GPT-4のChatGPTでPDFを取り込めるWebアプリを作成した

ChatGPTは、今年の流行語大賞になるくらいの勢いですね。今年の流行語大賞の発表時期には、昨今のAI関連のニュースの発表の多さを考えると、全く違う世界が見えているんじゃないのかなと思うとワクワクします。
今週は、ChatGPTのGPT-4の発表があり、多くの人がGPT-4を使ってどんなことができるのかを試しているはずです。だから、GPT-4関連の記事を今日は書こうかなと思いましたが、今日は、PDFを読み込ませてChatGPTに答えさせるWebアプリを作成してみようと思います。
要は、GPT Index、llama Indexみたいなことかとイメージしてもらえればと思います。
今回は、Hugging Faceより下記のページを参考に作成させていただきました。
インタフェースの流れは、OpenAIのAPIキーを入力して、PDFファイルを読み込ませて、質問をするというふうになります。
これが出来るとどうなるのかと言いますと、マニュアル類はPDFファイルが多くなっていますし、各種レポートもPDFファイルが多くなっています。それらを読み込ませて、その読み込ませたファイルの内容に関して質問をして、マニュアルに沿った回答を得られるのだと考えています。
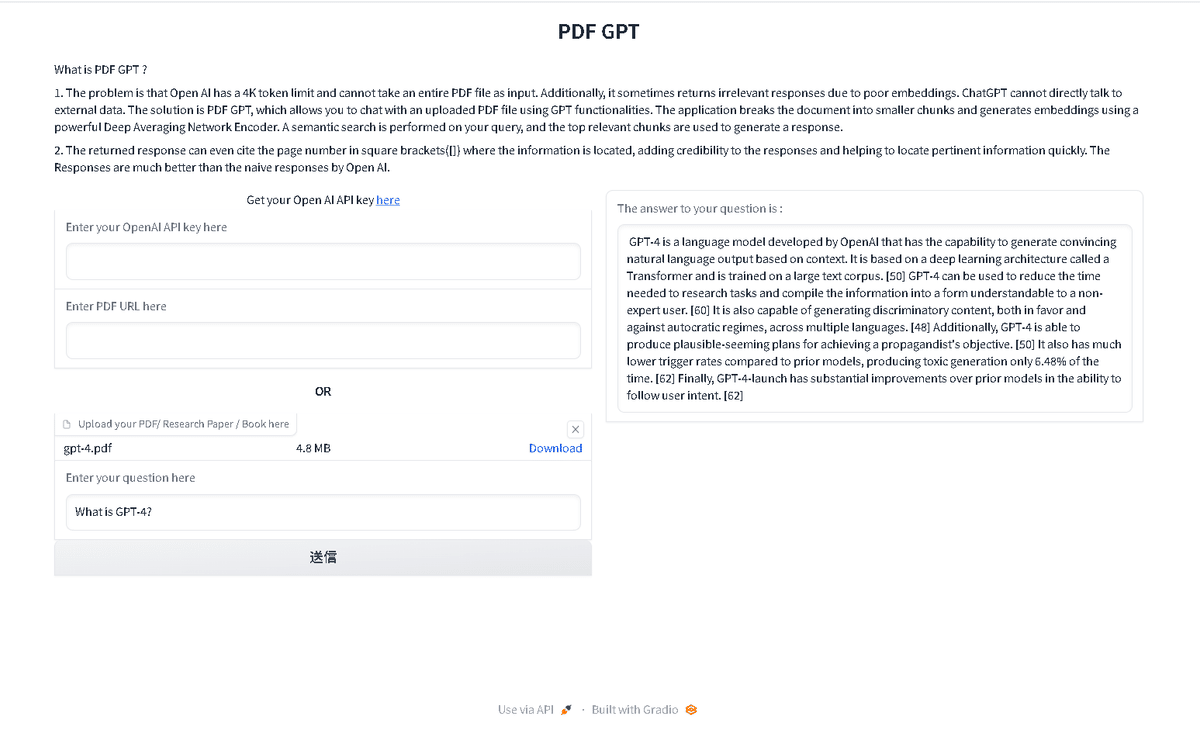
今回作成するコードから作成されるインタフェースは以下です。
Python仮想環境を構築する。
python -m venv venv
venv\Scripts\activate.bat 2.必要ファイルをインストールする
pip install gradio PyMuPDF openai tensorflow_hub scikit-learn3.app.pyを用意する。
Hugging Faceにあるapp.pyだとtext-davinci-003用なので、gpt-4用に少し修正しています。Hugging Faceのapp.pyだと、OpenAIのAPIキーはtext-davinci-003を利用していますので、gpt-turbo-3.5にしております。gpt-4でも構わないのですが、APIの料金が高いので、安いgpt-turbo-3.5にしておきます。
import urllib.request
import fitz
import re
import numpy as np
import tensorflow_hub as hub
import openai
import gradio as gr
import os
from sklearn.neighbors import NearestNeighbors
import time
def download_pdf(url, output_path):
urllib.request.urlretrieve(url, output_path)
def preprocess(text):
text = text.replace('\n', ' ')
text = re.sub('\s+', ' ', text)
return text
def pdf_to_text(path, start_page=1, end_page=None):
doc = fitz.open(path)
total_pages = doc.page_count
if end_page is None:
end_page = total_pages
text_list = []
for i in range(start_page-1, end_page):
text = doc.load_page(i).get_text("text")
text = preprocess(text)
text_list.append(text)
