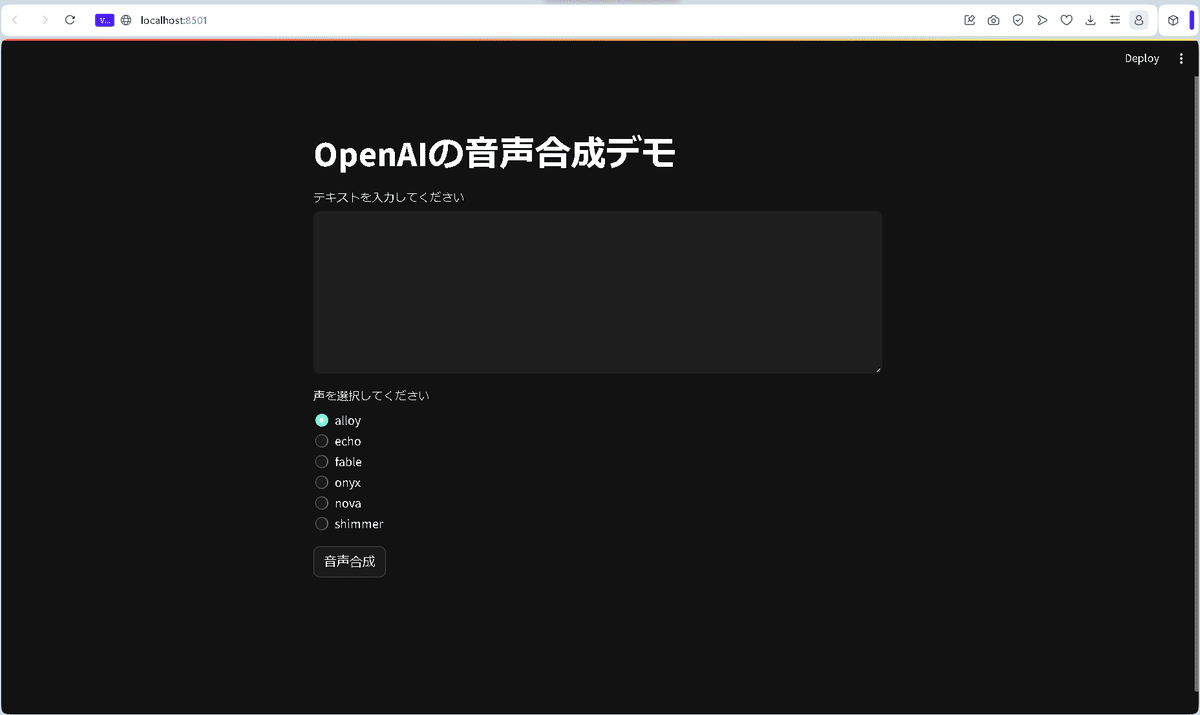
テキストを入力してくださいのところに、音声にしたい文章を入力します。
また、音声の選択のところでは、6種類の声(alloy, echo, fable, onyx, nova, shimmer)が用意されています。novaとshimmerが女性で、それ以外は男性です。
何かテキストを入力したら、音声合成ボタンを押下してみましょう。
次の画面は、音声をshimmerにして音声合成してもらっています。
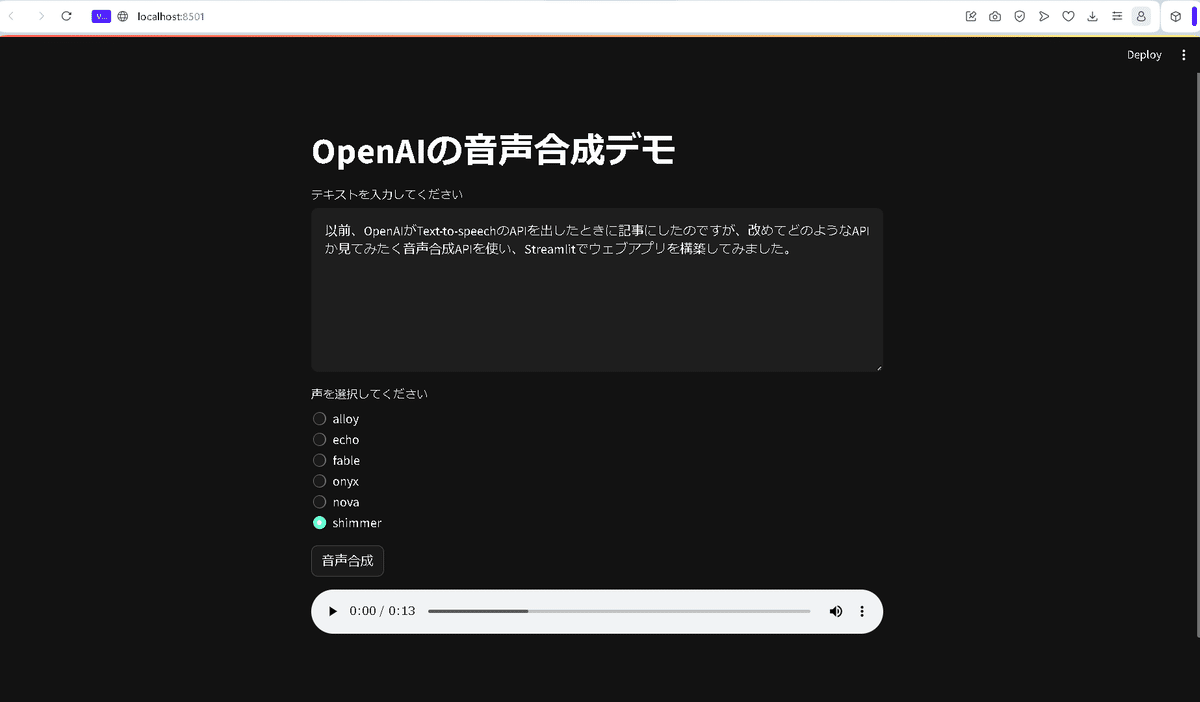
画面の下の方に、音声コントロールの矢印が出てきますので、クリックしますと、音声合成された音声が流れます。また、右側の方のボタンを押すと、音声合成した音声のダウンロードが出来たり、スピードを変えたりすることができます。
所感としては、日本人ぽい名前の人はいませんが、日本語を読んでもらうことはできます。但し、外国人が日本語を読んでいるような感じはします。また、APIの利用料として、費用がどのくらいかかるかが気になるところです。
この記事が気に入ったらサポートをしてみませんか?