doc.close()
return text_list
def text_to_chunks(texts, word_length=150, start_page=1):
text_toks = [t.split(' ') for t in texts]
page_nums = []
chunks = []
for idx, words in enumerate(text_toks):
for i in range(0, len(words), word_length):
chunk = words[i:i+word_length]
if (i+word_length) > len(words) and (len(chunk) < word_length) and (
len(text_toks) != (idx+1)):
text_toks[idx+1] = chunk + text_toks[idx+1]
continue
chunk = ' '.join(chunk).strip()
chunk = f'[{idx+start_page}]' + ' ' + '"' + chunk + '"'
chunks.append(chunk)
return chunks
class SemanticSearch:
def __init__(self):
self.use = hub.load('https://tfhub.dev/google/universal-sentence-encoder/4')
self.fitted = False
def fit(self, data, batch=1000, n_neighbors=5):
self.data = data
self.embeddings = self.get_text_embedding(data, batch=batch)
n_neighbors = min(n_neighbors, len(self.embeddings))
self.nn = NearestNeighbors(n_neighbors=n_neighbors)
self.nn.fit(self.embeddings)
self.fitted = True
def __call__(self, text, return_data=True):
inp_emb = self.use([text])
neighbors = self.nn.kneighbors(inp_emb, return_distance=False)[0]
if return_data:
return [self.data[i] for i in neighbors]
else:
return neighbors
def get_text_embedding(self, texts, batch=1000):
embeddings = []
for i in range(0, len(texts), batch):
text_batch = texts[i:(i+batch)]
emb_batch = self.use(text_batch)
embeddings.append(emb_batch)
embeddings = np.vstack(embeddings)
return embeddings
def load_recommender(path, start_page=1):
global recommender
texts = pdf_to_text(path, start_page=start_page)
chunks = text_to_chunks(texts, start_page=start_page)
recommender.fit(chunks)
return 'Corpus Loaded.'
def generate_text(openAI_key,prompt, engine="gpt-3.5-turbo"):
openai.api_key = openAI_key
completions = openai.ChatCompletion.create(
model=engine,
messages=[
{"role":"system", "content":"You are helpful assistant."},
{"role":"user", "content": f"{prompt}"}
],
)
response = completions['choices'][0]['message']['content']
return response
def generate_answer(question,openAI_key):
topn_chunks = recommender(question)
prompt = ""
prompt += 'search results:\n\n'
for c in topn_chunks:
prompt += c + '\n\n'
prompt += "Instructions: Compose a comprehensive reply to the query using the search results given. "\
"Cite each reference using [number] notation (every result has this number at the beginning). "\
"Citation should be done at the end of each sentence. If the search results mention multiple subjects "\
"with the same name, create separate answers for each. Only include information found in the results and "\
"don't add any additional information. Make sure the answer is correct and don't output false content. "\
"If the text does not relate to the query, simply state 'Found Nothing'. Ignore outlier "\
"search results which has nothing to do with the question. Only answer what is asked. The "\
"answer should be short and concise.\n\nQuery: {question}\nAnswer: "
prompt += f"Query: {question}\nAnswer:"
answer = generate_text(openAI_key, prompt,"gpt-3.5-turbo")
return answer
def question_answer(url, file, question,openAI_key):
if openAI_key.strip()=='':
return '[ERROR]: Please enter you Open AI Key. Get your key here : https://platform.openai.com/account/api-keys'
if url.strip() == '' and file == None:
return '[ERROR]: Both URL and PDF is empty. Provide atleast one.'
if url.strip() != '' and file != None:
return '[ERROR]: Both URL and PDF is provided. Please provide only one (eiter URL or PDF).'
if url.strip() != '':
glob_url = url
download_pdf(glob_url, 'corpus.pdf')
load_recommender('corpus.pdf')
else:
old_file_name = file.name
file_name = file.name
file_name = file_name[:-12] + str(int(time.time())) + file_name[-4:]
os.rename(old_file_name, file_name)
load_recommender(file_name)
if question.strip() == '':
return '[ERROR]: Question field is empty'
return generate_answer(question,openAI_key)
recommender = SemanticSearch()
title = 'PDF GPT'
description = """ What is PDF GPT ?
1. The problem is that Open AI has a 4K token limit and cannot take an entire PDF file as input. Additionally, it sometimes returns irrelevant responses due to poor embeddings. ChatGPT cannot directly talk to external data. The solution is PDF GPT, which allows you to chat with an uploaded PDF file using GPT functionalities. The application breaks the document into smaller chunks and generates embeddings using a powerful Deep Averaging Network Encoder. A semantic search is performed on your query, and the top relevant chunks are used to generate a response.
2. The returned response can even cite the page number in square brackets([]) where the information is located, adding credibility to the responses and helping to locate pertinent information quickly. The Responses are much better than the naive responses by Open AI."""
with gr.Blocks() as demo:
gr.Markdown(f'<center><h1>{title}</h1></center>')
gr.Markdown(description)
with gr.Row():
with gr.Group():
gr.Markdown(f'<p style="text-align:center">Get your Open AI API key <a href="https://platform.openai.com/account/api-keys">here</a></p>')
openAI_key=gr.Textbox(label='Enter your OpenAI API key here')
url = gr.Textbox(label='Enter PDF URL here')
gr.Markdown("<center><h4>OR<h4></center>")
file = gr.File(label='Upload your PDF/ Research Paper / Book here', file_types=['.pdf'])
question = gr.Textbox(label='Enter your question here')
btn = gr.Button(value='Submit')
btn.style(full_width=True)
with gr.Group():
answer = gr.Textbox(label='The answer to your question is :')
btn.click(question_answer, inputs=[url, file, question,openAI_key], outputs=[answer])
demo.launch()
4.app.pyを実行する
python app.py
5.立ち上がった画面に、PDFファイルを読み込ませたり、OpenAIのAPIキーを入力したり、質問をしたりします。日本語はうまく対応できないようです。
まずは、下記図だとOpenAI API Keyの箇所は入力していませんが、使うときはご自身のOpenAI API Keyを入力してください。
次に、PDFファイルを取り込ませます。今回は、OpenAIのGPT-4に関する論文を利用しました。
最後に、質問を英語で入力しますと、右側に回答が出てきます。今回は、gpt-4.pdfのサマリーを下さいというふうにしましたので、右側にサマリーが表示されます。